
PDF는 재무 보고서, 연구 논문, 기술 문서, 마케팅 자료 등 다양한 정보를 공유할 때 가장 널리 사용되는 파일 형식 중 하나입니다. 하지만 효과적인 RAG(검색 증강 생성) 시스템을 구축할 때, PDF에서 유용한 콘텐츠를 추출하는 일은 여전히 큰 과제로 남아 있습니다. 특히 차트, 테이블, 인포그래픽과 같은 복잡한 요소의 경우에는 더욱 그렇습니다. 추출된 텍스트의 정확성과 명확성은 사용자 쿼리에 대해 관련 있는 문맥을 검색기가 얼마나 잘 제공할 수 있는지를 직접적으로 좌우합니다.
이 문제를 해결하기 위해 두 가지 주요 접근 방식이 등장했습니다: OCR(광학 문자 인식) 파이프라인과 VLM(비전 언어 모델)입니다.
- 전문화된 OCR 파이프라인: NVIDIA NeMo Retriever PDF Extraction 파이프라인과 같은 시스템은 객체 감지를 통해 차트, 테이블 등 특정 요소를 식별하고, 각 요소 유형에 맞춰 최적화된 구조 인식 및 OCR 모델을 적용하는 다단계 절차를 사용합니다.
- VLM: 이 강력한 범용 AI 모델은 이미지와 텍스트를 모두 처리하고 해석할 수 있어, PDF 페이지 이미지로부터 차트나 테이블 같은 시각적 요소를 직접 “이해”하고 설명할 수 있습니다. 예를 들어, Llama 3.2 11B Vision Instruct는 이미지 기반 지시를 따르도록 파인 튜닝(fine-tuning)된 110억 파라미터 규모의 멀티모달 버전입니다.
RAG 개발자들이 자주 묻는 질문 중 하나는 언제 전문화된 멀티 모델 파이프라인을 쓰고, 언제 범용 VLM이 더 적절한 상황은 언제인지에 대한 질문입니다. 이 질문에 답하기 위해 NeMo Retriever 파이프라인과 VLM 기반 접근 방식을 비교하는 실험을 수행했으며, 주로 검색 성능을 기준으로 분석했습니다. 그 결과, 현재로서는 이 특정 검색 작업에 대해 전문화된 파이프라인이 정확성과 효율성 면에서 뚜렷한 이점을 제공한다는 사실을 확인했습니다.
이번 글에서는 두 가지 추출 전략을 비교하며, 방법론, 데이터셋, 평가 지표, 성능 수치를 자세히 다룹니다. 이를 통해 어떤 방식을 자신의 RAG 파이프라인에 적용할지, 그리고 그 이유는 무엇인지 판단할 수 있도록 도와드리겠습니다.
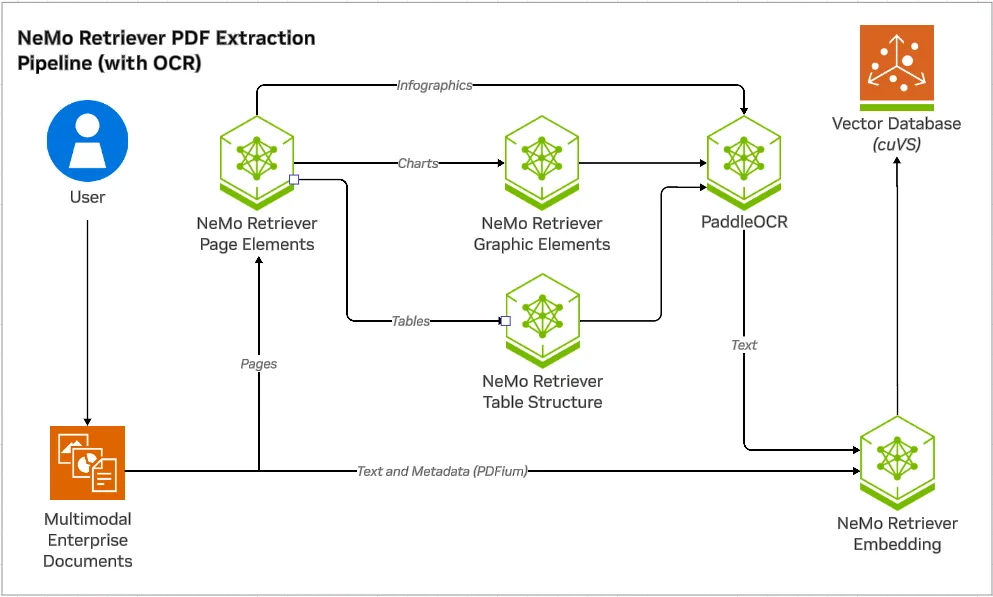
기준 접근 방식: NeMo Retriever PDF Extraction
NeMo Retriever PDF Extraction 파이프라인은 PDF에서 정보를 고정밀로 추출하도록 설계되었습니다. 이 파이프라인의 작업 흐름은 다음과 같은 단계로 구성됩니다:
- 페이지 요소 감지: 모델이 먼저 각 PDF 페이지에서 차트, 테이블, 인포그래픽의 위치를 식별합니다.
- 전문화된 추출: 감지된 각 요소는 해당 구조에 최적화된 전용 모델을 통해 처리됩니다.
- 차트: 그래픽 요소 모델과 PaddleOCR 같은 OCR을 결합해 제목, 축, 데이터 포인트, 범례를 추출합니다 (chart-to-text).
- 테이블: OCR과 함께 작동하는 테이블 구조 인식 모델을 사용해 행, 열, 셀을 정확하게 파싱하여 Markdown 형식으로 변환합니다 (table-to-text).
- 인포그래픽: 인포그래픽은 차트나 테이블보다 구조가 다양하고 덜 정형화되어 있어, 텍스트 콘텐츠만 OCR을 사용해 추출합니다 (infographic-to-text).
이와 같은 모듈형 접근 방식은 각 데이터 유형의 특성을 고려해 특화된 도구를 사용함으로써 최대한의 정확도를 달성하는 것을 목표로 합니다.
대안 접근 방식: VLM을 활용한 텍스트 추출
대안 방식에서는 그림 2에서 보듯이, 전문화된 추출 모듈들을 하나의 VLM으로 대체합니다.

이번 실험에서는 NVIDIA NIM 마이크로서비스를 통해 접근한 Llama 3.2 11B Vision Instruct 모델을 사용했으며 VLM에게 감지된 요소들을 설명하도록 프롬프트를 제공했습니다. 아래는 그 프롬프트의 예시입니다.
차트 프롬프트:
Describe the chart using the format below:
- Title: {Title}
- Axes: {Axis Titles}
- Data: {Data points}
Reply with empty text if no chart is present.테이블 프롬프트:
Describe the table using markdown format. Reply with empty text if no table is present.
Provide the raw data without explanation.인포그래픽 프롬프트:
Transcribe this infographic. Only describe visual elements if essential to understanding.
If unsure about content, don't guess.또한, 더 큰 규모의 Llama 3.2 90B Vision Instruct 모델을 테스트하여 모델 크기가 결과에 어떤 영향을 미치는지도 확인했습니다. 추론 파라미터는 temperature=0.5, top_p=0.95, max_tokens=1024로 동일하게 유지했습니다.
실험 설정
이번 실험의 핵심 목표는 각각의 접근 방식(기준 방식과 대안 방식)으로 추출한 텍스트가 후속 검색 작업을 얼마나 잘 지원하는지를 측정하는 것이었습니다.
- 데이터셋: 서로 다른 두 가지 데이터셋을 사용했습니다.
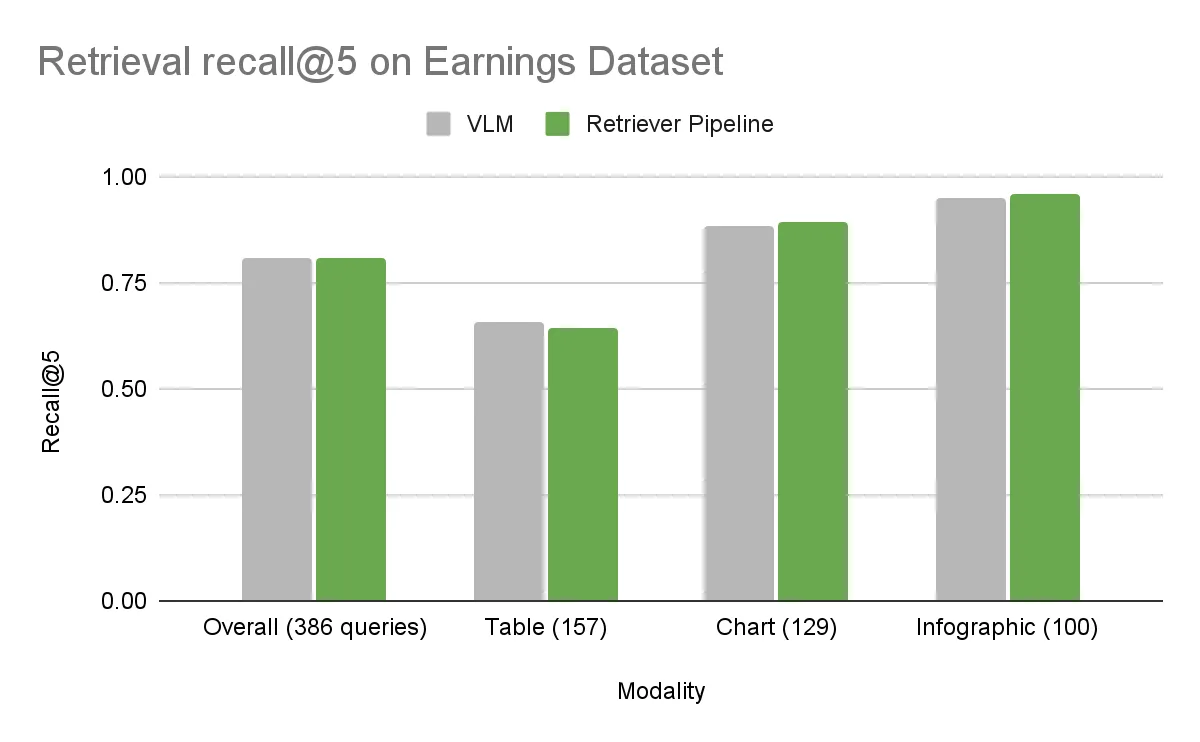
- Earnings 데이터셋: 차트, 테이블, 인포그래픽 각각 3,000건 이상을 포함한 512개의 PDF로 구성된 내부 수집 자료이며, 600개 이상의 사람이 직접 작성한 검색 질문이 포함되어 있습니다.
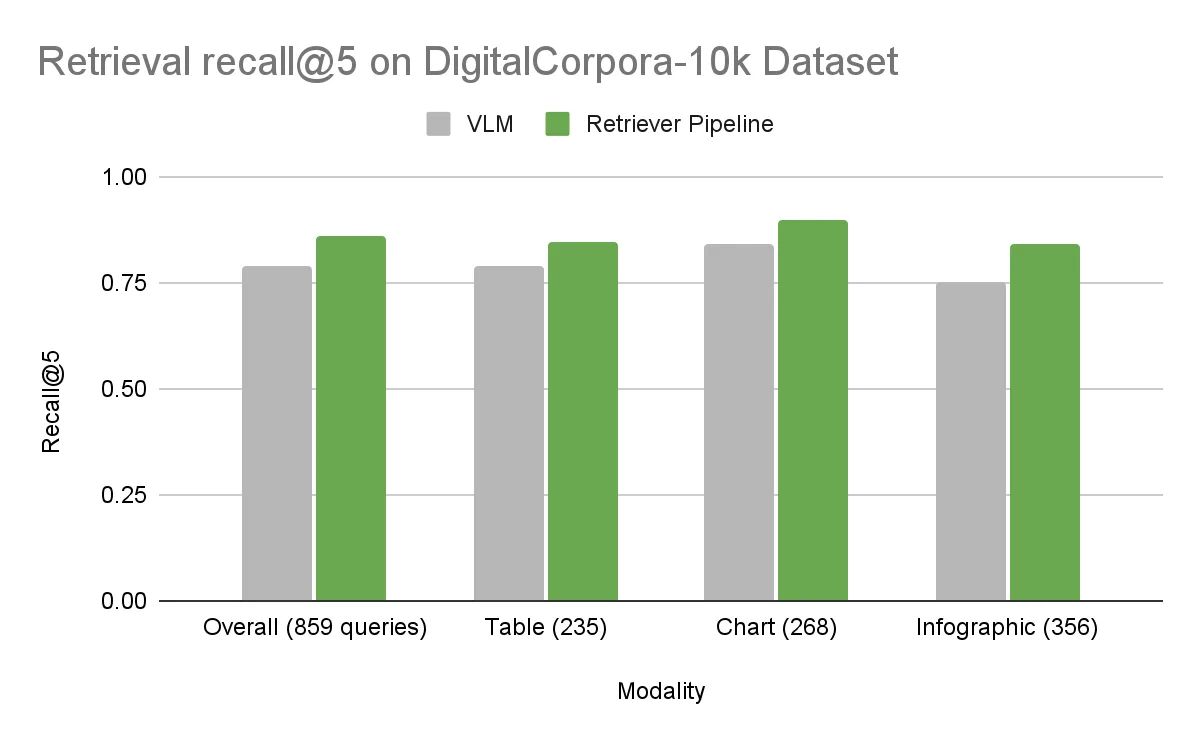
- DigitalCorpora 10K 데이터셋: Digital Corpora에서 수집한 10,000개의 PDF로 구성된 공개 벤치마크이며, 텍스트, 테이블, 차트, 인포그래픽 전반에 걸쳐 1,300개 이상의 사람이 작성한 질문이 포함되어 있습니다.
- 평가 지표: Recall@5를 사용했습니다. 이는 정답 페이지가 검색된 상위 5개 결과 안에 포함된 쿼리의 비율을 나타냅니다. 이 수치가 높을수록 추출된 텍스트 표현이 정확한 정보를 찾는 데 더 효과적이라는 뜻입니다.
- 검색기(Retriever): 텍스트 기반 검색에 대한 공정한 비교를 위해, OCR로 추출한 텍스트와 VLM이 생성한 설명 모두에 동일한 임베딩 모델(Llama 3.2 NV EmbedQA 1B v2)과 랭커(Llama 3.2 NV RerankQA 1B v2)를 사용했습니다. 어느 방법이든 상위 k개의 청크를 검색한 후에는, 필요한 경우 어떤 LLM이나 VLM도 답변 생성을 담당할 수 있습니다. 이 답변 생성 단계는 추출 단계와 독립적이므로 이번 글의 범위에는 포함되지 않습니다.
결과: 검색 정확도 비교
Earnings 데이터셋에서는 전반적인 정확도가 두 접근 방식 모두 거의 동일했습니다. 하지만 더 다양한 구성을 가진 DigitalCorpora 10K 데이터셋에서는 뚜렷한 차이가 나타났습니다. 기준 방식인 NeMo Retriever 파이프라인이 모든 시각적 요소에서 VLM을 앞섰으며, 전체 정확도 차이는 7.2%에 달했습니다.
오류 분석
DigitalCorpora 10K 데이터셋에서 발생한 오류를 분석한 결과, VLM 접근 방식에는 몇 가지 공통적인 실패 유형이 있었습니다.
잘못된 해석
VLM은 시각적 요소를 잘못 해석하는 경우가 있습니다. 예를 들어, 차트 유형(선형 vs 막대형)을 혼동하거나, 축 라벨이나 데이터 포인트를 잘못 읽거나, 차트의 핵심 메시지를 제대로 이해하지 못하는 경우입니다. 한 예시에서는 VLM이 제목을 잘못 추출하고, 선형 그래프와 막대 그래프를 혼동했으며, y축 값을 포착하지 못했습니다.
임베디드 텍스트 추출 실패
차트나 인포그래픽에 포함된 중요한 텍스트 주석, 상세한 범례, 특정 데이터 등이 VLM에 의해 누락되는 경우가 종종 있었습니다. 반면 OCR 기반 방식은 이러한 텍스트를 정확히 추출하는 데 강점을 보였습니다. 예를 들어, VLM은 한 차트에서 “2020년 승객 수 35%~65% 감소”라는 핵심 임베디드 텍스트를 추출하지 못했습니다.

환각 및 반복
일부 사례에서는 VLM이 생성한 설명에 실제로 존재하지 않는 정보(환각)가 포함되거나, 불필요하게 문구를 반복해 텍스트 표현에 잡음을 추가하는 경우가 있었습니다. 예를 들어, VLM이 실제 차트에 없는 제목인 “Rental Vacancy Trend”를 만들어내고, 도표 설명은 포착하지 못한 사례가 있었습니다.

불완전한 추출
테이블의 경우, VLM이 전체 구조를 포착하지 못하거나 일부 행/열을 누락하는 경우가 있었습니다. Earnings 데이터셋의 일부 예시에서는 테이블의 일부만 전사되기도 했습니다.
이에 비해 NeMo Retriever 파이프라인의 전문화된 모델들은 이러한 특정 구조를 처리하도록 설계되어 있으며, OCR을 통해 텍스트를 추출함으로써 검색에 더 충실하고 완전한 표현을 제공합니다.
효율성과 실용성 고려사항
정확도 외에도 실제 환경에서의 배포는 수백만 페이지를 얼마나 빠르고 비용 효율적으로 처리할 수 있는지에 달려 있습니다.
지연 시간은 새로운 문서가 검색 결과에 얼마나 빠르게 노출되는지를 좌우하며, 처리량은 필요한 머신 수와 비용에 직접적인 영향을 줍니다. 임베딩 및 재정렬 시 발생하는 토큰 수 또한 비용을 증가시킬 수 있습니다. 이를 비교하기 위해 두 파이프라인 모두에 대해 지연 시간, 페이지당 처리 속도, 토큰 사용량을 측정했습니다.
성능
두 파이프라인의 엔드 투 엔드 지연 시간과 처리량 성능은 단일 NVIDIA A100 GPU에서 벤치마크했습니다. OCR 파이프라인의 전체 지연 시간은 페이지당 0.118초로, PDF 페이지를 이미지로 변환하고, 페이지 내 요소를 감지하며, 요소에서 텍스트를 추출하는 모든 단계를 포함한 수치입니다.
반면, Llama 3.2 11B Vision Instruct VLM은 이미지당 평균 추론 시간이 차트 2.58초, 테이블 6.86초, 인포그래픽 6.60초로 나타났습니다. 전체 DigitalCorpora 10K 데이터셋의 213,000개 페이지를 기준으로, 페이지당 평균 이미지-텍스트 처리 시간은 3.81초였습니다. 참고로, 모든 페이지가 차트, 테이블, 인포그래픽을 포함하고 있는 것은 아닙니다.
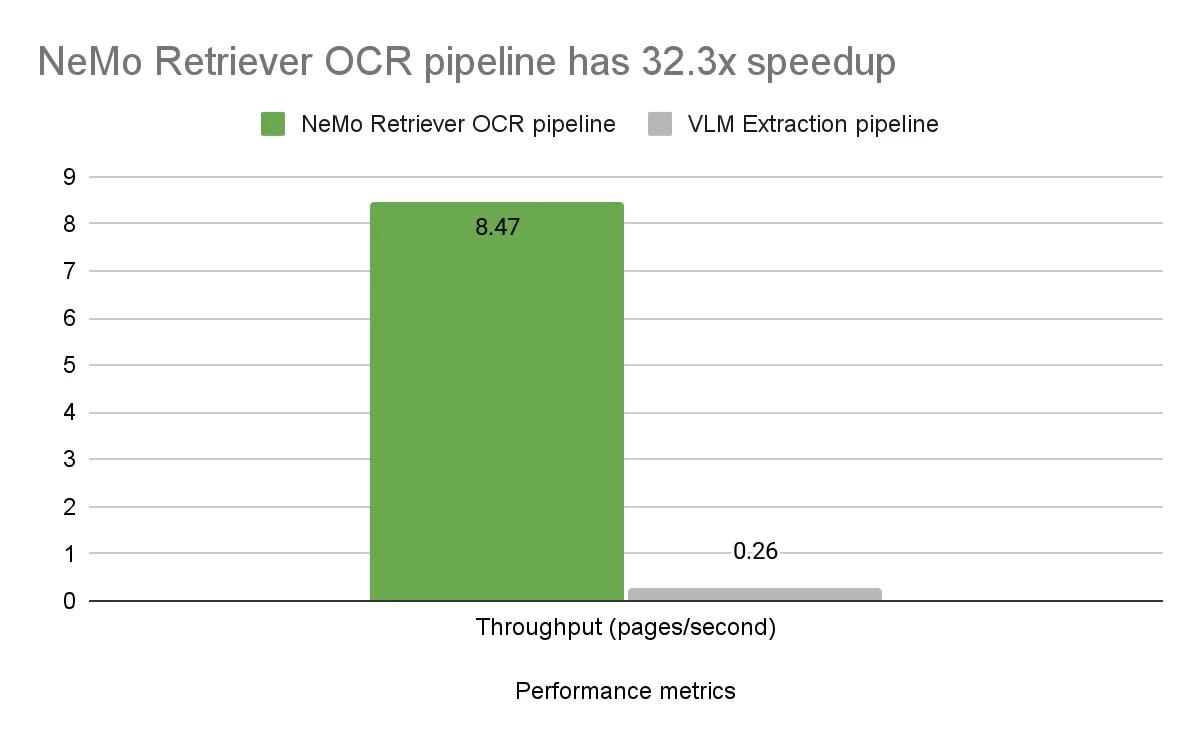
NeMo Retriever OCR 파이프라인은 상대적으로 소형 모델을 사용하면서도, 훨씬 더 높은 처리량(32.3배)과 낮은 지연 시간을 보여주며 대형 VLM 모델에 비해 우수한 효율성을 입증했습니다.
토큰 사용량
특히 인포그래픽의 경우, VLM이 생성한 설명은 OCR 기반 방식보다 훨씬 많은 토큰을 생성하는 경향이 있었습니다. VLM은 시각적 레이아웃을 서술하거나 서사적 표현을 추가하는 반면, OCR은 텍스트 내용 전사에 집중합니다. 이와 같은 장황함은 검색 단계에서 임베딩 및 선택적 재정렬 과정에서 추론 비용 증가로 이어질 수 있습니다.
일관성
VLM의 출력은 고정된 시드 값을 사용해도 비결정론적 요소로 인해 미세하게 달라질 수 있는 반면, 객체 감지 및 OCR 모델은 결정론적 특성을 지니고 있어 결과의 일관성이 높습니다.
추가 관찰 사항
다음은 몇 가지 추가적인 관찰 결과입니다.
더 큰 VLM 사용
Llama 3.2 Vision 11B 모델을 90B 버전(Llama 3.2 90B Vision Instruct)으로 대체해 테스트한 결과, 의외로 검색 리콜 성능 향상은 나타나지 않았습니다. 이는 중간 규모의 11B 모델이 이 특정 작업에 충분히 강력한 VLM이라는 사실을 보여줍니다.
프롬프트의 역할
VLM 성능은 프롬프트에 민감하게 반응하는 것으로 알려져 있습니다. 본 실험에서는 범용 프롬프트를 사용해 기본 성능을 평가했지만, 정교한 프롬프트 설계 및 모델 파인 튜닝을 통해 정확도 격차를 줄일 가능성도 있습니다. 다만, 이러한 접근은 처리량 격차를 해소하지는 못합니다.
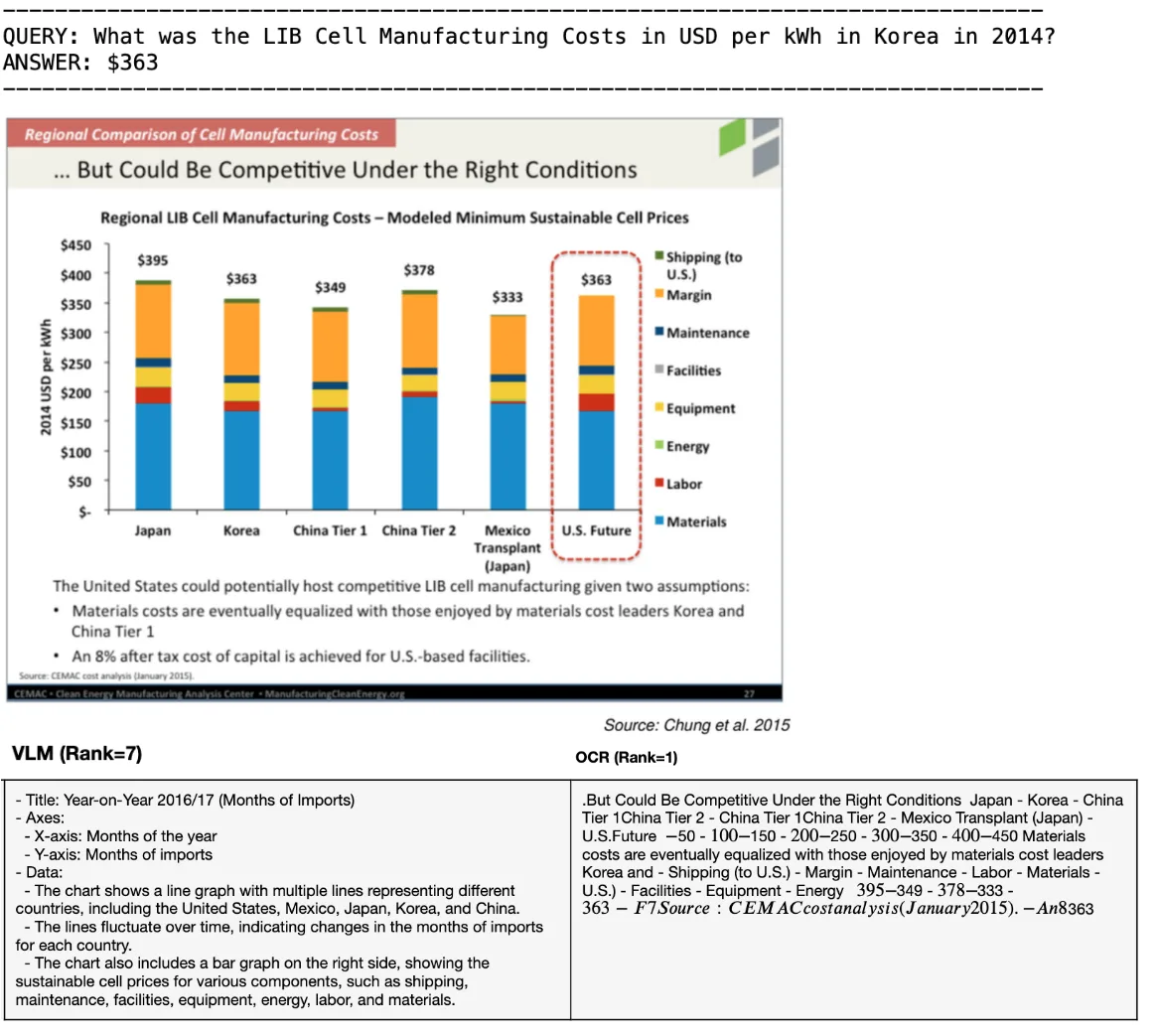
OCR의 한계
향후 주목할 만한 영역 중 하나는 OCR 방식이 한계를 보이는 시나리오입니다. 특히 명시적인 텍스트가 없는 정보 추출(예: 수치 라벨이 없는 막대그래프에서 막대 높이 읽기)에서 그러합니다. 예비 실험에서 OCR과 텍스트 기반 LLM(Llama 3.1 Nemotron 70B Instruct)은 올바른 페이지는 검색했지만 정답을 생성하지 못했습니다.
반면, 유사한 규모의 VLM(Llama 3.2 90B Vision Instruct)은 시각 입력만으로 정답을 직접 도출했습니다. 이는 VLM이 가진 고유한 장점을 보여주는 사례이며, 향후에는 OCR과 VLM 방식의 상호 보완적인 강점을 다중모달 생성 작업에 대해 체계적으로 평가하는 연구가 필요합니다.

결론
저희는 복잡한 PDF 요소(차트, 테이블, 인포그래픽)로부터 정보를 추출하여 텍스트 기반 검색에 활용하는 두 가지 접근 방식을 비교했습니다:
- 전문화된 OCR 기반 접근: NVIDIA NeMo Retriever PDF Extraction 파이프라인
- 범용 VLM 기반 접근: Llama 3.2 11B Vision Instruct 사용
두 방법 모두를 검색 파이프라인의 일부로 벤치마크했습니다. VLM은 PDF-to-text 추출을 위해 특별히 설계되지 않았지만, 추가적인 파인 튜닝 없이도 문서 파싱에서 유망한 능력을 보였습니다. 그러나 OCR 기반의 NeMo Retriever 파이프라인은 테스트된 데이터셋에서 더 높은 검색 리콜을 기록했으며, 처리량, 속도, 추론 효율성 측면에서도 강력한 성능 우위를 보였습니다.
NVIDIA는 NIM 마이크로서비스를 통해 전문화된 추출 작업을 위한 고도로 최적화된 모델과 강력한 범용 VLM을 모두 제공하여, 사용자가 특정 요구에 맞는 최적의 접근 방식을 선택할 수 있도록 지원합니다. 또한, 전문화된 추출 모델과 VLM 모두 빠르게 진화하고 있어, 문서 이해 기술의 전반적인 지형도 지속적으로 변화할 것입니다.
이번 분석은 RAG 파이프라인 중 검색 단계에 초점을 맞췄으며, 현재는 OCR 방식이 뚜렷한 이점을 보이고 있습니다. 하지만 복잡한 시각 콘텐츠로부터 직접 답변을 생성하는 등, VLM이 고유한 강점을 발휘할 수 있는 보완적 사용 사례도 존재합니다. 이러한 VLM의 보완적 강점은 향후 포스트에서 다룰 예정입니다.
NVIDIA RAG Blueprint로 시작하세요
이 글에서 다룬 PDF 추출 전략을 최적화하고 싶으신가요? NVIDIA AI Blueprint for RAG는 기초적인 RAG 파이프라인을 위한 참조 솔루션으로, 다음 기능을 제공합니다:
- 데이터셋을 활용한 다양한 PDF 추출 방식 실험
- 최첨단 임베딩 및 임베딩 재정렬 모델 활용
- 최소한의 개발 시간으로 프로덕션 수준의 PDF 추출 파이프라인 구축
관련 자료
- DLI 강의: Transformer 기반 자연어 처리 구축
- DLI 강의: 산업용 검사용 딥러닝
- GTC 세션: 생성형 AI와 RAG로 엔터프라이즈 데이터 플랫폼 혁신하기
- GTC 세션: PDFSpeak – 음성을 통한 멀티모달 PDF 인텔리전스 구현
- GTC 세션: SAP 문서 그라운딩 강화하기
- NGC 컨테이너: MATLAB




