대화형 AI는 우리에게 가장 자연스러운 인터페이스인 음성과 자연어를 기반으로 인간과 기기 간에 인간과 비슷한 상호작용을 가능하게 하는 기술입니다. 대화형 AI 기반 시스템은 음성과 텍스트를 인식하고, 다른 언어로 즉석에서 번역하고, 인간의 의도를 이해하고, 인간 대화를 모방하는 방식으로 응답함으로써 명령을 이해할 수 있습니다.
대화형 AI 시스템과 애플리케이션을 구축하는 것은 어렵습니다. 데이터센터 배포를 위해 기업의 요구 사항에 맞게 단일 구성 요소를 조정하는 것은 더욱 어렵죠. 일반적으로 도메인별 애플리케이션을 배포하기 위해서는 요구 사항을 충족할 때까지 모델을 재훈련, 미세 조정, 배포하는 여러 주기가 필요합니다.
이러한 문제를 해결하기 위해 이 포스팅에서는 세 가지 주요 제품을 소개합니다.
- 대화형 AI 모델의 훈련과 미세 조정을 용이하게 하는 NVIDIA TAO Toolkit.
- 결과 모델의 배포와 추론을 용이하게 하는 NVIDIA Riva.
- 추가 미세 조정 또는 배포의 시작점이 될 수 있는 사전 훈련된 대화형 AI 모델을 제공하는NVIDIA NGC 컬렉션.
이러한 제품들의 긴밀한 통합 덕분에 80시간의 훈련, 미세 조정, 배포 주기를 8시간으로 단축할 수 있습니다. 이 포스팅에서는 TAO Toolkit에 초점을 맞춰, 다양한 전이 학습 시나리오를 지원하는 방법과, 대화형 AI 모델을 배포하고 실시간 추론을 실행하기 위해 Riva와 통합하는 방법을 보여줍니다.
대화형 AI 소개
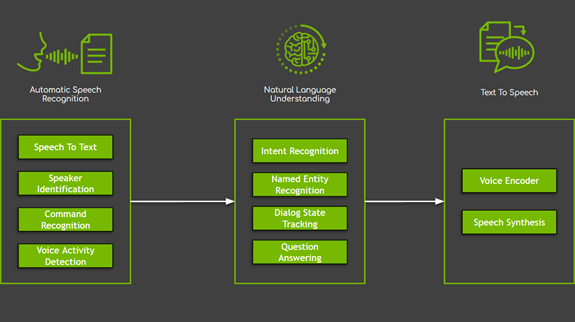
대화형 AI 시스템에는 크게 다음과 같은 세 가지 주요 도메인으로 분류되는 몇 가지 구성 요소가 있습니다(그림 1).
- 자동 음성 인식(ASR)은 사용자의 음성을 입력으로 시작하는 모든 작업을 포함합니다. 이러한 작업 중 음성을 텍스트로 변환하는 작업이 가장 많이 사용되죠.
- 자연어 처리(NLP)는 의미 정보 추출, 이해, 프로세싱을 포함한 텍스트 처리를 말합니다. NLP는 명명된 엔터티(entity) 인식과 같은 간단한 작업부터 대화 상태 추적, 질문 응답, 기계 번역과 같은 복잡한 작업까지 다양합니다.
- 텍스트 음성 변환 (TTS)은 텍스트 형식의 시스템 응답을 사용자가 들을 수 있는 음성 표기로 변환합니다.
그림 1. 대화형 AI 시스템의 세 가지 주요 도메인과 샘플 작업.
이러한 작업들은 다양한 방식으로 구현될 수 있지만, 심층 신경망을 기반으로 하는 새로운 방법은 대부분의 머신 러닝과 규칙 기반 솔루션의 한계를 극복하고 최상의 결과를 제시했습니다. 그러나 이러한 발전에는 대가가 따르죠. 신경망 기반 모델은 엄청난 데이터가 많이 필요합니다.
데이터 부족을 극복하기 위한 가장 일반적인 솔루션 중 하나는 ‘전이 학습(transfer learning)’이라는 기술을 사용하는 것입니다. 전이 학습은 기존 신경망을 새 신경망에 적응(미세 조정)할 수 있도록 하므로 도메인별 데이터가 훨씬 적습니다. 대부분의 경우 미세 조정은 훨씬 적은 시간이 소요되어(x10 인자 감소가 일반적) 시간과 자원을 절약해 줍니다. 마지막으로, 고품질의 대규모 공개 데이터세트가 부족한 상황에서 이 기술은 대화형 AI 시스템에 특히 매력적이죠.
TAO Toolkit 3.0 개요
TAO Toolkit은 사전 훈련된 신경 모델을 목적에 맞게, 고유 데이터로 커스터마이징하기 위한 파이썬(Python) 툴킷입니다. 이 툴킷의 목표는 최적화된 최첨단 사전 훈련 모델을 맞춤형 엔터프라이즈 데이터에서 쉽게 재훈련할 수 있도록 하는 것입니다.
TAO Toolkit의 가장 중요한 차별화 요소는 제로 코딩 패러다임을 따르고, 훈련과 미세 조정을 시작하는 데 사용할 수 있는 디폴트 파라미터 값과 함께 바로 사용할 수 있는 파이썬 스크립트, 구성 사양과 함께 제공된다는 것인데요. 따라서 모델에 대한 깊은 이해나 딥 러닝에 대한 전문 지식 또는 기초 코딩 기술이 없는 사용자도 새로운 모델을 훈련하고 사전 훈련된 모델을 미세 조정할 수 있게 해줍니다. 새로운 TAO Toolkit 3.0 릴리스와 함께, 이 툴킷은 중요한 전환점을 만들고 가장 유용한 대화형 AI 모델을 지원하기 시작했습니다.
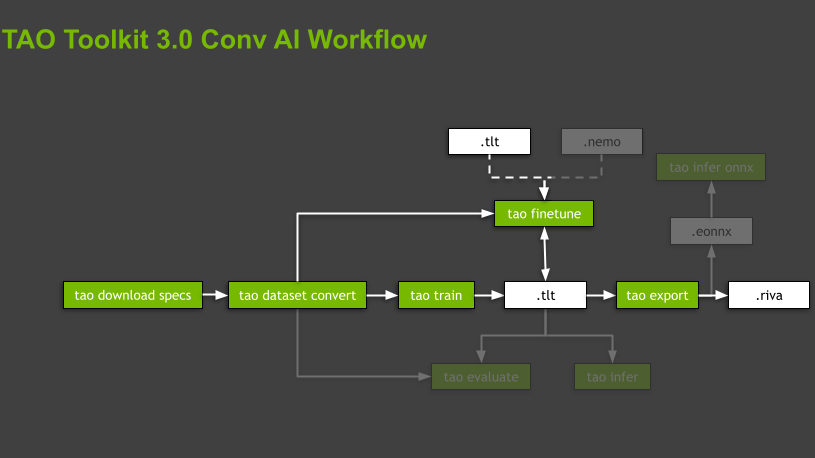
그림 2. 가장 중요한 하위 작업(녹색 상자)과 자산(흰색 상자)이 포함된 TAO Toolkit의 일반 워크플로우.
TAO Toolkit은 사전 구축된 전용 도커(Docker) 컨테이너 내에서 모든 작업을 실행하여 소프트웨어 종속성을 추상화합니다. 스크립트는 지원되는 모델과 관련된 도메인과 도메인별 작업에 따라 계층 구조로 구성됩니다. 툴킷은 각 모델에 대해 데이터 준비, 훈련, 모델 미세 조정부터 추론을 위한 내보내기까지 실행할 명령의 순서를 지정하여 안내합니다. 이러한 명령은 하위 작업(subtask)이며, 전체 조직은 워크플로우라고 합니다(그림 2).
TAO Toolkit은 워크플로우당 몇 가지 유용한 스크립트를 제공합니다. 이 포스팅에서는 강조 표시된 하위 작업에 중점을 두고 나머지 작업은 간략하게만 언급합니다.
TAO Toolkit 3.0을 사용하여 대화형 AI 모델 구축
TAO Toolkit은 NVIDIA PyPI (Private Python Package)에서 pip를 사용하여 설치할 수 있는 파이썬 패키지로 이용 가능합니다. 진입점은 TAO Toolkit Launcher이며 도커 컨테이너를 사용합니다. 다음 필수 구성 요소를 확인하세요.
- 공식 안내에 따라 docker-ce를 설치합니다. 그런 다음 설치 후 단계에 따라 도커가 관리자 권한 없이(즉, sudo 없이) 실행될 수 있는지 확인합니다.
- 안내에 따라 nvidia-container-toolkit을 설치합니다.
- NGC Docker 레지스트리에 로그인합니다.
$ docker login nvcr.io
Authenticating with existing credentials…
..
Login Succeeded새로운 파이썬 가상 환경을 사용하여 시스템의 다른 패키지와 독립적으로 TAO Toolkit 설치를 관리하는 것을 추천합니다.
# Install a virtual environment and activate it.
$ virtualenv -p python3 tao-env
$ source tao-env/bin/activate마지막으로 NVIDIA Python Package Index를 사용하여 TAO Toolkit 휠을 설치합니다.
# Install the NVIDIA Python Package Index.
$ pip install nvidia-pyindex
# Install the TAO Toolkit wheel.
$ pip install nvidia-tao이제 TAO Toolkit을 사용할 준비가 모두 끝났습니다. 설치 후 tao <task> <subtask> <parameters> 형식으로 표준화된 명령 집합을 제공하는 TAO Toolkit Launcher를 활성화합니다. 지원되는 다양한 옵션의 사용법을 보려면 tao –help를 실행하세요. 자세한 내용은 TAO Toolkit Launcher 사용 설명서에서 확인할 수 있습니다.
$ tao --help
usage: tao [-h]
{info,list,stop,augment,classification,detectnet_v2,dssd,emotionnet,faster_rcnn,fpenet,gazenet,gesturenet,heartratenet,intent_slot_classification,lprnet,mask_rcnn,punctuation_and_capitalization,question_answering,retinanet,speech_to_text,ssd,text_classification,tao-converter,token_classification,unet,yolo_v3,yolo_v4}맵 디렉터리
TAO Toolkit은 백그라운드에서 도커 컨테이너를 실행하여 다른 명령과 관련된 스크립트를 실행합니다. 이 컨테이너는 TAO Toolkit Launcher 뒤에 숨겨져 있으므로 걱정할 필요가 없습니다. 유일하게 해야 할 것은 데이터, 스펙 파일, 결과가 저장될 별도의 디렉토리를 미리 지정하는 것인데요. 또한 툴킷이 다운로드되고 사전 훈련된 체크포인트를 저장할 수 있는 .cache 디렉토리를 마운트해야 합니다. 이렇게 하면 새 훈련 또는 미세 조정이 실행될 때마다 스크립트가 동일한 파일을 계속해서 다운로드하는 것을 방지할 수 있습니다.
이러한 디렉터리는 명령줄 인수를 사용하여 도커 컨테이너에 설정, 표시하거나 ~/.tao_mounts.json 파일에서 구성할 수 있습니다. 자세한 내용은 런처 실행하기를 참조하세요.
다음 코드 예제는 구성 파일입니다. Source 값은 컴퓨터의 디렉터리를 나타내고 destination 은 도커 컨테이너에서 매핑되는 위치입니다.
# Content of the file ~/.tao_mounts.json:
{
"Mounts":[
{
"source": "~/tao/data",
"destination": "/data"
},
{
"source": "~/tao/specs",
"destination": "/specs"
},
{
"source": "~/tao/results",
"destination": "/results"
},
{
"source": "~/.cache",
"destination": "/root/.cache"
}
],
"DockerOptions":{
"shm_size": "16G",
"ulimits": {
"memlock": -1,
"stack": 67108864
}
}
}전이 학습을 사용하여 텍스트 분류 모델 구축
다음은 NLP 도메인의 예제 작업으로 BERT 기반 모델의 텍스트 분류입니다. 텍스트 분류는 내용에 따라 텍스트에 태그 또는 카테고리를 할당하는 일반적인 작업입니다.
다음 섹션에서는 텍스트 분류의 두 가지 애플리케이션에 중점을 둡니다.
- 감정 분석 – 카테고리는 입력 단락의 긍정적 또는 부정적 감정을 나타냅니다.
- 도메인 분류 – 카테고리가 서로 다른 대화 도메인입니다.
- NLP 도메인용 TAO Toolkit 3.0을 사용하여 전이 학습을 사용할 수 있는 두 가지 방법이 있습니다.
실험 스펙 파일 다운로드
TAO Toolkit Launcher가 초기화된 후 하나 또는 다른 워크플로우와 연결된 명령 호출을 시작할 수 있습니다. 이러한 모든 명령은 데이터세트 파라미터, 모델 파라미터, 옵티마이저와 훈련 하이퍼파라미터와 같이 많은 파라미터가 필요한 스크립트를 호출하는데요. TAO Toolkit이 사용하기 쉬운 이유 중 하나는 이러한 파라미터의 대부분이 실험 스펙 파일의 형태로 숨겨져 있다는 것입니다.
이러한 스펙 파일을 처음부터 작성하거나, tao <task> download_specs <args>를 실행하여 각 작업 또는 워크플로우를 위해 다운로드할 수 있는 디폴트 파일에서 시작할 수 있습니다. 런처를 통해 각 파라미터 또는 모든 파라미터를 개별적으로 재정의할 수도 있죠. 모든 스크립트 또는 모든 작업의 하위 작업 매개변수화에 대한 자세한 내용은 텍스트 분류에서 확인할 수 있습니다.
바로 시작하려면 텍스트 분류 작업에 대한 디폴트 스펙 파일을 다운로드하세요.
# Here, -r and -o specify the results and the output directories, respectively.
# These directories are from the perspective of the Docker container.
$ tao text_classification download_specs \
-r /results/nlp/text_classification/download_specs/ \
-o /specs/nlp/text_classification/
# Verify that the specs are present on your machine:
$ ls ~/tao/specs/nlp/text_classification/
dataset_convert.yaml export.yaml infer_onnx.yaml train.yaml
evaluate.yaml finetune.yaml infer.yaml디폴트 스펙 파일을 다운로드할 폴더를 나타내는 -o 인수와 로그를 저장할 위치를 스크립트에 지시하는 -r 인수를 확인하세요. -o 인수는 빈 폴더를 가리켜야 합니다.
사전 훈련된 인코더를 사용하여 감정 분석 모델 훈련
감정 분석 예제에서는 공개적으로 사용 가능한 Stanford Sentiment Treebank (SST-2) 데이터 세트를 사용합니다. 여기에는 영화 리뷰에서 가져온 11,855개 문장의 파스 트리에 감정 레이블이 달린 215,154개의 구문이 포함돼 있습니다. 모델은 세분화(5 가지) 또는 이진(긍정/부정) 분류 작업에 대해 훈련될 수 있으며, 성능은 정확도를 기반으로 평가됩니다. SST-2 형식은 각 데이터세트 분할, 즉 훈련, 개발, 테스트 데이터에 대한 .tsv 파일로 구성됩니다. 각 항목에는 공백으로 구분된 문장이 있고, 탭과 레이블이 붙습니다.
데이터 다운로드
SST-2.zip 아카이브를 다운로드하고, 데이터를 저장하여 TAO Toolkit Docker에 마운트할 수 있는 호스트 시스템의 디렉터리에 압축을 풉니다. 이 예에서는 home 폴더의 /data 폴더입니다.
# Download the archive.
$ wget https://dl.fbaipublicfiles.com/glue/data/SST-2.zip
# Unzip the archive.
$ unzip SST-2.zip -d ~/tao/data데이터 준비
모델을 훈련하거나 미세 조정하기 위한 첫 번째 단계는 데이터 준비입니다. TAO Toolkit은 훈련, 미세 조정, 평가 또는 추론에 필요한 형식으로 입력 데이터를 사전 처리하는 전용 데이터세트 변환 스크립트(tao <task> dataset_convert <args>)로 이 단계를 지원합니다.
텍스트 분류 작업의 경우, TAO Toolkit dataset_conversion 스크립트는 공개적으로 사용 가능한 두 개의 데이터세트 SST-2와 IMDB를 지원합니다. 이 포스팅에서는 SST-2를 사용합니다.
$ tao text_classification dataset_convert \
-e /specs/nlp/text_classification/dataset_convert.yaml \
-r /results/nlp/text_classification/dataset_convert \
dataset_name=sst2 \
source_data_dir=/data/SST-2 \
target_data_dir=/data/sst2구성 스펙 파일을 스크립트에 제공하는 -e 옵션과 로그 파일을 저장할 위치를 스크립트에 지시하는 -r 옵션을 확인하세요. 모든 경로는 도커 컨테이너에 탑재된 디렉터리를 참조합니다.
데이터세트가 올바른 형식으로 변환된 후 워크플로우의 다음 단계는 훈련(tao <task> train <args>) 또는 미세 조정 tao <task> finetune <args>)을 시작하는 것입니다.
사전 훈련된 인코더로 모델 훈련
아키텍처의 관점에서 TAO Toolkit에서 지원되는 모든 NLP 모델은 인코더-디코더 모델의 일반 카테고리에 속하며, 인코더는 BERT(Bidirectional Encoder Representations from Transformers)의 변형 중 하나인 인코더와 비회귀(non-regressive) 디코더입니다. NLP 모델과 BERT 기반 아키텍처에 대한 자세한 내용은 이 포스팅의 후반부를 참조하세요.
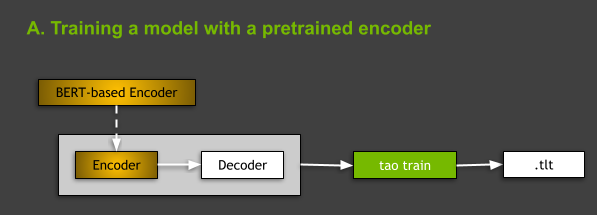
그림 3. 사전 훈련된 인코더를 사용한 모델 훈련의 아이디어를 보여주는 다이어그램.
TAO Toolkit에서 NLP 모델을 훈련할 때 두 가지 옵션이 있습니다. 처음부터 훈련하거나, 일부 제네릭 NLP 작업에 대해 사전 훈련된 BERT 기반 인코더를 사용하여 모델을 훈련할 수 있습니다. 이 포스팅에서는 후자의 경우에 초점을 맞춥니다(그림 3). model:의 language_model 하위 섹션에서 사전 훈련된 BERT 기반 인코더의 이름을 스펙 파일에 표시하면 됩니다.
# Content of the ~/tao/specs/nlp/text_classification/train.yaml
...
model:
...
language_model:
pretrained_model_name: bert-base-uncased
...이것은 텍스트 분류 작업에 대한 스펙 파일을 다운로드할 때의 디폴트 설정입니다. 자세한 내용은 훈련에 필요한 인수를 참조하세요.
모델을 훈련하려면 tao text_classification train <args> 명령을 실행해야 합니다.
- -e: 미세 조정 스펙 파일의 경로.
- -r: 출력 로그와 모델이 저장되는 폴더의 경로.
- -g: 사용할 GPU 수.
- -k: 모델을 저장하거나 로드하는 동안 사용할 사용자 지정 암호화 키.
- -r: 결과가 저장될 디렉터리를 지정하기 위해 사용됨.
- 스펙 파일의 파라미터에 대한 모든 오버라이드.
더 자세한 내용은 모델 훈련에서 확인할 수 있습니다. 이 포스팅의 나머지 부분에서 볼 수 있듯이 이러한 인수는 모든 워크플로우에 걸쳐 대부분의 TAO Toolkit 하위 작업에서 공유됩니다.
$ tao text_classification train \ -e /specs/nlp/text_classification/train.yaml \ -r /results/nlp/text_classification/train \ -g 1 \ -k $KEY \ training_ds.file_path=/data/sst2/train.tsv \ validation_ds.file_path=/data/sst2/dev.tsv \ training_ds.num_samples=500 \ validation_ds.num_samples=500 \ trainer.max_epochs=3
성공적으로 훈련한 결과, 스크립트는 모델 구성, 훈련된 모델 가중치, 함께 배포되어야 하는 출력 어휘와 같은 일부 추가 아티팩트를 포함하는 새로운 trained-model.tao 파일을 생성합니다. 이 명령은 KEY 환경 변수가 있다고 가정했습니다.
# Key that is used for encryption of your TAO Toolkit model.
$ KEY = "<your encryption key>"
도메인 분류 모델 미세 조정
TAO Toolkit은 NGC에서 다운로드한 사전 훈련된 모델 미세 조정과 같은 다른 사용 사례도 지원합니다. 다음 섹션에서는 도메인 분류기를 미세 조정하는 방법을 보여줍니다.
NGC에서 사전 훈련된 모델 다운로드
TAO Toolkit은 NGC에서 여러 자산을 제공합니다. NGC TAO Toolkit Text Classification 모델 카드에서 사전 훈련된 모델을 다운로드하세요. 사용 편의성을 위해 /results 폴더에 다운로드합니다.
# Download text classification model pretrained on the Misty chatbot domain dataset.
$ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/domainclassification_english_bert/versions/trainable_v1.0/zip -O domainclassification_english_bert_trainable_v1.0.zip
# Unzip the archive.
$ unzip domainclassification_english_bert_trainable_v1.0.zip
# Move the model file to the mounted result folder.
$ mv domainclassification_english_bert.tlt ~/tao/results/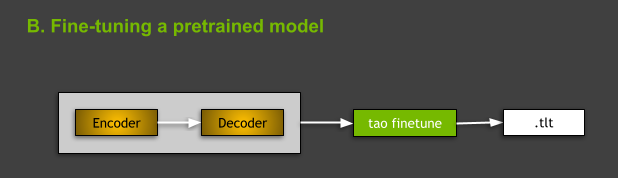
그림 4. 사전 훈련된 모델 미세 조정.
사전 훈련된 모델 미세 조정
TAO Toolkit에서 텍스트 분류 모델을 미세 조정하려면 tao text_classification finetune <args> 명령을 사용합니다. 명령의 관점에서 훈련과 미세 조정의 주요 차이점은 미세 조정에 필요한 사전 훈련된 모델 -m 인수가 있다는 것인데요. 여기서 -m은 사전 훈련된 모델 파일의 경로입니다.
이 예에서는 데이터세트를 훈련, 미세 조정이 가능한 형식으로 변환해야 합니다. 자세한 내용은 데이터 형식을 참조하세요. 훈련과 비슷하게, 미세 조정에 사용된 데이터가 있는 폴더가 is ~/tao/data/my_domain_classification/이라고 가정하고 미세 조정과 유효성 검사 데이터가 포함된 파일의 경로도 수동으로 오버라이드합니다. 이전 단계에서 다운로드한 nlp-tc-trained-model.tao 파일을 입력으로 사용합니다.
$ KEY="tlt_encode" tao text_classification finetune \
-e /specs/nlp/text_classification/finetune.yaml \
-r /results/nlp/text_classification/finetune \
-m /results/domainclassification_english_bert.tlt \
-g 1 \
-k $KEY \
finetuning_ds.file_path=/data/my_domain_classification/train.tsv \
validation_ds.file_path=/data/my_domain_classification/dev.tsv 이 공개 NGC 모델의 암호화 키는 tlt_encode입니다.
성능 평가
평가 하위 작업의 목표는 테스트 분할에서 주어진 모델의 성능을 측정하는 것입니다. tao <task> evaluate <args>:를 실행하세요.
$ tao text_classification evaluate \
-e /specs/nlp/text_classification/evaluate.yaml \
-r /results/nlp/text_classification/evaluate \
-m /results/nlp/text_classification/train/checkpoints/trained-model.tao \
-g 1 \
-k $KEY \
test_ds.file_path=/data/sst2/test.tsv \
test_ds.batch_size=32추론 실행
평가 하위 작업 외에도, TAO Toolkit은 모델이 예상대로 작동하는지 테스트하고 제공된 원시 입력 샘플(speech_to_text 작업에 대한 .wav 파일, question_answering 작업을 위한 원시 텍스트 또는 문장 등)에 대한 출력을 조사하는 데 유용한 <task> infer <args> 하위 작업을 가능하게 합니다. 이 경우 추론을 실행하면 모델이 입력 문장의 감정을 적절하게 분류할 수 있는지 여부가 표시됩니다.
# For inference:
$ tao text_classification infer \
-e /specs/nlp/text_classification/infer.yaml \
-r /results/nlp/text_classification/infer \
-m /results/nlp/text_classification/train/checkpoints/trained.tao \
-g 1 \
-k $KEY모델 내보내기
마지막으로 모델이 올바르게 작동한다고 판단하면 tao <task> export <args> 명령을 사용하여 배포용으로 내보낼 수 있습니다.
# For export to Riva:
# For export to Riva:
$ tao text_classification export \
-e /specs/nlp/text_classification/export.yaml \
-r /results/nlp/text_classification/export \
-m /results/nlp/text_classification/train/checkpoints/trained.tao \
-k $KEY디폴트로, /results/nlp/text_classification/export 폴더에 exported-model.riva 파일이 생성됩니다. 내보내기 하위 작업을 통해 모델을 ONNX (Open Neural Network Exchange) 형식 (.eonnx)으로 내보낼 수도 있습니다. export_format=ONNX 파라미터를 수동으로 설정해야 합니다. 설정이 완료되면 tao <task> infer_onnx <args> 명령을 실행하여, 내보낸 ONNX 모델의 동작을 테스트할 수도 있습니다. 그러나 이것은 선택 사항이며 현재 Riva와 Riva 기반 추론에 대한 배포 관점에서 필수 사항은 아닙니다.
모든 TAO Toolkit 명령에 대한 자세한 내용은 TAO Toolkit v3.0 사용 설명서를 참조하십시오. 또한 이 포스팅 후반부에서 지원되는 다른 대화형 AI 작업에 대해 간략하게 설명합니다.
대화형 AI 모델을 Riva에서 실시간 서비스로 배포
NVIDIA Riva는 GPU를 사용해 음성 AI 서비스를 구축하기 위한 GPU 가속 SDK입니다. Riva SDK에는 ASR, NLP, TTS 작업을 위해 사전 훈련된 모델, 도구, 최적화된 엔드 투 엔드 서비스가 포함돼 있습니다. Riva를 사용하여 GPU에서 추론에 최적화된 서비스로 모델을 배포하세요. GPU의 연산 능력을 최대한 활용하기 위해, Riva는 NVIDIA Triton Inference Server를 사용해 신경망을 제공하고 NVIDIA TensorRT로 추론을 실행합니다. 그 결과, 실시간 서비스는 CPU 전용 플랫폼에서 필요한 25초보다 훨씬 빠른 150ms로 실행될 수 있습니다.
Riva로 내보낸 TAO Toolkit 모델(이전 섹션에서 만든.riva 파일)을 배포하려면 필요한 모든 자산(모델 그래프, 모델 가중치, 모델 구성, 추론에 사용된 어휘 등)을 결합하는 유틸리티인 Riva ServiceMaker를 사용하여 대상 환경에 배포합니다. 그림 5는 Riva ServiceMaker가 riva-build 와 riva-deploy 두 가지 주요 구성 요소로 구분되어 있음을 보여줍니다.
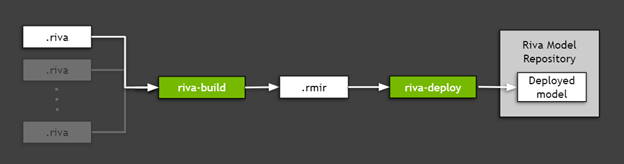
그림 5. Riva ServiceMaker를 사용하여 내보낸 TAO Toolkit 모델 배포.
Riva 필수 구성 요소 설치
먼저, 나중에 사용할 일부 환경 변수를 설정합니다. 이 예에서는 이전에 TAO Toolkit으로 훈련하고 내보낸 감정 분석 모델을 사용하므로 그에 따라 경로를 설정해야 합니다.
# Location of Riva Quick Start.
RIVA_QUICK_START=nvidia/riva/riva_quickstart:1.6.0-beta
# Location Riva ServiceMaker Docker image.
RIVA_SM_CONTAINER=nvcr.io/nvidia/riva/riva-speech:1.6.0-beta-servicemaker
# Directory where the .riva model exported from TAO Toolkit is stored.
EXP_MODEL_LOC=/results/nlp/text_classification/export
# Name of the .riva file.
EXP_MODEL_NAME=exported-model.riva
# Riva Model Repository folder where the *.rmir and other required assets are stored.
RIVA_REPO_DIR=/data/
# In the following, you reuse the $KEY variable used in TAO Toolkit.이 예에서는 /data 폴더를 Riva Model Repository 값으로 사용하는데요. 이 이름이 Riva Quick Start 스크립트에서 디폴트로 사용되기 때문입니다. 추론 서버를 실행하는 데 필요한 모든 자산과 함께 모델 앙상블을 저장하는 데 사용되는 폴더입니다.
다음으로, Riva Quick Start 스크립트를 설치하세요. 가장 간단한 경로는 NGC 레지스트리를 통해 이어집니다. NGC CLI를 설치하고 다음 명령을 실행합니다.
# Download Riva Quick Start:
$ ngc registry resource download-version $RIVA_QUICK_START마지막으로 Riva ServiceMaker Docker 이미지를 가져옵니다.
# Get the ServiceMaker Docker container
$ docker pull $RIVA_SM_CONTAINER모델 배포 준비가 됐습니다.
Riva 빌드 실행
riva-build 는 하나 이상의 내보낸 모델(.riva 파일)을 Riva 모델 중간 표현(.rmir)이라고 하는 중간 형식을 포함하는 단일 파일로 조합하는 역할을 합니다. 이 파일에는 최종 배포와 추론에 필요한 모든 자산과 함께 전체 엔드 투 엔드 파이프라인의 배포 애그노스틱(agnostic) 스펙이 포함돼 있습니다. Riva ServiceMaker Docker 이미지 내에서 riva-build 명령을 실행하려면, 다음 명령을 실행하세요.
# Run the riva-build to generate an .rmir ensemble.
$ docker run --gpus all --rm -v $EXP_MODEL_LOC:$EXP_MODEL_LOC -v $RIVA_REPO_DIR:/data --entrypoint="/bin/bash" $RIVA_SM_CONTAINER -- \
riva-build text_classification -f /data/rmir/tc-model.rmir:$KEY \
$EXP_MODEL_LOC/$EXP_MODEL_NAME:$KEYRiva 배포 실행
riva-deploy 배포 툴은 .rmir 파일을 입력으로 받아 실행을 위한 파이프라인을 지정하는 앙상블 구성을 생성합니다.
이 경우 배포를 실행하는 Riva Quick Start와 함께 제공되는 스크립트를 사용합니다. riva-deploy를 수동으로 호출하는 방법에 대한 자세한 내용은 Riva Deploy를 참조하세요.
Quick Start를 사용하여 Riva 서버 시작
Riva에서 모델을 배포하는 두 가지 옵션이 있습니다. 이 예의 경우, 이전에 NGC에서 가져온 Riva Quick Start를 사용하여 로컬 워크스테이션을 설정합니다. Pull에서 생성된 폴더에서 config.sh 파일을 찾습니다. 다음 코드 예제에서는 추가 변수 $RIVA_DIR을 사용하여 이 폴더를 표시합니다. config.sh 파일을 편집하고 다음 변경 사항을 적용합니다.
# Enable NLP service only.
service_enabled_asr=false ## MAKE CHANGES HERE
service_enabled_nlp=true ## MAKE CHANGES HERE
service_enabled_tts=false ## MAKE CHANGES HERE
# ...
# Specify the encryption key to use to deploy models.
MODEL_DEPLOY_KEY=<key you have used> ## MAKE CHANGES HERE
# ...
# Indicate that you want to use .rmir generated previously.
use_existing_rmirs=true ## MAKE CHANGES HERE
# ...
# Set Riva Model Repository path to folder with your model.
riva_model_loc=/data ## MAKE CHANGES HERE이러한 변경 사항은 Quick Start 스크립트가 자동으로 riva-deploy를 실행하고 Riva 추론 서버를 실행하도록 지시합니다.
# Ensure that you have permissions to execute these scripts.
$ cd $RIVA_DIR
$ chmod +x ./riva_init.sh && chmod +x ./riva_start.sh
# Initialize Riva model repo with your custom RMIR.
$ riva_init.sh
# Start the Riva server and load your custom model.
$ riva_start.sh클라이언트 애플리케이션 구현
Riva 서버가 실행되고 모델과 함께 실행되면 서버를 쿼리하는 추론 요청을 보낼 수 있습니다. gRPC 요청을 보내려면 Riva 클라이언트 Python API 바인딩을 설치하세요. 이 API는 Riva Quick Start와 함께 pip .whl 로 제공됩니다.
# Install Riva client API bindings.
$ cd $RIVA_DIR && pip install riva_api-1.0.0b1-py3-none-any.whl이제 바인딩을 사용하여 클라이언트를 작성합니다.
import grpc
import argparse
import os
import riva_api.riva_nlp_pb2 as rnlp
import riva_api.riva_nlp_pb2_grpc as rnlp_srv
class BertTextClassifyClient(object):
def __init__(self, grpc_server, model_name):
# generate the correct model based on precision and whether or not ensemble is used
print("Using model: {}".format(model_name))
self.model_name = model_name
self.channel = grpc.insecure_channel(grpc_server)
self.riva_nlp = rnlp_srv.RivaLanguageUnderstandingStub(self.channel)
self.has_bos_eos = False
# use the text_classification network to return top-1 classes for intents/sequences
def postprocess_labels_server(self, ct_response):
results = []
for i in range(0, len(ct_response.results)):
intent_str = ct_response.results[i].labels[0].class_name
intent_conf = ct_response.results[i].labels[0].score
results.append((intent_str, intent_conf))
return results
# accept a list of strings, return a list of tuples ('intent', scores)
def run(self, input_strings):
if isinstance(input_strings, str):
# user probably passed a single string instead of a list/iterable
input_strings = [input_strings]
# get intent of the query
request = rnlp.TextClassRequest()
request.model.model_name = self.model_name
for q in input_strings:
request.text.append(q)
ct_response = self.riva_nlp.ClassifyText(request)
return self.postprocess_labels_server(ct_response)
def run_text_classify(server, model, query):
print("Client app to test text classification on Riva")
client = BertTextClassifyClient(server, model_name=model)
result = client.run(query)
print(result) 클라이언트 실행
이제 클라이언트를 실행할 준비가 됐습니다.
# Run the function.
run_text_classify(server="localhost:50051", model="<Enter Model Name>", query="How is the weather tomorrow?")명령을 실행하면 다음과 같은 결과가 나타납니다.
Client app to test text classification on Riva
Using model: riva_text_classification
[('negative', 0.5620560050010681)]이로써 여러분은 TAO Toolkit을 사용하여 모델을 훈련하고, Riva에 배포하고, Riva 추론 서버를 실행하고, Riva API를 사용하여 간단한 클라이언트를 작성하는 방법을 배웠습니다. 축하합니다!
TAO Toolkit 3.0에서 지원하는 기타 대화형 AI 작업과 모델
앞서 제시된 텍스트 분류 작업은 이번 TAO Toolkit 3.0 릴리스에서 지원되는 작업 중 하나일 뿐입니다. 이 릴리스는 대화형 AI 공간에서 ASR 과 NLP라는 두 가지 도메인 작업을 지원합니다. 이 릴리스에서 TTS를 건너뛰는 주된 이유는 최첨단 TTS 모델의 훈련이 어렵다는 것을 알기 때문인데요. 사용자 전문성과 도메인 지식이 필요하죠. 제로 코딩 패러다임에 대한 준비가 되어 있지 않습니다.
자동 음성 인식 도메인
자동 음성 인식(ASR)은 가청 음성 입력에서 의미 있는 정보를 추출하는 작업입니다. 이 도메인의 대표적인 작업에는 대화형 가상 비서에 음성 명령을 내리고, 영화와 화상 채팅에서 오디오를 자막으로 변환하고, 콜센터에서 고객 상담 내용을 보관하기 위해 텍스트로 변환하는 것 등이 있습니다.
현재 TAO Toolkit 3.0은 ASR 도메인의 단일 작업, 예를 들면 음성 텍스트 변환(STT)(tao speech_to_text <subtask> <args>)를 지원하며, 이 작업은 음성 전사를 담당합니다. 모델의 출력은 다양한 용도로 사용될 수 있는데요. 추가 로직으로 STT의 출력을 음성 명령에 사용할 수 있습니다.
TAO Toolkit 사용자는 세 가지 모델을 사용할 수 있습니다. 모두 다음과 같은 컨볼루션(convolutional) 신경 음향 모델입니다.
- Jasper 아키텍처는 전체 서브블록을 단일 GPU 커널로 융합하여 빠른 GPU 추론을 용이하게 하도록 설계됐습니다. 이는 추론하는 동안 STT의 엄격한 실시간 요구 사항을 충족하는 데 중요합니다.
- QuartzNet은 분리 가능한 컨볼루션과 더 큰 필터 크기를 사용하는 Jasper와 유사한 네트워크입니다. 파라미터가 훨씬 적으면서도 Jasper와 비슷한 정확도를 구현합니다.
- Citrinet 은 서브워드 인코딩과 SE(squeeze-and-excitation)와 결합된 1D 시간 채널 분리 가능한 컨볼루션을 사용하는 QuartzNet 버전입니다. 결과 아키텍처는 비자기회귀(non-autoregressive), 시퀀스-투-시퀀스, 변환기 모델 간의 격차를 크게 줄입니다.
자연어 처리 도메인
자연어 처리(NLP)는 대화형 AI 애플리케이션의 또 다른 주요 요소입니다. 이 도메인의 작업에는 텍스트 분류, 언어의 의도 이해, 키워드 또는 엔터티 인식, 자동 구두점과 대문자 추가, 주어진 컨텍스트에 대한 질문 응답이 포함됩니다.
TAO Toolkit 3.0은 NLP 도메인의 5가지 다양한 작업 또는 모델을 지원합니다.
- 공동 의도 & 슬롯 분류 (tao intent_slot_classification <subtask> <args>)는 쿼리에서 의도를 분류하고 이 의도에 대한 모든 관련 슬롯(엔터티)을 감지하는 작업입니다. 예를 들어 “내일 아침 산타클라라 날씨는?”이라는 쿼리에서는, 쿼리를 “날씨” 의도로 분류하고, “산타클라라”를 위치 슬롯으로 감지하고, “내일 아침”을 date_time 슬롯으로 감지하겠죠. 의도와 슬롯 이름은 보통 작업에 따라 다르며 훈련 데이터의 레이블로 정의됩니다. 이는 모든 작업 기반 대화형 AI 비서에서 실행되는 기본 단계입니다.
- 공동 구두점 & 대문자 사용 (tao punctuation_and_capitalization <subtask> <args>) 입력 문장 또는 단락의 모든 단어에 대해 모델은 단어 다음에 오는 구두점과 단어를 대문자로 표시할지 여부를 예측해야 합니다.
- 질문 응답 (tao question_answering <subtask> <args>)자연 언어로 된 질문과 컨텍스트가 모두 주어지면 모델은 질문에 대한 답변을 나타내는 시작과 끝 위치를 사용하여 컨텍스트 내 범위를 예측해야 합니다.
- 텍스트 분류 (tao text_classification <subtask> <args>)는 감정 분석, 도메인 분류, 언어 식별, 주제 분류와 같은 많은 애플리케이션에 적용할 수 있는 기초적이지만 유용한 NLP 작업입니다. 예를 들어, 감정 분석에서 “성능이 훌륭하다!”라는 입력은 긍정적인 감정을 가지고 있는 반면, “그렇게 낭만적이지도 않고 짜릿하지도 않다”는 부정적인 감정을 가지고 있습니다.
- 토큰 분류 (tao token_classification <subtask> <args>)는 입력 토큰의 각 엔터티(예: 단어)에 출력에 해당되는 레이블이 부여되는 작업입니다. 명명된 엔터티 인식(NER)은 텍스트에서 주요 정보(엔티티)를 감지, 분류하는 것을 목표로 하는 토큰 분류 작업의 한 애플리케이션입니다. 예를 들어 “메리는 산타클라라에 살고 NVIDIA에서 일합니다”라는 문장에서, 모델은 “Mary”는 사람, “산타클라라”는 위치, “NVIDIA”는 회사임을 감지해야 합니다.
TAO Toolkit에서 지원되는 모든 NLP 모델은 BERT 를 백본 인코더로 통합합니다. BERT는 Transformer 라는 주의(attention) 기반 아키텍처를 사용하여 텍스트에서 단어 간의 관계를 표시하는 문맥 단어 임베딩을 학습합니다. BERT의 주요 혁신은 사전 훈련 단계에 있는데요. 모델은 큰 텍스트 말뭉치를 사용하여 두 가지 비지도(unsupervised) 예측 작업에 대해 훈련됩니다. 이러한 비지도 작업에 대한 훈련은 제네릭 언어 모델을 생성하며, 이 모델은 다양한 NLP 작업에서 최첨단 성능을 달성하기 위해 신속하게 미세 조정될 수 있습니다.
결론
그렇다면 TAO Toolkit이 가장 적합한 대상은 누구인지 궁금하신가요? 현재 툴킷의 주요 사용자는 이미 모델의 기본 아키텍처를 가지고 있으며 파이프라인의 특정 사용 사례에 맞게 커스터마이징하고 미세 조정하려는 사용자입니다.
사전 정의된 스펙 파일, 상세 문서, 빌드인 암호화, 추론 지향 Riva와의 즉시 통합, NGC에 대한 사전 훈련된 모델 세트와 함께 TAO Toolkit은 개발에서 배포까지 전체 프로세스의 속도를 최대 10배 높이는 것을 목표로 합니다. NVIDIA는 TAO Toolkit이 전이 학습과 대화형 AI와 관련된 모든 것을 원스톱으로 처리할 수 있다고 믿습니다.
자세한 내용은 다음 리소스를 참조하세요.