
다국어 거대 언어 모델(LLM)은 오늘날과 같이 글로벌화된 비즈니스 환경에서 운영되는 엔터프라이즈에서 점점 더 중요해지고 있습니다. 비즈니스가 국경과 문화를 넘어 범위를 확장함에 따라 여러 언어로 효과적으로 의사 소통하는 능력은 비즈니스의 성공 여부를 결정하기도 합니다. 기업은 다국어 LLM을 지원하고 이에 투자함으로써 언어 장벽을 허물고 글로벌 시장에서 경쟁력을 확보할 수 있습니다.
파운데이션 모델은 다국어 언어를 처리할 때 종종 어려움에 직면합니다. 대체로 영어 텍스트 말뭉치로 트레이닝되었기 때문에 서구 언어 패턴과 문화적 규범에 대한 편견이 내재되어 있습니다.
이로 인해 LLM은 비서구 언어 및 사회에 특정한 뉘앙스, 숙어 및 문화적 맥락을 정확하게 포착하는 데 어려움을 겪습니다. 또한 리소스가 부족한 많은 언어를 트레이닝하기 위한 고품질 디지털화된 텍스트 데이터가 부족하면 리소스 희소성 문제가 악화되어 LLM이 이런 언어를 효과적으로 학습하고 일반화하기 어렵습니다. 결과적으로 LLM은 비서구 언어에 내재된 문화적으로 적절한 표현, 감정적 함축 및 맥락적 미묘함을 반영하지 못하고 잠재적인 오해를 불러 일으키는 편향된 출력으로 이어집니다.
최근 Meta Llama 3 블로그 게시물에서, “다국어 사용 사례에 대비하기 위해 Llama 3 사전 트레이닝 데이터 세트의 5% 이상이 30개 이상의 언어를 다루는 고품질 비영어 데이터로 구성됩니다. 하지만 이러한 언어에서는 영어와 동일한 수준의 성능을 기대하지 않습니다.”고 언급되었습니다.
이 게시물에서는 서로 다른 지역의 LoRA 조정된 어댑터 2개를 살펴보고 이를 Llama 3 NIM과 함께 배포하여 NVIDIA NIM이 중국어 및 힌디어 성능을 향상하는 법을 알아봅니다.
이러한 어댑터를 사용하면 Llama 3에 비해 언어의 정확도가 향상됩니다. 왜냐하면 중국어 및 힌디어 텍스트에서 각각 파인 튜닝되기 때문입니다. 또한 LoRA의 설계는 각 모델에 대해 더 작은 저계수 행렬에서 모든 추가 언어 정보를 캡처하는 이점을 제공합니다.
이를 통해 LoRA 조정된 각 변형에 대해 저계수 행렬 A와 B가 있는 단일 기본 모델을 로드할 수 있습니다. 이러한 방식으로 수천 개의 LLM을 저장하고 동적으로 최소한의 GPU 메모리 공간 내에서 효율적으로 실행할 수 있습니다.
튜토리얼 사전 요건
이 튜토리얼을 최대한 활용하려면 LLM 트레이닝 및 추론 파이프라인에 대한 기본 지식과 더불어 다음 사항이 필요합니다.
- Hugging Face 등록 사용자 액세스 및 트랜스포머 라이브러리에 대한 전반적인 지식.
- NVIDIA API 카탈로그의 Llama3-8B Instruct NIM. “NIM으로 어디에서나 실행”을 클릭하여 배포합니다.
NVIDIA NIM이란 무엇인가요?
NVIDIA AI Enterprise에는 엔터프라이즈의 생성형 AI 배포 속도를 높이도록 설계된 사용하기 쉬운 마이크로서비스 세트인 NVIDIA NIM이 포함되어 있습니다. NVIDIA AI 파운데이션, 커뮤니티 및 맞춤형 모델을 포함한 광범위한 AI 모델을 지원하며 업계 표준 API를 활용하여 온프레미스 또는 클라우드에서 원활하고 확장 가능한 AI 추론을 보장합니다.
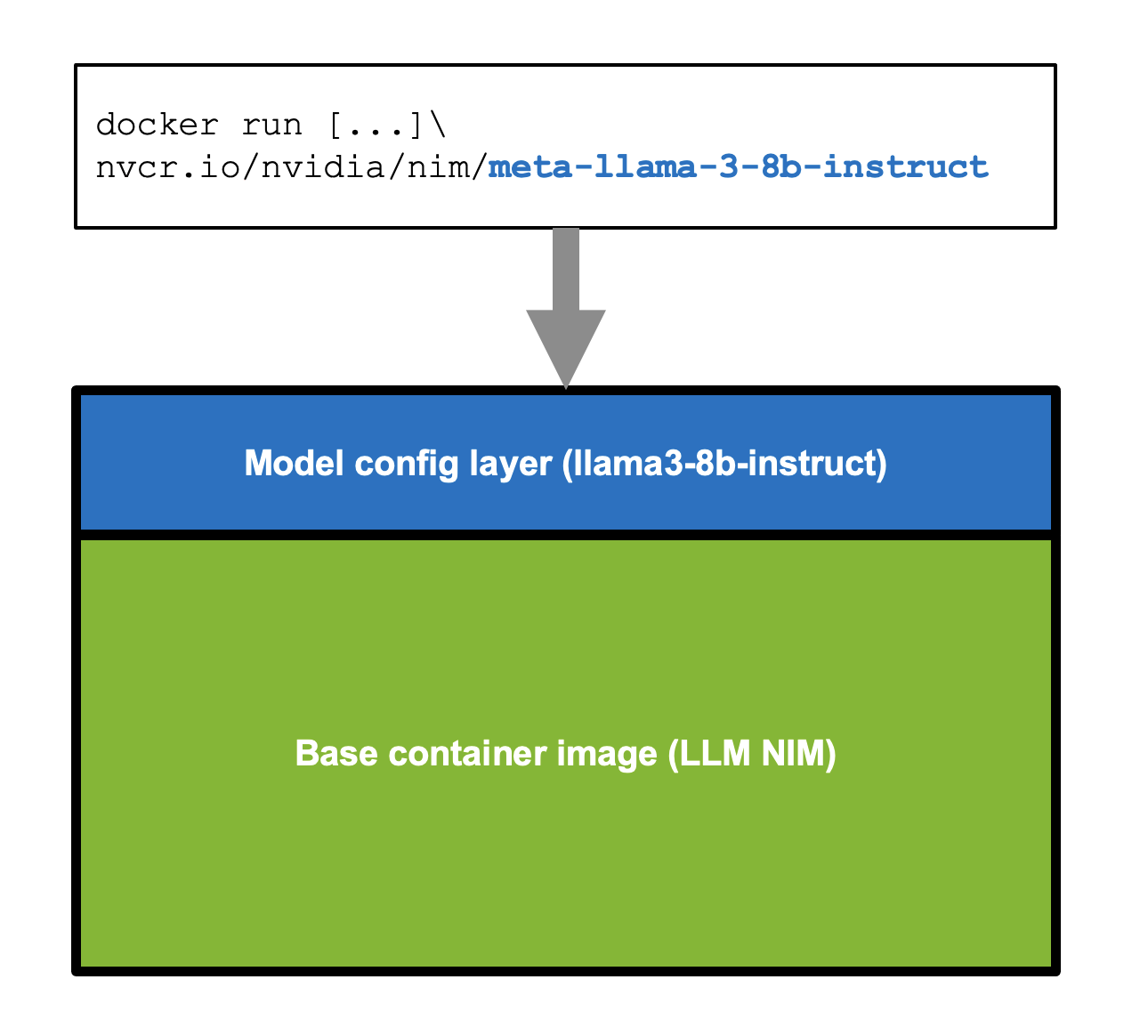
NIM은 AI 모델에서 추론을 실행하기 위한 인터랙티브 API를 제공합니다. 컨테이너 이미지는 모델 또는 모델 제품군 기반으로 패키징됩니다(그림 1 참조). 각 NIM은 모델이 있는 자체 Docker 컨테이너이며 충분한 GPU 메모리가 있는 모든 NVIDIA GPU에서 실행되는 런타임을 포함합니다. NIM은 NVIDIA H100 Tensor Core GPU, NVIDIA A100 Tensor Core GPU, NVIDIA A10 Tensor Core GPU, NVIDIA L40S GPU에 대해 최적으로 선택된 전문 가속 프로필로 NVIDIA TensorRT-LLM을 사용하여 모델을 최적화합니다.
이 블로그 게시물에서는 언어당 하나씩 여러 LoRA 모델을 동적으로 제공하여 다국어 기능으로 기본 NIM을 확장합니다.
파운데이션 LLM을 위한 기본 워크플로우
NVIDIA NIM에는 사전 구축된 LLM 세트가 있으며, 이는 쉽게 설정하고 제공할 수 있습니다. 다음 명령은 하나의 GPU를 사용하여 Llama-3-8b-instruct NIM을 제공합니다.
docker run -it --rm --name=meta-llama-3-8b-instruct \
--runtime=nvidia \
--gpus all \
-p 8000:8000 \
nvcr.io/nvidia/nim/meta-llama3-70b-instruct:1.0.0배포가 완료되면 다음 명령을 사용하여 추론을 실행할 수 있습니다.
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama-3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64,
}'다음 단계를 계속하기 전에 서버를 중지합니다.
docker stop meta-llama-3-8b-instruct맞춤 조정된 LLM을 위한 고급 워크플로우
비서구 언어의 경우 해당 언어에 대한 트레이닝 데이터가 상당히 적기때문에 파운데이션 모델이 영어와 동일한 수준의 정확도와 견고성을 보장하지 않습니다.
이 경우 LoRA와 같은 매개변수 효율적인 파인 튜닝 기술을 사용하면 이러한 언어에 대해 더 나은 성능을 발휘하도록 사전 트레이닝된 LLM을 조정할 수 있습니다.
다국어 LLM을 배포할때 수백 또는 수천 개의 조정된 모델을 효율적으로 제공해야 하는 어려움이 따릅니다. 예를 들어 Llama 2와 같은 단일 기본 LLM에는 언어 또는 로케일마다 LoRA 조정된 변형이 여러 개 있을 수 있습니다. 이 경우 표준 시스템이 모든 모델을 독립적으로 로드해야 하며 많은 메모리 용량을 차지하게 됩니다.
특히 LoRA는 모델당 더 작은 로우랭크 행렬로 모든 정보를 캡처하고, 각각의 LoRA 튜닝된 변형에 대해 로우랭크 행렬 A 및 B와 함께 단일 기본 모델을 로드하는 방식으로 모든 정보를 캡처하기 때문에 LoRA를 선택했습니다. 이러한 방식으로 수천 개의 LLM을 저장하고 최소한의 GPU 메모리 공간 내에서 동적으로 효율적으로 실행할 수 있습니다. 이 게시물에서 LoRA에 대한 이론적 배경을 살펴보세요.
NVIDIA NIM은 HuggingFace 또는 NVIDIA NeMo를 사용하여 트레이닝된 LoRA 어댑터를 지원하고, Llama 3 8B Instruct 외에 비서구 언어에 대한 더욱 강력한 지원을 추가하는 데 사용할 예정입니다. 이 블로그 게시물을 확인하여 NIM을 통한 LoRA 어댑터 배포에 대해 자세히 알아보세요.
이제 LoRA를 사용하여 여러 언어로 NIM 기능을 강화하는 방법을 소개합니다.
모델을 다운로드합니다.
1. 필요한 경우 git lfs를 설치합니다.
git lfs install2. Hugging Face의 중국어 및 힌디어 LoRa 조정된 모델을 Git에 복제합니다.
export LOCAL_PEFT_DIRECTORY=~/loras
mkdir $LOCAL_PEFT_DIRECTORY
pushd $LOCAL_PEFT_DIRECTORY
git clone https://huggingface.co/AdithyaSK/LLama3-Gaja-Hindi-8B-Instruct-alpha
git clone https://huggingface.co/shibing624/llama-3-8b-instruct-262k-chinese-lora
popd
chmod -R 777 $LOCAL_PEFT_DIRECTORYLoRA 모델 스토어 구성
LoRA 어댑터는 별도의 디렉터리, 그리고 LOCAL_PEFT_DIRECTORY 디렉터리 내의 하나 이상의 LoRA 디렉터리에 저장해야 합니다. 로드된 어댑터는 어댑터가 저장된 디렉터리의 이름을 따서 자동으로 지정됩니다. LLM용 NVIDIA NIM은 NeMo 및 HuggingFace Transformers 호환 형식을 지원합니다.
HuggingFace의 경우 LoRA에는 adapter_config.json 파일과 {adapter_model.safetensors, adapter_model.bin} 파일 중 하나가 포함되어야 합니다. NIM에 지원되는 대상 모듈은 ["gate_proj", "o_proj", "up_proj", "down_proj", "k_proj", "q_proj", "v_proj"]입니다.
LOCAL_PEFT_DIRECTORY는 아래 구조에 따라 구성되어야 합니다.
loras
├── llama-3-8b-instruct-262k-chinese-lora
│ ├── adapter_config.json
│ └── adapter_model.safetensors
└── LLama3-Gaja-Hindi-8B-Instruct-alpha
├── adapter_config.json
└── adapter_model.safetensorsNIM을 통해 여러 LoRA 모델 배포
관련 LoRA 조정된 모델을 설정한 후에는 추론을 위해 모델을 제공할 수 있습니다. 이는 기본 NIM을 실행하는 것과 유사하지만 이제 LoRA 디렉터리를 지정합니다.
export NIM_PEFT_SOURCE=/home/nvs/loras
export LOCAL_PEFT_DIRECTORY=/home/nvs/loras
export NIM_PEFT_REFRESH_INTERVAL=3600
export CONTAINER_NAME=meta-llama3-8b-instruct
export NIM_CACHE_PATH=~/nim-cache
chmod -R 777 $NIM_CACHE_PATHNIM을 사용하면 계수 크기가 서로 다른 여러 LoRA를 로드할 수 있지만 상한을 32로 설정합니다. 힌디어 LoRA의 경우 이 특정 모델이 64의 계수로 조정되었으므로 최대 계수를 기본값보다 높게 설정해야 합니다.
export NIM_MAX_LORA_RANK=64이제 LoRA를 통해 NIM을 제공합니다. 이 명령은 Llama 3 파운데이션 모델을 실행하는 것과 유사하지만 LOCAL_PEFT_DIRECTORY에 저장된 모든 LoRA 모델도 로드합니다.
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e NGC_API_KEY \
-e NIM_PEFT_SOURCE \
-e NIM_PEFT_REFRESH_INTERVAL \
-e NIM_MAX_LORA_RANK \
-v $NIM_CACHE_PATH:/opt/nim/.cache \
-v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \
-p 8000:8000 \
nvcr.io/nim/meta/llama3-8b-instruct:1.0.0제공되면 사전에 저장한 LoRA 모델에 대한 추론을 실행할 수 있습니다. 다음 명령을 사용하여 사용 가능한 LoRA NIM을 확인합니다.
url -X GET 'http://0.0.0.0:8000/v1/models'이렇게 하면 이제 추론에 사용할 수 있는 모든 LoRA 조정된 모델이 출력됩니다.
{
"Object":"list",
"Data":[
{"id":
"meta/llama3-8b-instruct","object":"model","created":1717511877,"owned_by":"system","root":"meta/llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-06017a10c1b1422cb0596baa7fec744d","object":"model_permission","created":1717511877,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]},
{"id":"llama-3-8b-instruct-262k-chinese-lora","object":"model","created":1717511877,"owned_by":"system","root":"meta/llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-ad5ce194c084490ca9f8aa5f23c4fd2f","object":"model_permission","created":1717511877,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]},
{"id":"LLama3-Gaja-Hindi-8B-Instruct-alpha","object":"model","created":1717511877,"owned_by":"system","root":"meta/llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-e11405b8a2f746f5b189de2766336eac","object":"model_permission","created":1717511877,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]},
}NIM을 통한 추론
추론을 위해 다음 cURL 명령을 사용하여 LoRA 모델의 이름을 지정합니다.
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "llama-3-8b-instruct-262k-chinese-lora",
"prompt": "介绍一下机器学习",
"max_tokens": 512
}'결과는 다음과 같습니다.
{
"Id":"cmpl-92780e47ef854328a48330d6813e8a26",
"Object":"text_completion",
"Created":1717512584,
"Model":"llama-3-8b-instruct-262k-chinese-lora",
"Choices":[
{
"Index":0,
"text":"算法的基本概念和应用场景?\n\n机器学习算法是一类用于自动处理和分析数据的算法。这些算法可以学习从数据中提取模式、关系和预测性质。在这个回答中,我们将介绍机器学习算法的基本概念和应用场景。\n\n机器学习算法的基本概念:\n\n1. 训练数据集:机器学习算法学习从数据集中获取的样本。\n2. 模型训练:算法分析训练数据集,学习模式和关系。\n3. 测试数据集:训练后的模型评估性能在新的数据集上。\n4. 训练和测试迭代:重复训练和测试步骤,以提升算法的准确性。\n\n机器学习算法的应用场景:\n\n1. 数据挖掘:机器学习算法用于发现隐藏在数据中的模式和关系。\n2. 预测和预测分析:算法用于预测未来事件、趋势和绩效。\n3. recommender systems:机器学习算法推荐产品、服务或内容,基于用户行为和偏好。\n4. 自然语言处理(NLP):机器学习算法用于理解、翻译和生成人类语言。\n5. 图像和视频处理:算法用于图像和视频分类、识别和无人机。\n\n总之,机器学习算法是自动处理和分析数据的强大工具。它们可以用于各种应用场景,包括数据挖掘、预测分析和自然语言处理。通过 sürekli 进化和改进,机器学习算法继续驱动各种 industries 和领域的创新。",
"Logprobs":null,
"Finish_reason":"stop",
"Stop_reason":null}],
"Usage":{
"Prompt_tokens":6,
"Total_tokens":370,
"completion_tokens":364}}이제 힌디어 LoRA를 시도해 보겠습니다.
curl -X 'POST' 'http://0.0.0.0:8000/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "LLama3-Gaja-Hindi-8B-Instruct-alpha",
"prompt": "मैं अपने समय प्रबंधन कौशल को कैसे सुधार सकता हूँ? मुझे पांच बिंदु बताएं और उनका वर्णन करें।",
"max_tokens": 512
}'그 결과는 다음과 같습니다.
{
"Id":"cmpl-ddf3fa6e78fc4d24b0bbbc446fb57451",
"Object":"text_completion",
"Created":1717513888,
"model":"LLama3-Gaja-Hindi-8B-Instruct-alpha",
"Choices":[
{"index":0,
"text":" मैंने पिछले साल अपनी व्यस्त भावनाओं और अव्यवस्था के बारे में बहुत सोचा है, लेकिन सच कहा, मैं अब तक कुछ तरीकों की कोशिश नहीं की हूं।\nमैंने अपनी कार्य, परिवार, और मितृत के प्रति दायित्वों के बीच लक्षित दिवस के 24 घंटे को व्याख्या नहीं की है, इस प्रकार अपने प्राथमिकताओं को परिभाषित नहीं कर पाया हूं। मैंने पिछले साल एक नया नौकरी उत्क्षेप नहीं किया, एक नया काम विशेष रूप से अपने व्यवसाय के त्वरित विकास के बिना पर था। मेरे पास घर में अधिक मुक्त समय है, लेकिन कुछ भी नहीं किया है या पूरा नहीं किया है। मैं स्वयंसेवा और उईट्रोबोल्टर के संतुलन की भी हैरानी होने लगी है, जो एक स्थायी चुनौतीपूर्ण बात है। मैं डेडलाइन के प्रचालय अभियान, सहकारियों को पकड़ना और अपनी आवश्यक वस्तुओं को प्राप्त करने के लिए बढ़ाना शुरू करूं, मेरे जीवन में अव्यवस्था के अनुकूलन में मदद मिलता है।\nमैं अपने भावनात्मक लाभों पर ध्यान केंद्रित करना चाहता हूं, मेरी अपनी जीवन शैली के घनिष्ठ होने के बावजूद। मैंने महसूस किया कि मेरे रोजमर्रा के जीवन में कई दोष थे, और कर_epsilon.org यह मदद करता है मैं मिडल एक्सिस trauma के लिए एक श्रेणी में प_registers (न्यूनतम, उच्चतम, साप",
"Logprobs":null,
"Finish_reason":"length",
"Stop_reason":null}],
"Usage":{"prompt_tokens":47,"total_tokens":559,"completion_tokens":512}
}로컬로 제공되는 NIM을 LangChain에서 사용할 수도 있습니다.
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(base_url="http://0.0.0.0:8000/v1", model="llama-3-8b-instruct-262k-chinese-lora", max_tokens=1000)
result = llm.invoke("介绍一下机器学习")
print(result.content)새로운 버전의 NIM이 출시되면 항상 최신 문서가 https://docs.nvidia.com/nim에서 제공됩니다.
결론
NVIDIA NIM을 사용하면 여러 LoRA 어댑터를 원활하게 배포 및 확장하여 개발자가 다른 언어에 대한 지원을 추가할 수 있습니다. 이 기능을 사용하면 기업은 동일한 기본 NIM을 통해 수백 개의 LoRA를 제공하여 각 언어별로 관련 LoRA 어댑터를 동적으로 선택할 수 있습니다.
NVIDIA NIM을 시작하는 방법은 간단합니다. 개발자는 NVIDIA API 카탈로그 내에서 광범위한 AI 모델에 액세스하여 AI 애플리케이션을 구축하고 배포할 수 있습니다.
그래픽 사용자 인터페이스를 사용하여 카탈로그에서 직접 프로토타입 제작을 시작하거나 무료로 API와 직접 상호 작용할 수 있습니다. 인프라에 NIM 추론 마이크로 서비스를 배포하려면 NVIDIA NIM을 통한 생성형 AI 배포를 위한 간단한 가이드를 확인하세요.
관련 리소스
- GTC 세션: NVIDIA NeMo를 통해 다양한 언어로 파운데이션 거대 언어 모델 맞춤화
- GTC 세션: 텍스트 생성을 위해 TensorRT-LLM으로 LLM 최적화 및 확장
- NGC 컨테이너: Misral-7B-Instruct-v0.3
- NGC 컨테이너: Llama3-8b-instruct
- NGC 컨테이너: Llama3-70b-instruct
- SDK: Llama3 8B Instruct NIM