
이제 RAPIDS Accelerator for Apache Spark v21.10을 사용하실 수 있습니다! 오픈 소스 프로젝트로서, NVIDIA는 커뮤니티의 목소리, 그리고 요청을 중요시하며 이 버전은 GPU 가속화에 대한 커뮤니티의 요청을 수렴하여 시행되었습니다.
이 버전의 주요 마크업:
- Speed up – 성능 향상 및 비용 절감
- New Functionality – 새로운 I/O 및 중첩된 데이터 유형 확인 및 분석 도구 기능
- Community Updates – spark-examples repository 업데이트.
Speed up
RAPIDS Accelerator for Apache Spark는 기능과 성능 면에서 빠른 속도로 성장하고 있습니다. 표준 산업 벤치마크는 일정 기간 동안의 성능을 측정하는 좋은 방법이지만, 성능을 측정하는 또 다른 바로미터는 데이터 전처리 단계나 데이터 분석에 사용되는 공통 연산자의 성능을 측정하는 것입니다.
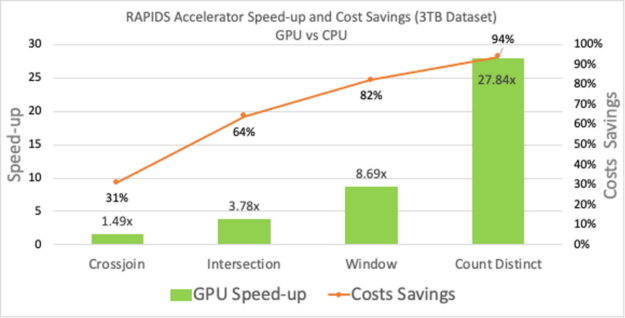
아래 차트에 표시된 네 가지 쿼리가 사용되었습니다.
- Count Distinct : 전자 상거래 사이트를 방문한 고유 페이지 뷰 또는 고유 고객의 수를 계산하는 데 사용되는 기능입니다.
- Window: 마케팅 또는 금융 산업에서 타임스탬프가 찍힌 이벤트 데이터를 분석하는 데 필요한 구성요소를 사전 처리하는 데 필요한 중요한 연산자입니다.
- Intersect: 데이터 프레임에서 중복 항목을 제거하는 연산자입니다.
- Cross-join: 크로스오버의 일반적인 용도는 프로젝트의 모든 조합을 가져오는 것입니다.
이 쿼리는 각각 104GB RAM을 장착한 2xT4 GPU를 장착한 구글 클라우드 플랫폼(GCP) 기기에서 실행됩니다. 사용된 데이터 세트의 크기는 3TB이며 여러 데이터 유형이 있습니다. 설정 및 쿼리에 대한 자세한 내용은 GitHub의 spark-rapids-examples 저장소에서 확인하실 수 있습니다. 이 4개의 쿼리는 성능과 비용상의 이점뿐만 아니라 컴퓨팅 강도에 따라 속도 향상 범위(27배~1.5배)도 달라진다는 것을 보여줍니다. 이러한 쿼리는 데이터 사전 처리의 실제 사용 사례와 유사하며 계산 및 네트워크 활용도가 다양합니다.
새로운 기능
플러그인
대부분의 Apache Spark 사용자들은 Spark 3.2가 올해 10월에 발표되었다는 것을 알고 있습니다. v2.10 릴리즈는 Spark 3.2 및 CUDA 11.4를 지원합니다. 이번 릴리즈에서는 I/O, 중첩 데이터 처리 및 머신 러닝 기능에 대한 지원확대에 초점을 맞추었습니다. RAPIDS Accelerator for Apache Spark v21.10은 스파크의 머신러닝을 지원하기 위해 새로운 플러그인 jar을 발표했습니다.
현재 이 jar는 주성분 분석 알고리즘의 교육을 지원합니다. ETL jar은 Parquet 및 ORC에 대한 입력 형식 지원을 확장했습니다. 또한 중첩된 데이터에 대해 HashAggregate, Sort, JoinSHJ과 Join BHJ를 사용할 수 있는 기능을 사용자에게 제공합니다. 중첩된 데이터 유형에 대한 지원 외에도 성능 테스트도 함께 실행되었습니다.
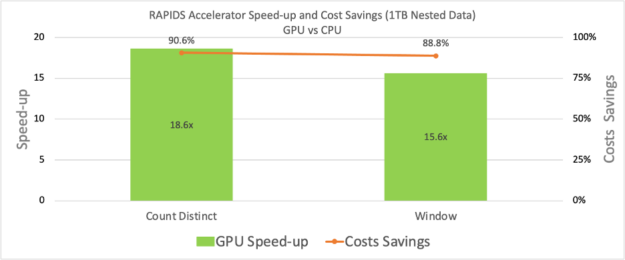
아래 그림에서는 중첩된 데이터 유형 입력을 사용하여 두 쿼리에 대해 속도 상승이 관찰됨을 확인할 수 있습니다. v21.10에 추가된 다른 흥미로운 기능으로는 pos_explode, create_map 등이 있습니다. 새로운 기능에 대한 자세한 목록은 RAPIDS Accelerator for Apache Spark 설명서를 참조하세요.
분석 및 검증 툴
플러그인 외에도 RAPIDS Accelerator for Apache Spark의 분석 및 검증 툴에 여러 새로운 기능이 추가되었습니다. 이제 검증 툴을 통해 중첩된 여러 데이터 유형과 쓰기 데이터 형식을 보고할 수 있습니다. 또한 결합 및 분리 필터, 필터 기반 정규 표현식과 사용자 이름을 추가할 수 있습니다.
이제 분석 툴은 구조화된 출력 형식과 다수의 이벤트 로그를 확장하고 실행할 수 있는 지원을 제공합니다.
커뮤니티 업데이트
Azure의 공개 프리뷰가 발표되었습니다. Azure 사용자들을 위해 Azure Synapse에서 RAPIDS Accelerated for Apache Spark 사용을 추천드립니다.
지난 2021년 11월 8일부터 11일까지 개최된 엔비디아의 대표 행사인 GTC를 통해 AI가 어떻게 세상을 변화시키고 있는지 확인해 보세요. RAPIDS Accelerator 팀은 두 가지 세션를 진행했는데, Accelerated Apache Spark에서는 새로운 기능과 추후 출시될 기능에 대해 간략하게 설명합니다. 또한 RAPIDS 및 NVIDIA GPU가 포함된 Discover Common Apache Spark Operations Turbocharge는 Apache Spark의 많은 마이크로벤치마크에 대한 내용을 포함하고 있습니다.
Coming soon
곧 발표될 버전들은 128비트 10진 데이터 형식에 대한 지원, 원리 구성요소 분석 알고리즘에 대한 추론 지원, 다중 구조와 맵에 대한 추가적인 중첩 데이터 타입 지원을 포함합니다.
또한 A100으로 여러 개의 스파크 작업을 실행하는 데 필요한 처리량을 개선할 수 있는 NVIDIA Ampere Architecture 기반 GPU(A100/A30)에 대한 MIG 지원을 확인해 보세요. 언제나처럼 Apache Spark용 RAPIDS Accelerator를 사용해 주신 여러분 모두에게 감사드리며, 귀하의 답변을 기다리겠습니다. GitHub에 문의하여 Apache Spark에서 RAPIDS Accelerator를 사용하며 귀하의 경험을 지속적으로 개선할 수 있는 방법을 알려주세요.