딥 러닝은 산업이 제품 및 서비스를 제공하는 방식을 혁신하고 있습니다. 이러한 서비스에는 컴퓨터 비전을 위한 개체 감지, 분류 및 세분화, 언어 기반 애플리케이션의 텍스트 추출, 분류 및 요약이 포함됩니다. 이러한 애플리케이션은 실시간으로 실행되어야 합니다.
대부분의 모델은 더 넓은 동적 범위를 활용하기 위해 부동 소수점 32비트 산술로 학습됩니다. 그러나 추론에서 이러한 모델은 감소된 정밀 추론에 비해 결과를 예측하는 데 더 긴 시간이 소요되어 실시간 응답이 다소 지연되고 사용자 경험에 영향을 미칠 수 있습니다.
많은 경우 줄어든 감소된 정밀도 또는 8비트 정수 사용이 더 좋습니다. 문제는 학습 후 가중치를 반올림하기만 하면, 특히 가중치의 동적 범위가 넓은 경우 정확도가 낮아질 수 있다는 것입니다. 이 게시물은 QAT(양자화 인식 학습)에 대한 간단한 소개와 학습 중에 가짜 양자화를 구현하고 NVIDIA TensorRT 8.0으로 추론을 수행하는 방법을 제공합니다.
개요
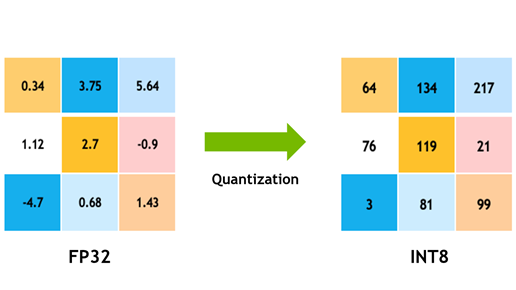
모델 양자화는 일반적으로 8비트 정수를 사용하여 네트워크 매개변수와 활성화 모두의 모델 데이터가 부동 소수점 표현에서 저정밀도 표현으로 변환되는 인기 있는 딥 러닝 최적화 방법입니다. 여기에는 다음과 같은 여러 가지 이점이 있습니다.
- 8비트 정수 데이터를 처리할 때 NVIDIA GPU는 더 빠르고 저렴한 8비트 Tensor 코어를 사용하여 합성곱 및 행렬 곱셈 연산 작업을 계산합니다. 이렇게 하면 더 많은 컴퓨팅 처리량이 산출되며 이는 컴퓨팅 제한 계층에서 특히 효과적입니다.
- 데이터를 메모리에서 컴퓨팅 요소(NVIDIA GPU의 멀티프로세서 스트리밍)로 이동하려면 시간과 에너지가 필요하며 열도 발생합니다.활성화 및 매개변수 데이터의 정밀도를 32비트 부동에서 8비트 정수로 줄이면 데이터가 4배 감소하여 전력이 절약되고 생성되는 열이 줄어듭니다.
- 일부 계층은 대역폭 바운드입니다(메모리 한정). 즉, 이 구현은 데이터를 읽고 작성하는 데 대부분의 시간을 소비하므로 계산 시간을 낮춰도 전체 런타임을 줄이지 못합니다. 대역폭 바운드 레이어는 감소된 대역폭 요구 사항에서 가장 큰 이점을 얻습니다.
- 메모리 점유율이 줄어들면 모델에 스토리지 공간이 적고, 매개변수 업데이트가 더 적고, 캐시 사용률이 더 높아지는 등의 효과가 있습니다.
양자화 방법
양자화는 많은 이점을 제공하지만 매개변수와 데이터의 정밀도가 감소하면 모델의 작업 정확도를 쉽게 해칠 수 있습니다. 32비트 부동 소수점은 [-3.4e38, 3.40e38] 간격으로 약 40억 개의 숫자를 나타낸다는 점을 고려하십시오. 이 표현 가능한 숫자 간격은 동적 범위라고도 합니다. 인접한 두 개의 표현 가능 숫자 사이의 거리는 표현의 정밀도입니다.
부동 소수점 숫자는 동적 범위에서 비균등하게 분산되며, 표현 가능한 부동 소수점 숫자의 약 절반은 [-1,1] 간격에 있습니다. 즉, [-1, 1] 간격의 표현 가능한 숫자는 [1, 2]의 숫자보다 더 높은 정밀도를 갖습니다. [-1, 1]의 표현 가능한 32비트 부동 소수점 숫자의 고밀도는 매개변수와 데이터가 분포 질량의 대부분을 0 주변에 갖는 딥 러닝 모델에 유용합니다.
그러나 8비트 정수 표현을 사용하면 28개의 값만 나타낼 수 있습니다. 이러한 256개의 값은 예를 들어 0을 중심으로 더 높은 정밀도를 위해 균일하거나 불균일하게 분포될 수 있습니다. 모든 주류 딥 러닝 하드웨어 및 소프트웨어는 고처리량 병렬 또는 벡터화된 정수 수학 파이프라인을 사용한 컴퓨팅을 지원하므로 균일한 표현을 사용하기로 선택했습니다.
부동 소수점 텐서(![]() )의 표현을 8비트 표현(
)의 표현을 8비트 표현(![]() )으로 변환하기 위해, 스케일 팩터가 부동 소수점 Tensor의 동적 범위를 [-128, 127]로 매핑하는 데 사용됩니다.
)으로 변환하기 위해, 스케일 팩터가 부동 소수점 Tensor의 동적 범위를 [-128, 127]로 매핑하는 데 사용됩니다.

동적 범위는 원점에 대칭이므로 이는 대칭 양자화입니다. ![]() 는 유리수를 정수로 반올림하는 반올림 정책을 적용하는 함수이며
는 유리수를 정수로 반올림하는 반올림 정책을 적용하는 함수이며 ![]() 은 [-128, 127] 간격 밖의 이상치를 클립하는 함수입니다. TensorRT는 활성화 데이터와 모델 가중치를 모두 나타내는 대칭 양자화를 사용합니다.
은 [-128, 127] 간격 밖의 이상치를 클립하는 함수입니다. TensorRT는 활성화 데이터와 모델 가중치를 모두 나타내는 대칭 양자화를 사용합니다.
그림 1의 상단에는 요소 분포의 히스토그램으로 묘사된 임의 부동 소수점 텐서 ![]() 의 다이어그램이 있습니다. NVIDIA는 양자화된 텐서(
의 다이어그램이 있습니다. NVIDIA는 양자화된 텐서(![]() ,
, ![]() ])에 표시할 계수의 대칭 범위를 선택했습니다. 여기서
])에 표시할 계수의 대칭 범위를 선택했습니다. 여기서 ![]() 는 표현해야 할 가장 큰 절대 가치를 지닌 요소입니다. 양자화 규모를 계산하려면 부동 소수점 동적 범위를 256개의 동일한 부분으로 나눕니다.
는 표현해야 할 가장 큰 절대 가치를 지닌 요소입니다. 양자화 규모를 계산하려면 부동 소수점 동적 범위를 256개의 동일한 부분으로 나눕니다.


규모를 계산하기 위해 여기에 표시된 메서드 부호가 있는 8 비트 정수로 표시할 수 있는 전체 범위 [-128, 127]을 사용합니다. TensorRT 명시적 정밀도(Q/DQ) 네트워크는 가중치와 활성화를 양자화할 때 이 범위를 사용합니다.
정수 8비트를 사용하여 표현하도록 선택된 동적 범위와 반올림 작업에서 도입한 오류 사이에는 긴장이 있습니다. 동적 범위가 크면 원래 부동 소수점 텐서에서 더 많은 값이 양자화된 텐서로 표현되지만, 이는 더 낮은 정밀도를 사용하고 더 큰 반올림 오류를 일으킨다는 의미이기도 합니다.
더 작은 동적 범위를 선택하면 반올림 오류가 줄어들지만 클리핑 오류가 발생합니다. 동적 범위 밖에 있는 부동 소수점 값은 동적 범위의 최소/최대 값으로 클리핑됩니다.
 의 부호가 있는 8비트 정수 양자화. x_{f}의 [-amax, amax] 는 양자화를 통해 [-128, 127]로 매핑됩니다.
의 부호가 있는 8비트 정수 양자화. x_{f}의 [-amax, amax] 는 양자화를 통해 [-128, 127]로 매핑됩니다.정밀도 손실이 작업 정확도에 미치는 영향을 해결하기 위해 다양한 양자화 기법을 개발했습니다. 이러한 기술은 두 가지 범주 중 하나인 학습 후 양자화(PTQ) 또는 양자화 인식 학습(QAT) 중 하나에 속하는 것으로 분류할 수 있습니다.
이름에서 알 수 있듯이 고정밀 모델을 학습시킨 후 PTQ가 수행됩니다. PTQ를 사용하면 가중치를 쉽게 양자화할 수 있습니다. 가중치 텐서에 액세스할 수 있고 그 분포를 측정할 수 있습니다. 활성화 분포는 실제 입력 데이터를 사용하여 측정해야 하기 때문에 활성화의 양자화는 더 어렵습니다.
이를 위해 학습된 부동 소수점 모델은 작업의 실제 입력 데이터를 대표하는 작은 데이터세트를 사용하여 평가되며 인터레이어 활성화 분포에 대한 통계가 수집됩니다. 마지막 단계에서는 모델의 활성화 텐서의 양자화 스케일이 여러 최적화 목표 중 하나를 사용하여 결정됩니다. 이 프로세스는 보정이며 사용되는 대표적인 데이터세트는 보정 데이터세트입니다.
PTQ가 허용되는 작업 정확도를 달성하지 못하는 경우가 있습니다. 이때 QAT 사용을 고려할 수 있습니다. QAT의 아이디어는 간단합니다. 학습 단계에 양자화 오류가 포함된 경우 양자화된 모델의 정확도를 개선할 수 있습니다. 네트워크가 양자화된 가중치 및 활성화에 적응할 수 있도록 해줍니다.
학습되지 않은 모델로 시작하는 것부터 사전 학습된 모델로 시작하는 것까지 QAT를 수행하는 다양한 레시피가 있습니다. 모든 레시피는 데이터 및 매개변수의 양자화를 시뮬레이션하기 위해 학습 그래프에 가짜 양자화 연산을 삽입하여 학습 손실에 양자화 오류를 포함하도록 학습 방식을 변경합니다. 이러한 작업은 데이터를 양자화하기 때문에 ‘가짜’라고 불리지만, 즉시 데이터를 양자화 해제하여 작업의 컴퓨팅이 부동 소수점 정밀도로 유지되도록 합니다. 이 요령은 딥 러닝 프레임워크에서 많은 것을 바꾸지 않고 양자화 노이즈를 더합니다.
포워드 패스에서는 부동 소수점 가중치와 활성화를 가짜로 양자화하고 이러한 가짜 양자화된 가중치와 활성화를 사용하여 레이어 작업을 수행합니다.백워드 패스에서는 가중치의 그라데이션을 사용하여 부동 소수점 가중치를 업데이트합니다. 정의되지 않은 지점을 제외하고 거의 모든 곳에서 0인 양자화 그라데이션을 처리하기 위해, 가짜 양자화 연산자를 통해 그라데이션을 있는 그대로 통과하는 STE(straight-through estimator)를 사용합니다. QAT 프로세스가 완료되면 가짜 양자화 레이어는 모델이 추론에 사용되는 가중치와 활성화를 양자화하는 데 사용하는 양자화 스케일을 유지합니다.

PTQ는 단순하고 학습 파이프라인을 포함하지 않으므로 더욱 빠른 메서드입니다. 그러나 QAT는 거의 항상 더 나은 정확도를 생성하며 때로는 이게 유일하게 허용되는 메서드입니다.
TensorRT의 양자화
TensorRT 8.0은 2개의 서로 다른 처리 모드를 사용하여 INT8 모델을 지원합니다. 첫 번째 처리 모드는 TensorRT 텐서 동적 범위 API를 사용하며 INT8 정밀도(부호가 있는 8비트 정수) 컴퓨팅과 데이터를 기회적으로 사용하여 추론 지연 시간을 최적화합니다.
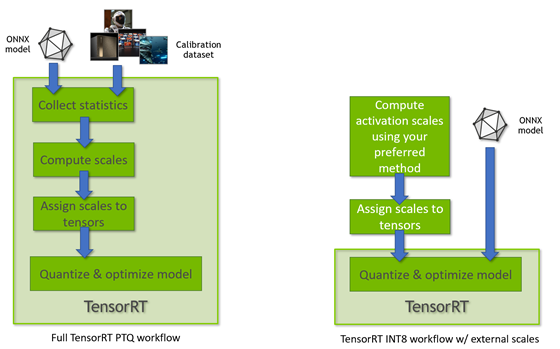
이 모드는 TensorRT가 전체 PTQ 보정 레시피를 수행하고 TensorRT가 사전 구성된 텐서 동적 범위를 사용할 때 사용됩니다(그림 3). 다른 TensorRT INT8 처리 모드는 QuantizeLayer/DequantizeLayer 계층을 사용하여 부동 소수점 ONNX 네트워크를 처리할 때 사용되며 명시적 양자화 규칙을 따릅니다. 차이점에 대한 자세한 내용은 TensorRT 개발자 가이드에서 명시적 양자화 및 PTQ 처리를 참조하십시오.
TensorRT 양자화 툴킷
PyTorch를 위한 TensorRT 양자화 툴킷은 최적화 가능한 QAT 모델을 생성하는 데 도움이 되는 편리한 PyTorch 라이브러리를 제공하여 TensorRT를 보완합니다. 이 툴킷은 QAT 또는 PTQ용 모델을 자동으로 또는 수동으로 준비하는 API를 제공합니다.
API의 핵심은 TensorQuantizer 모듈로, 텐서에서 양자화하거나, 가짜 양자화하거나, 통계를 수집할 수 있습니다. 텐서를 양자화하는 방법을 설명하는 QuantDescriptor와 함께 사용됩니다. TensorQuantizer 위에 레이어를 추가한 것은 PyTorch의 전정밀도 모듈의 드롭인 대체품으로 설계된 양자화된 모듈입니다. TensorQuantizer를 사용하여 모듈의 무게와 입력에 대한 통계를 가짜 양자화하거나 수집하는 편리한 모듈입니다.
이 API는 PyTorch 모듈을 양자화된 버전으로 자동 변환하도록 지원합니다. 모든 모듈을 양자화하고 싶지 않은 경우 부분적인 양자화가 가능한 API를 사용하여 수동으로 전환할 수도 있습니다. 예를 들어 일부 계층은 양자화에 더 민감할 수 있으며 양자화되지 않은 상태로 두면 작업 정확도가 향상됩니다.

QAT용 TensorRT 레시피는 NVIDIA 양자화 백서에 자세히 설명되어 있으며, 여기에는 다양한 학습 작업에 대한 QAT 및 PTQ를 비교한 실험 결과와 양자화 방법에 대한 보다 엄격한 논의가 포함됩니다.
코드 예제 소개
이 섹션에서는 툴킷에 포함된 분류 작업 양자화 예제를 설명합니다.
QAT용 권장 툴킷 레시피는 사전 학습된 모델과 미세 조정 모델에서 시작하여 정밀 조정이 더 높은 정확도로 이어지며 훨씬 적은 반복이 필요하다는 사실이 입증t됐기 때문에 사전 학습된 모델부터 시작할 것을 추천합니다. 이 경우 사전 학습된 ResNet50 모델을 로드합니다. bash 셸에서 예제를 실행하기 위한 명령줄 인수:
python3 classification_flow.py --data-dir [path to ImageNet DS] --out-dir . --num-finetune-epochs 1 --evaluate-onnx --pretrained --calibrator=histogram --model resnet50_res–data-dir 인수는 별도로 다운로드해야 하는 ImageNet(ILSVRC2012) 데이터세트를 가리킵니다. –calibrator=histogram 인수는 모델을 미세 조정하기 전에 히스토그램 보정기를 사용하여 모델을 보정해야 한다고 지정합니다. 나머지 인수 및 기타 많은 것이 예제에 문서화되어 있습니다.
ResNet50 모델은 원래 Facebook의 Torchvision 패키지에서 사용되었지만 몇 가지 중요한 변경 사항(Skip-Connection 양자화)이 포함되어 있으므로 네트워크 정의가 툴킷(resnet50_res)에 포함되어 있습니다. 자세한 내용은 Q/DQ 레이어 배치 권장 사항을 참조하십시오.
다음은 코드에 대한 간단한 개요입니다. 자세한 내용은 ResNet50 양자화를 참조하십시오.
# Prepare the pretrained model and data loaders
model, data_loader_train, data_loader_test, data_loader_onnx = prepare_model(
args.model_name,
args.data_dir,
not args.disable_pcq,
args.batch_size_train,
args.batch_size_test,
args.batch_size_onnx,
args.calibrator,
args.pretrained,
args.ckpt_path,
args.ckpt_url) 함수 prepare_model은 데이터 로더와 모델을 평소와 같이 인스턴스화하지만 양자화 설명자도 구성합니다. 예를 들면 다음과 같습니다.
# Initialize quantization
if per_channel_quantization:
quant_desc_input = QuantDescriptor(calib_method=calibrator)
else:
quant_desc_input = QuantDescriptor(calib_method=calibrator, axis=None)
quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantConvTranspose2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)
quant_desc_weight = QuantDescriptor(calib_method=calibrator, axis=None)
quant_nn.QuantConv2d.set_default_quant_desc_weight(quant_desc_weight)
quant_nn.QuantConvTranspose2d.set_default_quant_desc_weight(quant_desc_weight)
quant_nn.QuantLinear.set_default_quant_desc_weight(quant_desc_weight) QuantDescriptor 인스턴스는 양자화의 보정 메서드 및 축을 구성함으로써 텐서 보정 및 양자화 방법을 설명합니다. 각 양자화된 연산(예: quant_nn.QuantConv2d)마다 서로 다른 가짜 양자화 노드를 사용하기 때문에 QuantDescriptor에서 별도로 활성화 및 가중치를 구성합니다.
그런 다음 학습 그래프에 가짜 양자화 노드를 추가합니다. 다음 코드(quant_modules.initialize)는 장면 뒤에서 PyTorch 코드를 동적으로 패치하여 일부 torch.nn.module 하위 클래스가 양자화된 대응품으로 대체되고 모델의 모듈을 인스턴스화한 다음 동적 패치(quant_modules.deactivate)를 되돌리게 합니다. 예를 들어 torch.nn.conv2d는 2D 합성곱을 수행하기 전에 가짜 양자화를 수행하는 pytorch_quantization.nn.QuantConv2d로 대체됩니다. 모델 인스턴스화 전에 메서드 quant_modules.initialize를 호출해야 합니다.
quant_modules.initialize()
model = torchvision.models.__dict__[model_name](pretrained=pretrained)
quant_modules.deactivate()다음으로, 보정 데이터에 대한 통계(collect_stats)를 수집합니다. 즉, 모델에 대한 피드 보정 데이터를 수집하고 각 계층을 양자화할 수 있도록 히스토그램 형태로 활성화 분포 통계를 수집합니다. 히스토그램 데이터를 수집한 후 하나 이상의 보정 알고리즘(compute_amax)을 사용하여 스케일(calibrate_model)을 보정합니다.
보정 도중에 모델 정확도와 같은 일부 목표를 최적화하도록 각 계층의 양자화 규모를 결정하십시오. 현재 두 가지 보정기 클래스가 있습니다.
- pytorch_quantization.calib.histogram – 엔트로피 최소화(KLD), 평균 제곱 오차 최소화(MSE) 또는 백분위수 메트릭 방법을 사용합니다(분포의 지정된 비율이 표현되는 경우 동적 범위를 선택합니다).
- pytorch_quantization.calib.max – 최대 활성화 값을 사용하여 보정합니다(부동 소수점 데이터의 전체 동적 범위를 나타냅니다).
그 후에 보정 방법의 품질을 확인하려면 데이터세트의 모델 정확도를 평가하십시오. 이 툴킷을 이용하면 4가지의 서로 다른 보정 방법의 결과를 쉽게 비교하여 특정 모델에 가장 적합한 방법을 발견할 수 있습니다. 이 툴킷은 독점 보정 알고리즘을 통해 확장할 수 있습니다. 자세한 내용은 ResNet50 예제 노트을 참조하십시오.
모델의 정확도가 만족스러운 경우 QAT를 계속 진행하지 않아도 됩니다. ONNX로 내보내고 완료할 수 있습니다. 이것이 PTQ 레시피가 될 것입니다. TensorRT에는 양자화 스케일을 가진 Q/DQ 연산자가 있는 ONNX 모델이 주어지고 추론을 위한 모델을 최적화합니다. Q/DQ ONNX 모델로 이어지는 PTQ 워크플로우입니다.
QAT 단계를 계속 진행하려면 최상의 보정 양자화된 모델을 선택하십시오. QAT를 사용하여 원래 학습 일정의 약 10%를 어닐링 학습 속도 일정으로 미세 조정하고, 마지막으로 ONNX로 내보낼 수 있습니다. 자세한 내용은 딥 러닝 추론을 위한 정수 양자화: 원칙 및 경험적 평가 백서를 참조하십시오.
ONNX로 내보낼 때 염두에 두어야 할 몇 가지 사항이 있습니다.
- ONNX opset 13에 채널당 양자화(PCQ)가 도입되었으므로 권장 PCQ를 사용하는 경우 사용 중인 opset 버전에 유의하십시오.
- do_constant_folding 인수는 읽기 쉽고 더 작은 모델을 생성하기 위해 True로 설정되어야 합니다.
torch.onnx.export(model, dummy_input, onnx_filename, verbose=False, opset_version=opset_version, do_constant_folding=True)모델이 마침내 ONNX로 내보내지면 가짜 양자화 노드는 ONNX로 내보내서 두 개의 별도의 ONNX 연산자인 QuantizeLinear 및 DequantizeLinear(그림 5 Q 및 DQ로 표시)로 내보냅니다.

QAT 추론 단계
전반적으로 TensorRT는 Q/DQ 연산자를 통해 ONNX 모델을 TensorRT가 다른 ONNX 모델을 처리하는 방식과 유사하게 처리합니다.
- TensorRT는 Q/DQ 연산이 포함된 ONNX 모델을 가져옵니다.
- Q/DQ 처리 전용 최적화 세트를 수행합니다.
- 계속해서 일반 최적화 패스를 수행합니다.
- 추론 실행을 위한 플랫폼별 실행 계획 파일을 빌드합니다. 이 계획 파일에는 양자화된 작업 및 가중치가 포함되어 있습니다.
TensorRT에서 Q/DQ 네트워크를 구축하려면 INT8을 활성화하는 것 외에 특별한 빌더 구성이 필요하지 않습니다. 네트워크에서 Q/DQ 계층이 감지될 때 자동으로 활성화되기 때문입니다. TensorRT 샘플 애플리케이션 trtexec을 사용하여 Q/DQ 네트워크를 구축하는 최소 명령은 다음과 같습니다.
$ trtexec -int8 <onnx 파일>
TensorRT는 명시적 양자화라고 하는 특수 모드를 사용하여 Q/DQ 네트워크를 최적화하며, 이는 네트워크 운영에 사용되는 산술 정밀도에 대한 네트워크 처리 예측 가능성 및 제어의 요구 사항에 의해 동기가 됩니다. 처리-예측성은 원래 모델의 산술 정밀도를 유지할 것을 보장합니다. 아이디어는 Q/DQ 계층이 정밀한 변환이 일어나야 하는 위치를 지정하고 모든 최적화가 원래 ONNX 모델의 산술 시맨틱을 보존해야 한다는 것입니다.
TensorRT Q/DQ 처리와 일반 TensorRT INT8 처리가 이를 더 잘 설명하는 데 도움이 됩니다. 일반 TensorRT에서 INT8 네트워크 Tensor는 동적 범위 API 또는 보정 프로세스를 통해 양자화 스케일을 할당합니다. TensorRT는 백엔드 최적화를 적용할 때 모델을 부동 소수점 모델로 취급하며 INT8을 또 다른 도구로 사용하여 계층 실행 시간을 최적화합니다. 계층이 INT8에서 더 빠르게 실행되는 경우 INT8을 사용하도록 구성됩니다. 그렇지 않으면 FP32 또는 FP16 중 더 빠른 것이 사용됩니다. 이 모드에서 TensorRT는 지연 시간만을 위해 최적화되어 있으며 어느 작업이 양자화되는지 제어할 수 없습니다.
반대로 명시적 양자화에서 Q/DQ 계층은 정밀한 변환이 일어나야 하는 위치를 지정합니다. 이 최적화 도구는 네트워크에서 지시하지 않은 정밀 전환을 수행할 수 없습니다. 이러한 변환이 계층 정밀도를 증가시키는 경우(예: INT8 구현에 대한 FP16 구현 선택), 그러한 전환이 더 빠르게 실행되는 계획 파일로 이어지는 경우(예: INT8이 Tensor 코어에 의해 가속화되지 않는 V100에서 FP16에서 INT8을 선호하는 경우)에도 마찬가지입니다.
명시적 양자화에서는 정밀도 변환을 완전히 제어할 수 있으며 양자화를 예측할 수 있습니다. TensorRT는 여전히 성능을 위해 최적화되지만 원래 모델의 산술 정밀도를 유지하는 제약 하에 있습니다. Q/DQ 네트워크에서 동적 범위 API를 사용하는 것은 지원되지 않습니다.
명시적 양자화 최적화 패스는 다음 세 단계로 작동합니다.
- 첫째, 최적화 도구는 모델의 INT8 데이터를 최대화하고 Q/DQ 계층 전파를 사용하여 컴퓨팅을 시도합니다. Q/DQ 전파는 Q/DQ 계층이 네트워크에서 마이그레이션하는 방법을 지정하는 규칙의 집합입니다. 예를 들어 QuantizeLayer는 장소를 ReLU 활성화 계층으로 바꿔 네트워크 시작부로 마이그레이션할 수 있습니다. 이렇게 하면 ReLU 계층의 입력 및 출력 활성화가 INT8 정밀도로 감소되고 대역폭 요구 사항이 4배 줄어듭니다.
- 그런 다음 최적화 도구는 레이어를 융합하여 INT8 입력에서 작동하고 INT8 수학 파이프라인을 사용하는 양자화된 연산을 생성합니다. 예를 들어 QuantizeLayer는 ConvolutionLayer와 결합할 수 있습니다.
- 마지막으로 TensorRT 자동 조정기 최적화 도구는 레이어가 지정된 입력 및 출력 정밀도를 존중하는 각 계층의 가장 빠른 구현을 검색합니다.
TensorRT가 수행하는 주요 명시적 양자화 최적화에 대한 자세한 내용은 TensorRT 개발자 가이드를 참조하십시오.
TensorRT Q/DQ 네트워크 구축을 통해 만들어진 계획 파일에는 양자화된 가중치 및 작업이 포함되어 있으며 배포할 준비가 되어 있습니다. EfficientNet은 정확도를 유지하기 위해 QAT가 필요한 네트워크 중 하나입니다. 다음 차트는 PTQ와 QAT를 비교합니다.

자세한 내용은 NVIDIA DeepLearningExamples의 EfficientNet 양자화 예제를 참조하십시오.
결론
이 게시물에서는 기본 양자화 개념과 TensorRT의 양자화 툴킷을 간략하게 소개한 다음 TensorRT 8.0이 Q/DQ 네트워크를 처리하는 방법을 검토했습니다. 양자화 툴킷과 함께 제공되는 ResNet50 QAT 예제를 간단히 연습했습니다.
ResNet50은 PTQ를 사용하여 양자화할 수 있으며 QAT가 필요하지 않습니다. 그러나 EfficientNet은 정확도를 유지하기 위해 QAT가 필요합니다. EfficientNet B0 베이스라인 부동 소수점 Top1 정확도는 77.4이지만 PTQ Top1 정확도는 33.9이고 QAT Top1 정확도는 76.8입니다.
자세한 내용은 GTC 2021 세션, TensorRT 8.0을 이용한 PyTorch의 양자화 인식 학습.을 참조하십시오.