
金融サービスでは、ポートフォリオ マネージャーやリサーチ アナリストが膨大な量のデータを丹念に精査し、投資で競争力を高めています。情報に基づいた意思決定を行うには、最も関連性の高いデータにアクセスし、そのデータを迅速に統合して解釈する能力が必要です。
従来、セルサイド アナリストやファンダメンタル ポートフォリオ マネージャーは、財務諸表、収益報告、企業提出書類を綿密に調べ、一部の企業に焦点を当ててきました。より広範な取引対象範囲にわたって財務文書を体系的に分析することで、さらなる洞察を得ることができます。このようなタスクは技術的およびアルゴリズム的に難しいため、広範な取引対象範囲にわたるトランスクリプトの体系的な分析は、最近まで、高度なクオンツ トレーディング (quant-trading) 会社にしかできませんでした。
これらのタスクで、バッグオブワード、感情辞書、単語統計などの従来の自然言語処理 (NLP) 手法を使用して達成されるパフォーマンスは、金融 NLP タスクにおける大規模言語モデル (LLM) の機能と比較すると、しばしば不十分です。金融アプリケーション以外にも、LLM は医療文書の理解、ニュース記事の要約、法的文書の検索などの分野で優れたパフォーマンスを発揮しています。
AI と NVIDIA のテクノロジを活用することで、セルサイド アナリスト、ファンダメンタル トレーダー、リテール トレーダーはリサーチ ワークフローを大幅に加速し、金融文書からより微妙な洞察を抽出し、より多くの企業や業界をカバーできます。これらの高度な AI ツールを導入することで、金融サービス部門はデータ分析機能を強化し、時間を節約し、投資決定の精度を向上させることができます。NVIDIA の 2024 年金融サービスにおける AI の現状調査レポートによると、回答者の 37% (中国を除く) が、反復的な手作業を減らすために、レポート生成、統合合成、投資調査のための生成 AI と LLM を検討しています。
この記事では、NVIDIA NIM 推論マイクロサービスを使用して収益報告のトランスクリプトから洞察を抽出する AI アシスタントを構築し、検索拡張生成 (RAG) システムを実装する方法について、エンドツーエンドのデモで説明します。高度な AI テクノロジを活用することで、ワークフローを加速し、隠れた洞察を明らかにし、最終的に金融サービス業界の意思決定プロセスを強化する方法を紹介します。
NIM による収益報告の記録の分析
特に、決算発表の電話会議は投資家やアナリストにとって重要な情報源であり、企業が重要な財務情報や事業情報を伝達するプラットフォームを提供します。これらの電話会議は、業界、企業の製品、競合他社、そして最も重要な事業見通しについての洞察を提供します。
決算発表の電話会議の記録を分析することで、投資家は企業の将来の収益と評価に関する貴重な情報を収集できます。決算発表の電話会議の記録は、20 年以上にわたってアルファを生み出すために効果的に使用されてきました。詳細については、「自然言語処理 – パート I: 入門」(2017 年 9 月) および「自然言語処理 – パート II: 銘柄選択」(2018 年 9 月)を参照してください。
ステップ 1: データ
このデモでは、2016 年から 2020 年までの NASDAQ の収益報告のトランスクリプトを分析に使用します。この収益報告のトランスクリプト データセットは、Kaggle からダウンロードできます。
評価では、10 社のサブセットを使用し、そこから 63 件のトランスクリプトをランダムに選択して手動で注釈を付けました。すべてのトランスクリプトについて、次の一連の質問に答えました:
- 会社の主な収益源は何ですか。過去 1 年間でどのように変化しましたか?
- 会社の主なコスト要素は何ですか。報告期間中にどのように変動しましたか?
- どのような設備投資が行われ、それがどのように会社の成長を支えていますか?
- どのような配当または株式買い戻しが実行されましたか?
- トランスクリプトで言及されている重要なリスクは何ですか?
これにより、合計 315 の質問と回答のペアが作成されます。すべての質問への回答は、構造化された JSON フォーマットを使用して行われます。
たとえば:
質問: 会社の主な収入源は何ですか? また、過去 1 年間でどのように変化しましたか? (What are the company’s primary revenue streams and how have they changed over the past year?)
回答:
{
"Google Search and Other advertising": {
"year_on_year_change": "-10%",
"absolute_revenue": "21.3 billion",
"currency": "USD"
},
"YouTube advertising": {
"year_on_year_change": "6%",
"absolute_revenue": "3.8 billion",
"currency": "USD"
},
"Network advertising": {
"year_on_year_change": "-10%",
"absolute_revenue": "4.7 billion",
"currency": "USD"
},
"Google Cloud": {
"year_on_year_change": "43%",
"absolute_revenue": "3 billion",
"currency": "USD"
},
"Other revenues": {
"year_on_year_change": "26%",
"absolute_revenue": "5.1 billion",
"currency": "USD"
}
} JSON を使用すると、評価に望ましくないバイアスを導入する可能性のある「 LLM 断言」などの主観的な言語理解方法に依存せずにモデルのパフォーマンスを評価できます。
ステップ 2: NVIDIA NIM
このデモでは、エンタープライズ生成 AI の導入を高速化するために設計されたマイクロサービス セットである NVIDIA NIM を使用します。詳細については、「NVIDIA NIM は AI モデルの大規模な導入向けに最適化された推論マイクロサービスを提供します」を参照してください。
NVIDIA 向けに最適化されたコミュニティ モデルや商用パートナー モデルなど、幅広い AI モデルをサポートする NIM は、業界標準の API を活用して、オンプレミスまたはクラウドでシームレスでスケーラブルな AI 推論を実現します。実稼働の準備ができたら、NIM は 1 つのコマンドで導入され、標準 API とわずか数行のコードを使用してエンタープライズ グレードの AI アプリケーションに簡単に統合できます。NVIDIA TensorRT、TensorRT-LLM、PyTorch などの推論エンジンを含む堅牢な基盤上に構築された NIM は、基盤となるハードウェアに基づいてすぐに最高のパフォーマンスでシームレスな AI 推論を実現するように設計されています。NIM を使用したセルフホスティング (self-hosting) モデルは、RAG アプリケーションで一般的な要件である顧客データと企業データの保護をサポートします。
ステップ 3: NVIDIA API カタログでの設定
NIM には、NVIDIA API カタログを使用してアクセスできます。設定に必要なのは、NVIDIA API キーを登録することだけです (API カタログから、[API キーの取得] をクリックします)。この記事では、これを環境変数に保存します。
export NVIDIA_API_KEY=YOUR_KEYLangChain は、便利な NGC 統合用のパッケージを提供しています。このチュートリアルでは、エンドポイントを使用して、NIM で埋め込み、リランキング、チャット モデルを実行します。コードを再現するには、次の Python 依存関係をインストールする必要があります。
langchain-nvidia-ai-endpoints==0.1.2
faiss-cpu==1.7.4
langchain==0.2.5
unstructured[all-docs]==0.11.2ステップ 4: NIM を使用した RAG パイプラインの構築
RAG は、大規模なコーパスからの関連文書の取得とテキスト生成を組み合わせることで言語モデルを強化する方法です。
RAG の最初のステップは、文書のコレクションをベクトル化することです。これには、一連の文書を取得し、それらを小さなチャンクに分割し、埋め込みモデルを使用してこれらの各チャンクをニューラル ネットワーク埋め込み (ベクトル) に変換し、ベクトル データベースに保存することが含まれます。各収益報告通話のトランスクリプトに対してこれらの操作を実行します。
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
# Initialise the embedder that converts text to vectors
transcript_embedder = NVIDIAEmbeddings(model='nvidia/nv-embed-v1',
truncate='END'
)
# The document we will be chunking and vectorizing
transcript_fp = "Transcripts/GOOGL/2020-Feb-03-GOOGL.txt"
raw_document = TextLoader(transcript_fp).load()
# Split the document into chunks of 1500 characters each
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000,
chunk_overlap=200)
documents = text_splitter.split_documents(raw_document)
# Vectorise each chunk into a separate entry in the database
vectorstore = FAISS.from_documents(documents, transcript_embedder)
vector_store_path = "vector_db/google_transcript_2020_feb.pkl"
try:
os.remove(vector_store_path)
except OSError:
pass
vectorstore.save_local(vector_store_path)ベクトル化されたデータベースが構築されると、収益報告の記録の最も単純な RAG フローは次のようになります。
- ユーザーがクエリ (query) を入力します。たとえば、「会社の主な収益源は何ですか?」(What are the company’s main revenue sources?)
- 埋め込みモデル (embedder) はクエリをベクトルに埋め込み、ドキュメントのベクトル化されたデータベースを検索して、最も関連性の高い上位 K (例えば、上位 30 など) のチャンクを探します。
- 次に、クロスエンコーダーとも呼ばれるリランキング (reranker) モデルが、クエリとドキュメントの各ペアの類似性スコアを出力します。さらに、メタデータを使用して、再ランク付けステップの精度を向上させることもできます。このスコアは、埋め込みによって取得された上位 K のドキュメントを、ユーザー クエリとの関連性で並べ替えるために使用されます。その後、さらにフィルタリングを適用して、上位 N (例えば、上位 10 など) のドキュメントのみを保持できます。
- 次に、最も関連性の高い上位 N のドキュメントが、ユーザークエリとともに LLM に渡されます。取得されたドキュメントは、モデルの回答を基盤付けるコンテキストとして使用されます。
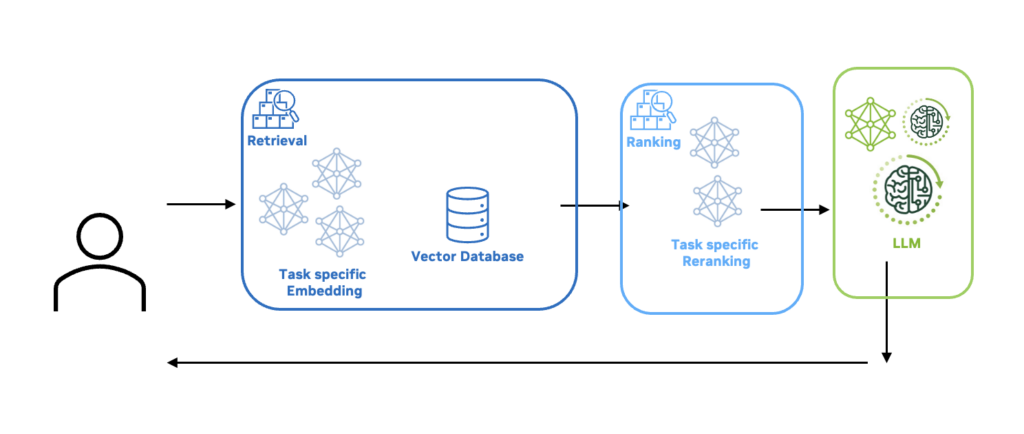
モデルの回答精度を向上させるために変更を加えることもできますが、今のところは最もシンプルで堅牢なアプローチを続けます。
次のユーザー クエリと必要な JSON フォーマットを検討してください。
question = "What are the company’s primary revenue streams and how have they changed over the past year?"
# 会社の主な収入源は何ですか? また、過去 1 年間でどのように変化しましたか?
json_template = """
{"revenue_streams": [
{
"name": "<Revenue Stream Name 1>",
"amount": <Current Year Revenue Amount 1>,
"currency": "<Currency 1>",
"percentage_change": <Change in Revenue Percentage 1>
},
{
"name": "<Revenue Stream Name 2>",
"amount": <Current Year Revenue Amount 2>,
"currency": "<Currency 2>",
"percentage_change": <Change in Revenue Percentage 2>
},
// Add more revenue streams as needed
]
}
"""
user_query = question + json_template JSON テンプレートは、パイプラインのさらに先で、LLM がプレーン テキストではなく有効な JSON フォーマットで回答を出力することを認識できるように使用されます。ステップ 1 で述べたように、JSON を使用すると、客観的な方法でモデル回答を自動的に評価できます。より「会話的なスタイル」が望ましい場合は、これを削除できることに注意してください。
ユーザー クエリをコンテキスト化するには、関連するドキュメントを取得して順序付けするために、Embedder (埋め込みモデル) と Reranker (リランキングモデル) を初期化します:
from langchain_nvidia_ai_endpoints import NVIDIARerank
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
# 1 How many retrieved documents to keep at each step, 各ステップで取得されたドキュメントをいくつ保存するかの設定:
top_k_documents_retriever = 30
top_n_documents_reranker = 5
# 2 Initialize retriever for vector database, ベクトルデータベースの取得を初期化する:
retriever = vectorstore.as_retriever(search_type='similarity',
search_kwargs={'k': top_k_documents_retriever})
# 3 Add a reranker to reorder documents by relevance to user query, ユーザークエリとの関連性に基づいてドキュメントを並べ替えるリランキング機能を追加する:
reranker = NVIDIARerank(model="ai-rerank-qa-mistral-4b",
top_n=top_n_documents_reranker)
retriever = ContextualCompressionRetriever(base_compressor=reranker,
base_retriever=retriever)
# 4 Retrieve documents, rerank them and pick top-N, ドキュメントを取得し、リランキングして上位Nを選択する:
retrieved_docs = retriever.invoke(user_query)
# 5 Join all retrieved documents into a single string, 取得したすべてのドキュメントを1つの文字列に結合する:
context = ""
for doc in retrieved_docs:
context += doc.page_content + "\n\n"次に、関連するドキュメントが取得されると、ユーザー クエリとともに LLM に渡されます。ここでは、Llama 3 70B NIM を使用しています。
from langchain_nvidia_ai_endpoints import ChatNVIDIA
PROMPT_FORMAT = """"
Given the following context:
####################
{context}
####################
Answer the following question:
{question}
using the following JSON structure:
{json_template}
For amounts don't forget to always state if it's in billions or millions and "N/A" if not present.
Only use information and JSON keys that are explicitly mentioned in the transcript.
If you don't have information for any of the keys use "N/A" as a value.
Answer only with JSON. Every key and value in the JSON should be a string.
"""
llm = ChatNVIDIA(model="ai-llama3-70b",
max_tokens=600,
temperature=0
)
llm_input = PROMPT_FORMAT.format(**{"context": context,
"question": question,
"json_template": json_template
})
answer = llm.invoke(llm_input)
print(answer.content)このコードを実行すると、ユーザー クエリに対する JSON 構造の回答が生成されます。コードを簡単に変更して、複数のトランスクリプトを読み込んでさまざまなユーザー クエリに回答できるようになりました。
ステップ 5: 評価
検索ステップのパフォーマンスを評価するには、前述の注釈付きの質問と回答のペアを使用して、真実の JSON と予測された JSON をキーごとに比較します。次の真実の例を考えてみましょう。
"Google Cloud": {
"year_on_year_change": "43%",
"absolute_revenue": "3 billion",
"currency": "N/A"
}予測の出力は次のようになります:
"Google Cloud": {
"year_on_year_change": "43%",
"absolute_revenue": "N/A",
"currency": "USD"
}考えられる出力の評価結果は 3 つあります。
- 真陽性 (TP, True Positive): 参考の答えと予測が一致しています。前の例では、
year_on_year_changeの予測 (“43%”) は TP です。
- 偽陽性 (FP, False Positive): 参考の答えの値は
"N/A"です。つまり、抽出する値はありませんが、予測では値が幻覚的に表示されます。前の例では、currencyの予測 (“USD”) は FP です。
- 偽陰性 (FN, False Negative): 抽出する参考の答えの値がありますが、予測ではその値を取得できませんでした。前の例では、
absolute_revenueの予測 (“N/A”) は FP です。
これらの結果を測定したら、次に、次の 3 つの主要なメトリックを計算します。
- 再現率 (Recall) = TP/ (TP + FN): 再現率が高いほど、モデルが関連する結果をより多く返していることを意味します。
- 精度 (Precision) = TP / (TP + FP): 精度が高いほど、モデルが関連する結果と無関係な結果の比率が高くなっていることを意味します。
- F1 スコア (F1-score) = (2 * 適合率 * 再現率) / (適合率 + 再現率): F1 スコアは、適合率と再現率の調和平均です。
ユーザーは、一部の属性について文字列比較を行う際に、数値以外の値のマッチングを部分的に柔軟にしたい場合があります。たとえば、収益源に関する質問を考えてみましょう。ここで、参考の回答の 1 つが複数形の「データ センター」(“Data Centers”) で、モデルが単数形の「データ センター」(“Data Center”)を出力します。完全一致評価では、これは「不一致」として扱われます。このような場合に、より堅牢な評価を実現するには、Python のデフォルトの difflib でファジー マッチング (fuzzy matching) を使用します。
import difflib
def get_ratio_match(gt_string, pred_string):
if len(gt_string) < len(pred_string):
min_len = len(gt_string)
else:
min_len = len(pred_string)
matcher = difflib.SequenceMatcher(None, gt_string, pred_string, autojunk=False)
_, _, longest_match = matcher.find_longest_match(0, min_len, 0, min_len)
# Return the ratio of match with ground truth
return longest_match / min_len評価では、類似度が 90% を超える文字列属性は一致していると見なします。
表 1 は、手動で注釈を付けたデータに対する、最もよく使用される 2 つのオープンソース モデル ファミリ (Mistral AI Mixtral モデルと Meta Llama 3 モデル) の結果を示しています。どちらのモデル ファミリでも、パラメーターの数を減らすとパフォーマンスが著しく低下します。これらの NIM を体験するには、NVIDIA API カタログにアクセスしてください。
| Method | F1 | Precision | Recall |
| Llama 3 70B | 84.4% | 91.3% | 78.5% |
| Llama 3 8B | 75.8% | 85.2% | 68.2% |
| Mixtral 8x22B | 84.4% | 91.9% | 78.0% |
| Mixtral 8x7B | 62.2% | 80.2% | 50.7% |
Mixtral-8x22B は、Llama 3 70B とほぼ同等のパフォーマンスを持っているようです。ただし、どちらのモデル ファミリでも、パラメーターの数を減らすとパフォーマンスが大幅に低下します。低下は Recall で最も顕著です。これは、ハードウェア要件の増加を犠牲にして精度を向上させることを選択するというトレードオフを頻繁に示しています。
ほとんどの場合、ドメイン固有のデータ (この場合は、収益通話のトランスクリプト) を使用して、Embedder、Reranker、または LLM のいずれかを微調整することで、パラメーターの数を増やすことなくモデルの精度を向上させることができます。
Embedder は最も小さいため、微調整が最も迅速かつコスト効率に優れています。詳細な手順については、NVIDIA NeMo のドキュメントを参照してください。さらに、NVIDIA NeMo は、LLM の有効なバージョンを微調整する効率を簡素化し、強化します。
ユーザー向け重要な意味合い
このデモは、収益報告の記録から洞察を抽出するように設計されています。NIM などの高度な AI テクノロジを活用することで、収益報告の記録から情報を迅速かつ正確に取得できるようになりました。AI 製品は、文書化とデータ分析の最も集中的なプロセス中に、複数のカテゴリの金融研究者、アナリスト、アドバイザー、ファンダメンタル ポートフォリオ マネージャーを支援し、金融専門家が戦略的な意思決定や顧客対応に多くの時間を費やせるようにします。
たとえば、資産管理セクターでは、ポートフォリオ マネージャーはアシスタントを使用して、膨大な数の収益報告から洞察をすばやく統合し、投資戦略と結果を改善できます。保険業界では、AI アシスタントが企業レポートから財務の健全性とリスク要因を分析し、引受とリスク評価のプロセスを強化できます。ファンダメンタル トレーディングと小売取引では、アシスタントが体系的な情報抽出を支援して市場のトレンドと感情の変化を特定し、将来の取引でより詳細な情報を使用できるようにします。
銀行でも、収益報告を分析することで、潜在的なローン受領者の財務安定性を評価するために使用できます。最終的に、このテクノロジーは効率、精度、データに基づく意思決定能力を高め、ユーザーにそれぞれの市場での競争上の優位性をもたらします。
NVIDIA API カタログにアクセスして、利用可能なすべての NIM を確認し、LangChain の便利な統合を試して、自分のデータに最適なものを味見してください。
関連情報
- GTC セッション: SQL からチャットへ: NVIDIA でエンタープライズ データ分析を変革する方法
- NGC コンテナー: DiffDock
- NGC コンテナー: NMT Megatron Riva 1b
- ウェビナー: 資本市場における次世代分析: 取引実行とリスク管理
- ウェビナー: 金融サービス向けの大規模な AI モデル推論の加速