
Whether you’re working on-premises or in the cloud, NVIDIA NIM microservices provide enterprise developers with easy-to-deploy optimized AI models from the community, partners, and NVIDIA. Part of NVIDIA AI Enterprise, NIM offers a secure, streamlined path forward to iterate quickly and build innovations for world-class generative AI solutions.
Using a single optimized container, you can easily deploy a NIM microservice in under 5 minutes on accelerated NVIDIA GPU systems in the cloud or data center, or on workstations and PCs. Alternatively, if you want to avoid deploying a container, you can begin prototyping your applications with NIM APIs from the NVIDIA API Catalog.
- Use prebuilt containers that deploy with a single command on NVIDIA-accelerated infrastructure anywhere.
- Maintain security and control of your data, your most valuable enterprise resource.
- Achieve best accuracy with support for models that have been fine-tuned using techniques like LoRA.
- Integrate accelerated AI inference endpoints leveraging consistent, industry-standard APIs.
- Work with the most popular generative AI application frameworks like LangChain, LlamaIndex, and Haystack.
This post walks through a few deployment options of NVIDIA NIM. You’ll be able to use NIM microservice APIs across the most popular generative AI application frameworks like Hugging Face, Haystack, LangChain, and LlamaIndex. For more information about deploying, see the NVIDIA NIM documentation.
How to deploy NIM in 5 minutes
You need either an NVIDIA AI Enterprise license or NVIDIA Developer Program membership to deploy NIM. The fastest way to get either is to visit the NVIDIA API Catalog and choose Get API key from a model page, for example, Llama 3.1 405B. Then, enter either your business email address to access NIM with a 90-day NVIDIA AI Enterprise license or your personal email address to access NIM through NVIDIA Developer Program membership.
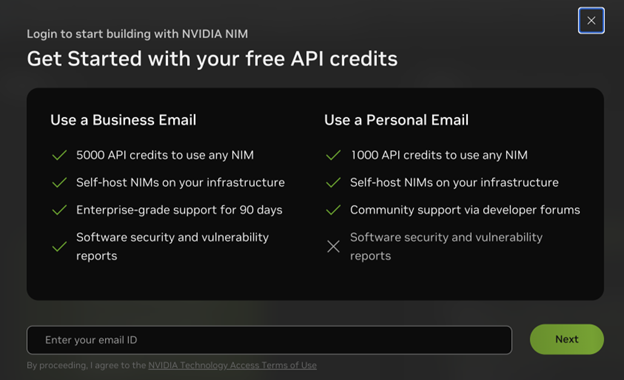
Next, make sure that you set up and follow all instructions in the prerequisites. If you copied your API key in the login flow, you can skip the step to generate an additional API key per the instructions.
When you have everything set up, run the following script:
# Choose a container name for bookkeeping
export CONTAINER_NAME=llama3-8b-instruct
# Define the vendor name for the LLM
export VENDOR_NAME=meta
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/nim/{VENDOR_NAME}/${CONTAINER_NAME}:1.0.0"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE="~/.cache/nim"
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
Next, test an inference request:
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64
}'
Now you have a controlled, optimized production deployment to securely build generative AI applications. Sample NVIDIA-hosted deployments of NIM are also available on the NVIDIA API Catalog.
As a new version of NIM is released, the most up-to-date documentation is always at NVIDIA NIM Large Language Models.
How to integrate NIM with your applications
While setup should be completed first, if you’re eager to test NIM without deploying on your own, you can do so using NVIDIA-hosted API endpoints in the NVIDIA API Catalog:
- Integrate NIM endpoints
- Integrate NIM Hugging Face endpoints
Integrate NIM endpoints
Start with a completions curl request that follows the OpenAI spec. To stream outputs, you should set stream to True. When using Python with the OpenAI library, you don’t have to provide an API key if you’re using a NIM microservice.
Make sure to update the base_url value to wherever your NIM microservice is running.
from openai import OpenAI
client = OpenAI(
base_url = "http://0.0.0.0:8000/v1",
api_key="no-key-required"
)
completion = client.chat.completions.create(
model="meta/llama3-8b-instruct",
messages=[{"role":"user","content":"What is a GPU?"}]
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
NIM is also integrated into application frameworks like Haystack, LangChain, and LlamaIndex, bringing secure, reliable, accelerated model inferencing to the developers who are already building amazing generative AI applications with these popular tools.
To use NIM microservices in Python with LangChain, use the following code example:
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(base_url="http://0.0.0.0:8000/v1", model="meta/llama3-8b-instruct", temperature=0.5, max_tokens=1024, top_p=1)
result = llm.invoke("What is a GPU?")
print(result.content)For more information about how to use NIM, see the following framework notebooks:
- Haystack RAG Pipeline with Self-Deployed AI Models and NVIDIA NIM
- LangChain RAG Agent with NVIDIA NIM
- LlamaIndex RAG Pipeline with NVIDIA NIM
Integrate NIM Hugging Face endpoints
You can also integrate a dedicated NIM endpoint directly on Hugging Face. Hugging Face spins up instances on your preferred cloud, deploys the NVIDIA-optimized model, and enables you to start inference with just a few clicks. Navigate to the model page on Hugging Face and create a dedicated endpoint directly using your preferred CSP. For more information and a step-by-step guide, see NVIDIA Collaborates with Hugging Face to Simplify Generative AI Model Deployments.
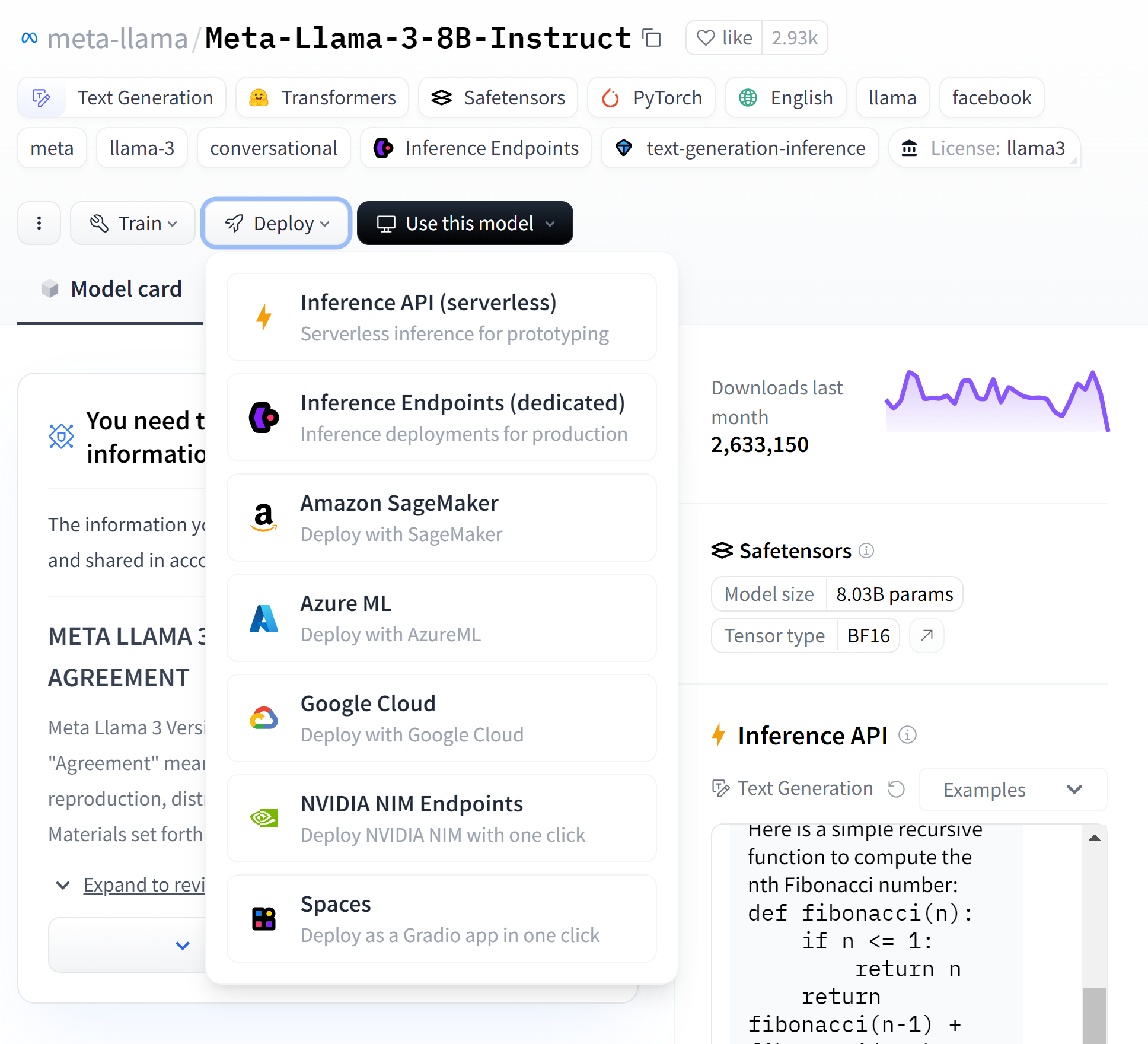
Get more from NIM
With fast, reliable, and simple model deployment using NVIDIA NIM, you can focus on building performant and innovative generative AI workflows and applications.
Customize NIM with LoRA
To get even more from NIM, learn how to use the microservices with LLMs customized with LoRA adapters. NIM supports LoRA adapters trained using either HuggingFace or NVIDIA NeMo. Store the LoRA adapters in /LOCAL_PEFT_DIRECTORY and serve using a script similar to the one used for the base container.
# Choose a container name for bookkeeping
export CONTAINER_NAME=llama3-8b-instruct
# Define the vendor name for the LLM
export VENDOR_NAME=meta
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/nim/${VENDOR_NAME}/${CONTAINER_NAME}:1.0.0"
# Choose a LLM NIM image from NGC
export LOCAL_PEFT_DIRECTORY=~/loras
# Download NeMo-format lora. You can also download HuggingFace PEFT loras
ngc registry model download-version "nim/meta/llama3-70b-instruct-lora:nemo-math-v1"
# Start the LLM NIM microservice
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
-e NGC_API_KEY \
-e NIM_PEFT_SOURCE \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
You can then deploy using the name of one of the LoRA adapters in /LOCAL_PEFT_DIRECTORY.
curl -X 'POST' \
'http://0.0.0.0:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "llama3-8b-instruct-lora_vhf-math-v1",
"prompt": "John buys 10 packs of magic cards. Each pack has 20 cards and 1/4 of those cards are uncommon. How many uncommon cards did he get?",
"max_tokens": 128
}'
For more information about LoRA, see Seamlessly Deploying a Swarm of LoRA Adapters with NVIDIA NIM.
NIM microservices are regularly released and improved. To see the latest NVIDIA NIM microservices for vision, retrieval, 3D, digital biology, and more, see the NVIDIA API Catalog.
