
AI やハイパフォーマンス コンピューティング (HPC) における需要の高まりにより、すべての GPU 間で高速通信が可能な、より高速で柔軟性の高い相互接続のニーズが高まっています。
第 3 世代の NVIDIA NVSwitch は、この通信ニーズを満たすように設計されています。この最新の NVSwitch と H100 Tensor コア GPU は、NVIDIA の最新の高速ポイントツーポイントの相互接続インターコネクトである第 4 世代の NVLink を採用しています。
第 3 世代の NVIDIA NVSwitch は、NVLink Switch System のノード内またはノード外部の GPU への接続性を提供するように設計されています。また、マルチキャストとネットワーク内のデータ送信量を削減する NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) による、コレクティブ処理のためのハードウェア アクセラレーションも組み込まれています。
NVIDIA NVSwitch は、最大 256 基の NVIDIA H100 Tensor コア GPU を接続し、57.6 TB/秒の All-to-All 帯域幅を持つクラスターの作成を可能にする NVLink Switch ネットワーキング アプライアンスの重要な要素にもなっています。このアプライアンスは、NVIDIA Ampere アーキテクチャ GPU 上の HDR InfiniBand の 9 倍のバイセクション帯域幅を提供します。
広帯域幅で GPU に対応した動作を実現
AI や HPC ワークロードの性能に対するニーズは急速に高まり続けており、マルチノード、マルチ GPU システムへの拡張が求められています。
優れた性能を大規模に提供するには、すべての GPU 間で広帯域幅の通信が必要です。NVIDIA NVLink の仕様は、NVIDIA GPU との相乗効果により、必要な性能と拡張性を実現できるように設計されています。
例えば、NVIDIA GPU のスレッドブロック実行構造は、並列化された NVLink アーキテクチャに効率的にフィードされます。また、NVLink-Port インターフェイスは、GPU L2 キャッシュのデータ交換セマンティクスと可能な限り一致するよう設計されています。
PCIe より高速
NVLink の主な利点は、PCIe よりも大幅に広い帯域幅を提供することです。第 4 世代の NVLink は、1 レーンあたり 100 Gbps の能力があり、PCIe Gen5 の帯域幅 32 Gbps の 3 倍以上です。複数の NVLink を組み合わせることで、さらに高い集約レーン数を実現し、より高いスループットを得ることができます。
従来のネットワークより低いオーバーヘッド
NVLink は、GPU を相互接続するための高速なポイントツーポイント リンクとして特別に設計されており、従来のネットワークよりもオーバーヘッドを低く抑えることができます。
これにより、エンドツーエンドの再試行、アダプティブ ルーティング、パケットの並べ替えなど、従来のネットワークに見られる複雑なネットワーク機能の多くを、ポート数の増加と引き換えに実現することができます。
ネットワーク インターフェイスがよりシンプルになったことで、アプリケーション層、プレゼンテーション層、セッション層の機能を CUDA 自体に直接組み込むことができ、通信のオーバーヘッドをさらに削減することができます。
NVLink の世代
NVIDIA P100 GPU で初めて導入された NVLink は、NVIDIA GPU アーキテクチャと歩調を合わせて進化し続け、新しいアーキテクチャが登場するたびに、新世代の NVLink が登場しています。
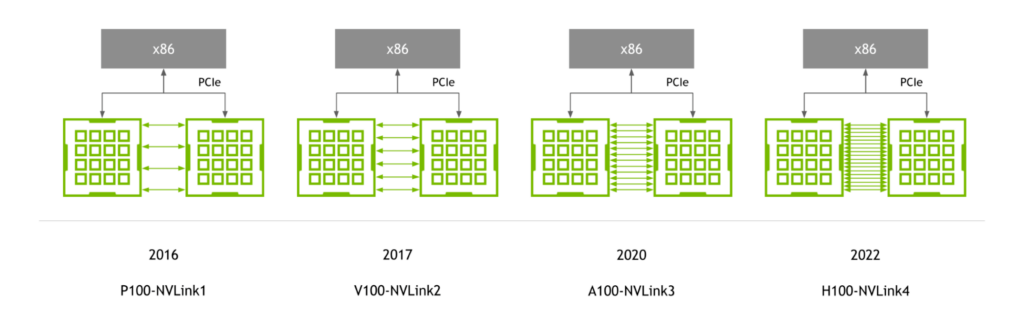
第 4 世代の NVLink は、GPU あたり 900GB/s の双方向帯域幅を提供し、前世代に比べて 1.5 倍、第 1 世代の NVLink に比べて 5.6 倍以上向上しています。
NVLink 対応サーバーの世代
NVIDIA NVSwitch は、NVIDIA V100 Tensor コア GPU と第 2 世代の NVLink で初めて導入され、サーバー内のすべての GPU 間で広帯域幅、任意の接続を可能にしました。
NVIDIA A100 Tensor コア GPU は、第 3 世代の NVLink と第 2 世代の NVSwitch を導入し、GPU 毎の帯域幅とリダクションの帯域幅の両方を倍増させました。
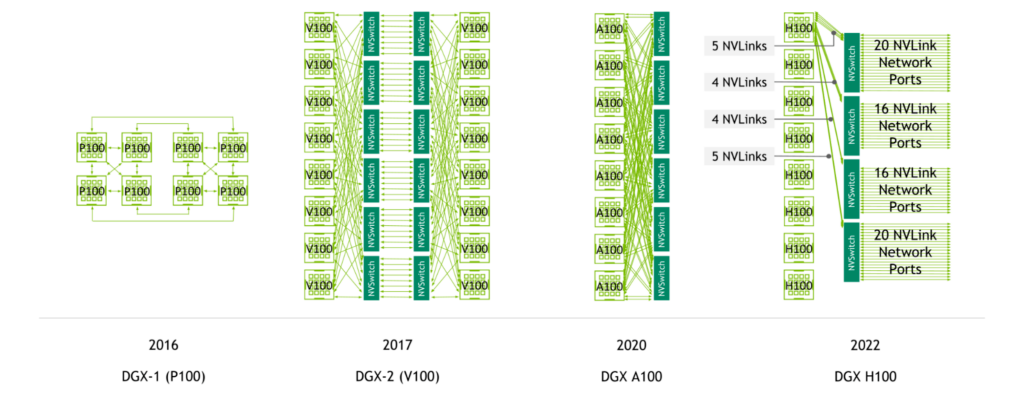
第 4 世代 NVLink と第 3 世代 NVSwitch により、NVIDIA H100 Tensor コア GPU を 8 基搭載したシステムは、3.6 TB/秒のバイセクション帯域幅と 450 GB/秒のリダクション処理の帯域幅を備えています。これは、前世代と比較して 1.5 倍、3 倍に増加しています。
また、第 4 世代 NVLink と第 3 世代 NVSwitch、さらに外付けの NVIDIA NVLink Switch により、複数のサーバーをまたいだ NVLink 速度でのマルチ GPU 通信が可能になりました。
今までで最大かつ最速のスイッチ チップ
第 3 世代 NVSwitch は、これまでで最大の NVSwitch です。NVIDIA 向けにカスタマイズされた TSMC 4N プロセスで製造されています。このダイには、251 億個のトランジスタが組み込まれており、これは、NVIDIA V100 Tensor コア GPU よりも多くのトランジスタが、294 mm2 の面積に収められています。パッケージの寸法は 50 mm x 50 mm で、合計 2645 個のはんだボールが使用されています。
NVLink Network 対応
第 3 世代の NVSwitch は、ノードをまたいだ GPU 間を NVLink 速度で接続する NVLink Switch System を実現するための重要な鍵です。
400 Gbps イーサネットおよび InfiniBand 接続と互換性のある物理 (PHY) 電気インターフェイスを搭載しています。付属の管理コントローラーは、1 ケージあたり 4 つの NVLink を持つ OSFP (Octal Small Formfactor Pluggable) モジュールの接続をサポートするようになりました。カスタム ファームウェアにより、アクティブ ケーブルもサポート可能です。
また、NVLink Network の性能と信頼性を高めるために、FEC (Forward Error Correction) モードが追加されました。
また、データやチップの構成を攻撃から守るためのセキュリティ プロセッサも追加されました。チップは、ポートのサブセットを個別の NVLink Network に分離できるパーティショニング機能を提供します。テレメトリ機能の拡張により、 InfiniBand スタイルのモニタリングも可能です。
帯域幅を 2 倍に
第 3 世代の NVSwitch は、これまでで最も帯域幅の広い NVSwitch です。
50 Gbaud PAM4 信号を使用した差動ペアあたり 100 Gbps の帯域幅を持つ第 3 世代の NVSwitch は、64 個の NVLink ポート (NVLink あたり 2 個) 全体で 3.2 TB/秒の全二重帯域幅を提供します。システムにより多くの帯域幅を提供する一方で、前世代と比較して、必要な NVSwitch チップの数は少なくなっています。第 3 世代 NVSwitch のすべてのポートは、NVLink Network に対応しています。
SHARP のコレクティブとマルチキャストのサポート
第 3 世代の NVSwitch には、SHARP アクセラレーションのための新しいハードウェア ブロックが多数含まれています。
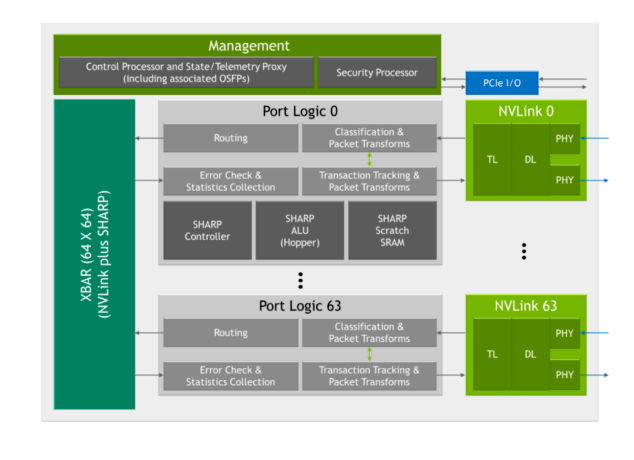
- SHARP のコントローラー
- NVIDIA Hopper アーキテクチャの ALU を高度に活用した SHARP 製算術論理演算ユニット (ALU)
- SHARP の演算をサポートする SRAM を内蔵。
組み込み ALU は、最大 400 GFLOPS の FP32 スループットを提供し、システム内の GPU ではなく、NVSwitch で直接リダクション処理を実行するように追加されました。
これらの ALU は、論理演算、最小/最大演算、加算など、さまざまな演算をサポートしています。また、符号付き整数、符号なし整数、FP16、FP32、FP64、BF16 などのデータ形式をサポートしています。
第 3 世代の NVSwitch には、最大 128 の SHARP グループを並行して管理できる SHARP コントローラーも搭載されています。チップ内のクロスバー帯域幅は、SHARP 関連のやり取りを追加で行えるように拡大されました。
all-reduce 処理の互換性
NVIDIA SHARP の主な用途は、AI トレーニングで一般的な all-reduce 処理です。複数の GPU を使ってネットワークを学習させる場合、バッチをより小さなサブバッチに分割し、それを個々の GPU に割り当てます。
各 GPU はネットワーク パラメーターを通して個々のサブバッチを処理し、パラメーターに起こりうる変化 (ローカル勾配とも呼ばれる) を得ます。これらのローカル勾配は結合され、調整されてグローバル勾配を生成し、各 GPU はそれをパラメーター テーブルに適用します。この平均化のプロセスは all-reduce 処理としても知られています。
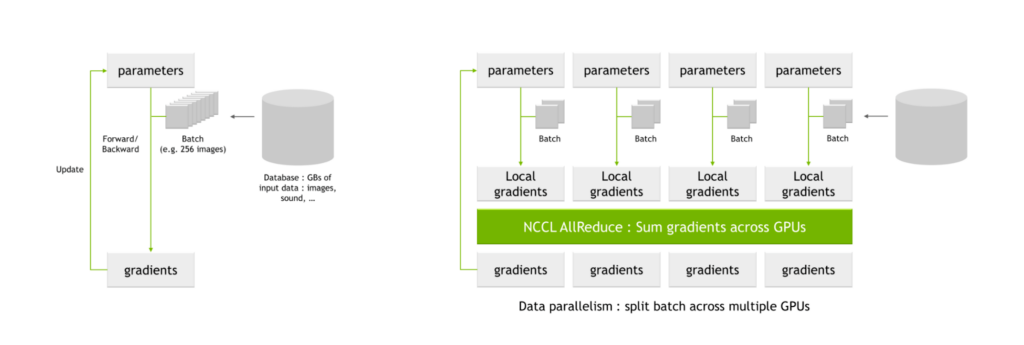
NVIDIA Magnum IO は、マルチ GPU およびマルチノード通信を高速化するデータ センター IO 向けのアーキテクチャです。これにより、HPC、AI、科学アプリケーションは、NVLink と NVSwitch を使用して拡張された新しく大規模な GPU クラスター上でパフォーマンスを拡大することができます。
Magnum IO には、NVIDIA Collective Communication Library (NCCL) が含まれており、all-reduce を含む、マルチ GPU、マルチノードのコレクティブ プリミティブを豊富に実装しています。
NCCL AllReduce は、ローカル勾配を入力とし、それをサブセットに分割し、あるレベルのサブセットをすべて集め、それを 1 つの GPU に割り当てます。そして、GPU はそのサブセットに対して、すべての GPU からのローカル勾配値間の合計などの照合処理を実行します。
このプロセスの後、グローバルな勾配セットが生成され、他のすべての GPU に配布されます。
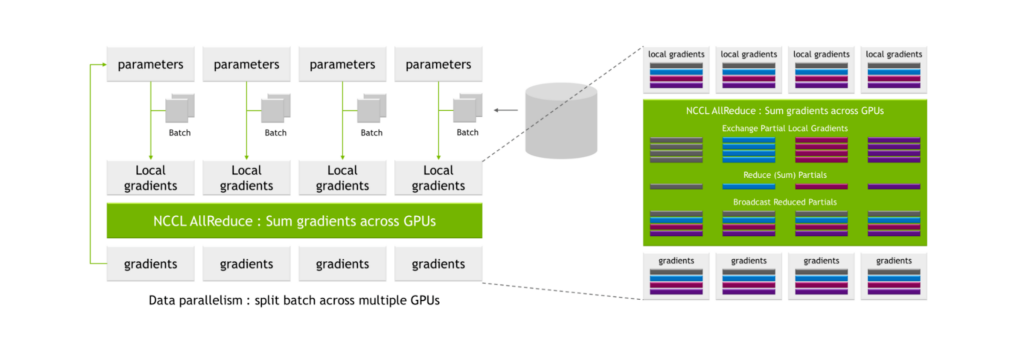
これらのプロセスは非常に通信負荷が高く、関連する通信オーバーヘッドにより、トレーニングに要する時間が大幅に長くなってしまうことがあります。
NVIDIA A100 Tensor コア GPU、第 3 世代 NVLink、第 2 世代 NVSwitch では、パーシャルの送受信のプロセスで 2N の読み取りが生じます (N は GPU の数です)。結果をブロードキャストする処理では、各 GPU インターフェイスで 2N 回の読み出しと 2N 回の書き込み、つまり合計 4N 回の処理が発生します。
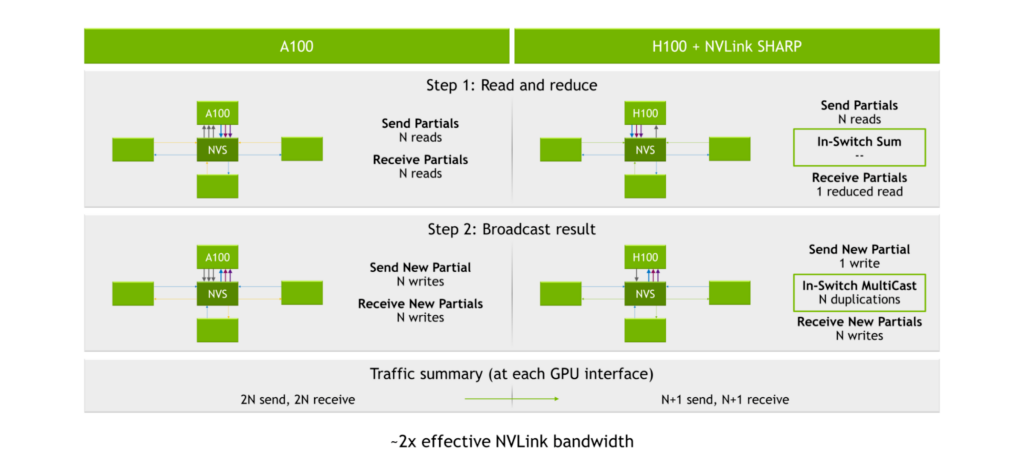
SHARP のエンジンは、第 3 世代 NVSwitch の中に入っています。データを各 GPU に分配して GPU に計算させるのではなく、GPU はデータを第 3 世代 NVSwitch チップに送ります。そして、チップは計算を実行し、その結果を送り返します。この結果、合計 2N+2 回の処理、つまり all-reduce 処理に必要な読み書き回数を約半分にすることができました。
大規模モデルのパフォーマンスを向上
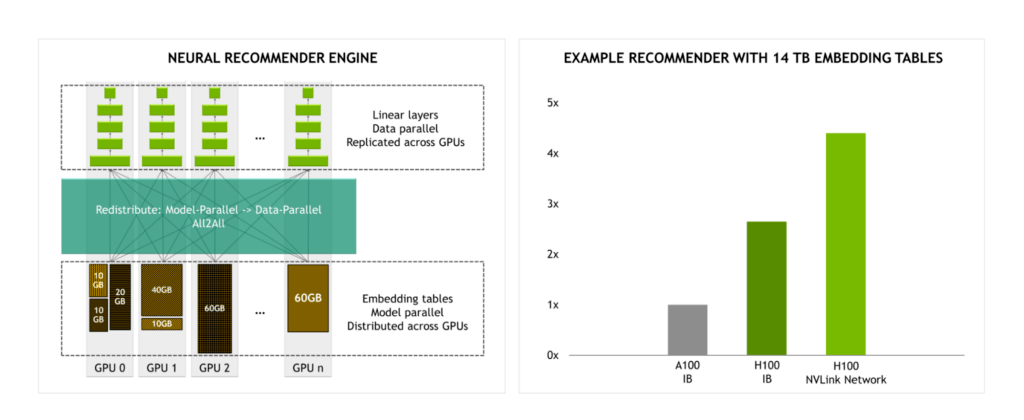
InfiniBand の 4.5 倍の帯域幅を持つ NVLink Switch System により、大規模なモデル トレーニングがより現実的なものになります。
例えば、14 TB の埋め込みテーブルを持つレコメンデーション エンジンを学習させる場合、InfiniBand を使う H100 と比較して、NVLink Switch System を使う H100 では、大幅な性能アップが期待できます。
NVLink Network
前世代の NVLink では、各サーバーは、サーバー内の GPU が NVLink を介して互いに通信する際に使用する独自のローカル アドレス空間を持っていました。NVLink Network では、各サーバーが独自のアドレス空間を持ち、GPU がネットワークを介してデータを送信するときに使用されるため、データを共有するときに分離とセキュリティの向上が実現します。この機能は、最新の NVIDIA Hopper GPU アーキテクチャに組み込まれた機能を活用しています。
NVLink がシステム ブートのプロセス中に接続設定を行うのに対し、NVLink Network の接続設定は、ソフトウェアによるランタイム API の呼び出しで行われます。これにより、異なるサーバーがオンラインになったり、ユーザーが出入りするたびに、その場でネットワークを再設定することができます。
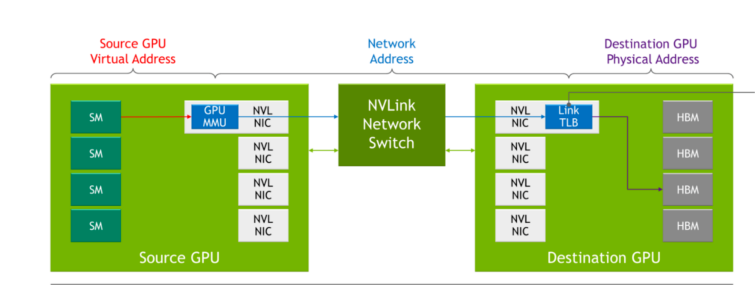
表 1 は、従来のネットワーク概念と NVLink Network の対応関係を示したものです。
| 概念 | 従来の例 | NVLink Network |
| 物理層 | 400G 電気/光メディア | カスタム FW OSFP |
| データリンク層 | イーサネット | NVLink カスタム オンチップ HW および FW |
| ネットワーク層 | IP | 新しい NVLink Network アドレスと管理プロトコル |
| トランスポート層 | TCP | NVLink カスタム オンチップ HW および FW |
| セッション層 | ソケット | SHARP groupsCUDA によるデータ構造のネットワーク アドレスのエクスポート |
| プレゼンテーション層 | TSL/SSL | ライブラリの抽象化 (例: NCCL、NVSHMEM) |
| アプリケーション層 | HTTP/FTP | AI フレームワークまたはユーザー アプリ |
| ネットワーク インターフェイス カード (NIC) | PCIe NIC (カードまたはチップ) | GPU と NVSwitch に組み込まれた機能 |
| RDMA オフロード | NIC オフロード エンジン | GPU 内蔵コピー エンジン |
| コレクティブ オフロード | NIC/スイッチ オフロード エンジン | NVSwitch 内蔵 SHARP エンジン |
| セキュリティ オフロード | NIC のセキュリティ機能 | GPU 内蔵暗号化および “TLB” ファイアウォール |
| メディア コントロール | NIC ケーブルのアダプテーション | NVSwitch 内蔵 OSFP ケーブル コントローラー |
DGX H100
NVIDIA DGX H100 は、最新の NVIDIA H100 Tensor コア GPU をベースにした DGX ファミリ製品の最新版システムで、以下が組み込まれています。
- GPU メモリ総計 640GB の NVIDIA H100 Tensor コア GPU x8
- 第 3 世代 NVIDIA NVSwitch チップ x4
- NVLink Network OSFP x18
- 3.6 TB/秒の全二重 NVLink Network 帯域幅を 72 本の NVLink で提供
- NVIDIA ConnectX-7 Ethernet/InfiniBand ポート x8
- デュアルポート BlueField-3 DPU x2
- デュアル Sapphire Rapids CPU
- PCIe Gen5 のサポート
全帯域幅のサーバー内 NVLink
DGX H100 内では、システム内の 8 基の H100 Tensor コア GPU のそれぞれが、4 つの第 3 世代 NVSwitch チップすべてに接続されています。トラフィックは 4 つの異なるスイッチ プレーンを介して送信され、リンクを集約して、システム内の GPU 間で完全な全帯域幅を実現することができます。
半帯域幅 NVLink Network
NVLink Network を使用すると、サーバー内の 8 基すべての NVIDIA H100 Tensor コア GPU が、他のサーバー内の H100 Tensor コア GPU に 18 本の NVLink の半分を使うことができます。
あるいは、サーバー内の 4 基の H100 Tensor コア GPU は、他のサーバー内の H100 Tensor コア GPU に 18 本の NVLink を完全に使うことができます。この 2:1 の減少は、サーバーの複雑さと、技術を具体化するためのコストを考慮し、帯域幅のバランスを取るために行われたトレードオフです。
SHARP では、全帯域の AllReduce と同等の帯域幅を提供します。
マルチレイル イーサネット
サーバー内では、8 基の GPU がそれぞれ専用の 400 GB NIC から独立して RDMA をサポートしています。NVLink Network 以外のデバイスに対して、800 GB/s の全二重集約帯域幅が可能です。
DGX H100 SuperPOD
DGX H100 は、DGX H100 SuperPOD の構成要素です。
- 4 台の DGX H100 サーバーを搭載した 8 台のコンピューティング ラックで構成されています。
- 合計 32 台の DGX H100 ノードを搭載し、256 基の NVIDIA H100 Tensor コア GPU を内蔵しています。
- ピーク時で最大 1 エクサフロップの AI コンピューティングを実現。
NVLink Network は、256 基の GPU 全体にわたって 57.6 TB/s のバイセクション帯域幅を提供します。さらに、32 台の DGX すべてにわたる ConnectX-7 と関連する InfiniBand スイッチにより、ポッド内または複数の SuperPOD のスケールアウトに使用する 25.6 TB/s の全二重帯域幅が提供されます。
NVLink Switch
DGX H100 SuperPOD の重要な実現要素は、第 3 世代の NVSwitch チップをベースにした新しい NVLink Switch です。DGX H100 SuperPOD には、18 台の NVLink Switch が搭載されています。
NVLink Switch は、InfiniBand スイッチの設計を大幅に活用して、標準的な 1U 19 インチのフォーム ファクターに収まり、32 個の OSFP ケージを搭載しています。各スイッチには、2 つの第 3 世代 NVSwitch チップが組み込まれ、128 個の第 4 世代 NVLink ポートを提供し、合計 6.4 TB/s の全二重帯域幅を実現しています。
NVLink Switch は、帯域外の管理通信と、パッシブ カッパーなどのさまざまなケーブル オプションをサポートしています。カスタム ファームウェアを使用すれば、アクティブ カッパーや光 OSFP ケーブルもサポートされます。
NVLink Network でスケールアップ
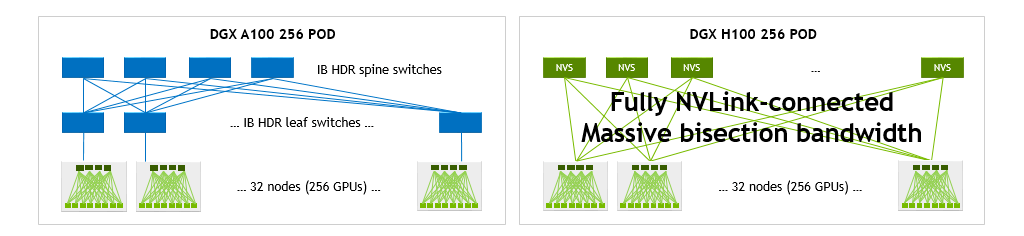
H100 SuperPOD with NVLink Network は、DGX A100 で GPU を 256 基搭載した DGX A100 SuperPOD と比較して、バイセクションとリダクション処理の帯域幅の大幅な増加を実現します。
DGX H100 は、DGX A100 と比較して、バイセクションで 1.5 倍、リダクション処理で 3 倍の帯域幅を実現します。これらの高速化は、合計 256 基の GPU を搭載した 32 台の DGX システム構成では、それぞれ 9 倍と 4.5 倍まで拡大します。
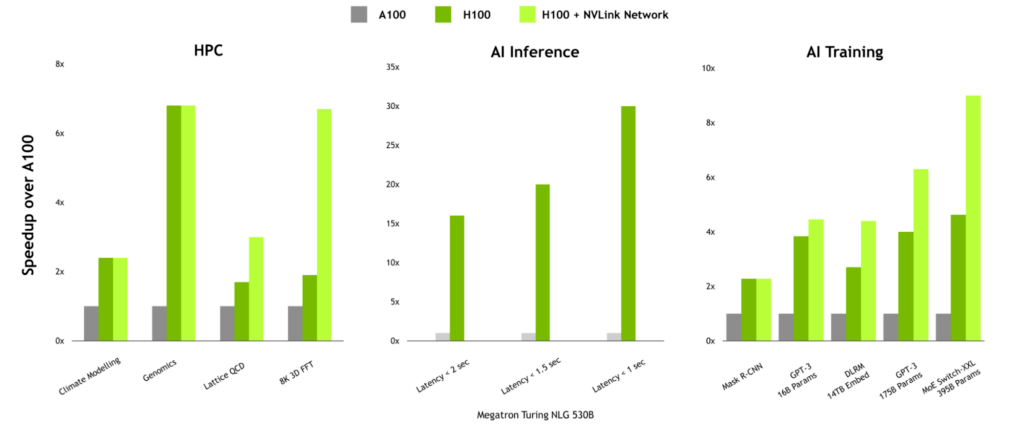
通信負荷の高いワークロードに対する性能上のメリット
通信量が多いワークロードでは、NVLink Network の性能上の利点が大きくなる可能性があります。HPC では、HPC SDK および Magnum IO 内の通信ライブラリにマルチノード スケーリングが設計されているため、Lattice QCD や 8K 3D FFT などのワークロードに大きな利点があります。
また、NVLink Network は、大規模な言語モデルや大きな埋め込みテーブルを持つレコメンダーを学習する際にも、大きな効果を発揮します。
スケールアップしたパフォーマンスを実現する
AI と HPC に最高のパフォーマンスを提供するには、フルスタック、データ センター規模のイノベーションが必要です。高帯域幅、低遅延のインターコネクト テクノロジは、スケールアップしたパフォーマンスを実現するための重要な要素です。
第 3 世代の NVSwitch は、サーバー内の GPU 間の広帯域、低遅延な通信を実現するとともに、サーバーとノード間で NVLink のフル速度による GPU 間通信を実現するための次の大きな飛躍をもたらします。
Magnum IO は、CUDA、HPC SDK、およびほぼすべてのディープラーニング フレームワークと統合的に動作します。これにより、大規模な言語モデル、レコメンダー システム、3D FFT などの科学アプリケーションなどの AI ソフトウェアを、NVLink スイッチ システムを使用して複数のノードにある複数の GPU にわたって、すぐに拡張することができます。
詳細については、NVIDIA NVLink および NVSwitch を参照してください。
翻訳に関する免責事項
この記事は、「Upgrading Multi-GPU Interconnectivity with the Third-Generation NVIDIA NVSwitch」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。