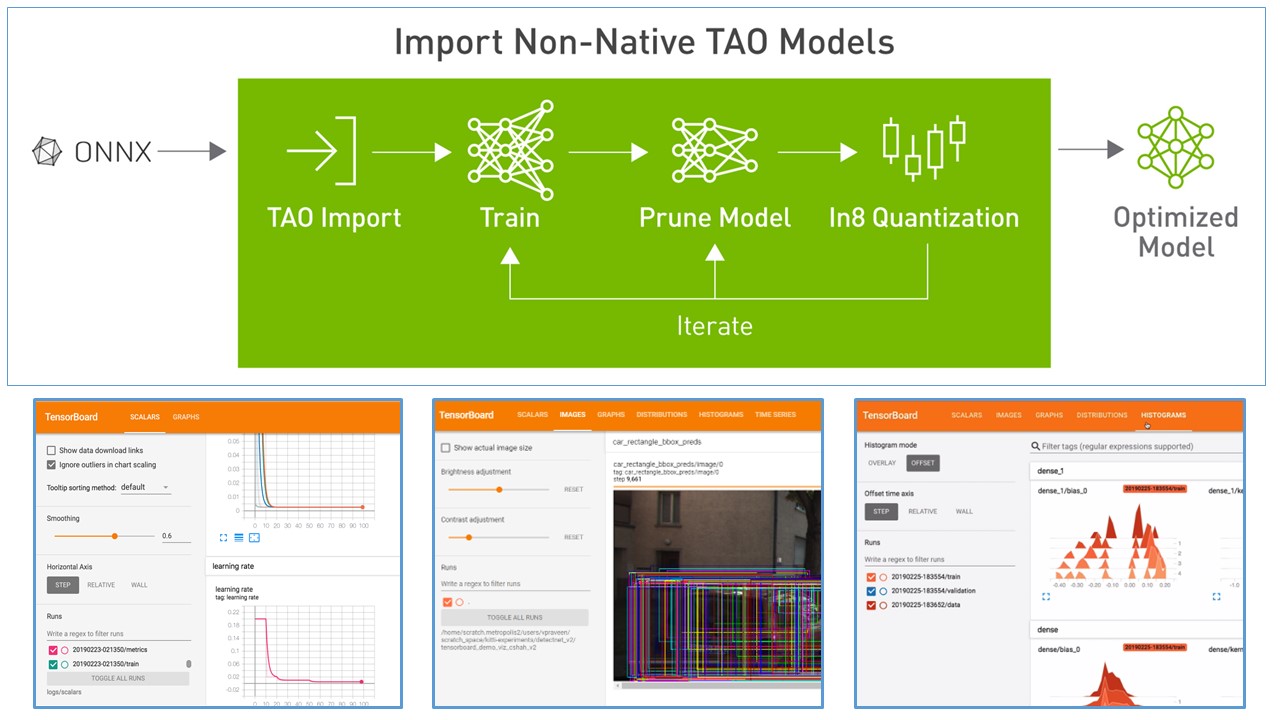
NVIDIA TAO Toolkit (以下: TAO) は Deep Learning モデルの学習を容易にし、枝刈り、量子化によって高速なモデルを提供可能にする機能をもっているソフトウェアです。
この記事は 2022 年 6 月のアップデートで導入されたモデルの重み持ち込みと TensorBoard による可視化について記述します。
BYOM (Bring your own model) モデルの重みの持ち込み
モデルの重みの持ち込みを TAO 上では BYOM と記述します。Bring your own model の略称になります。
この機能によって他のフレームワークで学習された重みを TAO に持ち込むことができます。
TAO は NGC カタログに公開されている学習済みモデルを使用することができます。しかし公開されているモデルは人、車、動物のデータで学習されたケースが多く、ユース ケースにあっていないケースがあります。
PyTorch や TensorFlow フレームワークなどを用いて学習したモデルの重みがもしあれば、その重みを TAO 上に持ち込める機能が BYOM になります。
TAO 上に持ち込むことによって、量子化や枝刈りなどの推論時の高速化の恩恵を受けることができます。
BYOM UNET
ここからは BYOM の具体的な実行例を記述します。
こちらのリンクを参考にしています。
BYOM を行うためのレポジトリを取得します。
cd $HOME
git clone https://github.com/NVIDIA-AI-IOT/tao_byom_examples.git
cd tao_byom_examples/semantic_segmentationMinicondaで環境を作成します。
conda create -n byom_dev python=3.6
conda activate byom_devpipで依存性のあるライブラリをインストールします。
pip3 install -r requirements.txt --no-depsTAO の裏側で TensorFlow が動作しているので TensorFlow 関連のソフトウェアをインストールします。
pip3 install nvidia-pyindex
pip3 install nvidia-tensorflowNVIDIA TAO BYOM converter をインストールします。
pip3 install nvidia-tao-byomPyTorch モデルを ONNX フォーマットに変換
NVIDIA TAO BYOM converter は ONNX フォーマットに変換されたモデルを TAO のフォーマットに変換するため、まずONNX フォーマットに変換する必要があります。
PyTorch に存在するモデルを取得して ONNX フォーマットに変換するため、関連するライブラリをインストールします。
pip install torch torchvision segmentation_models_pytorchSegmentation_models.pytorch から提供される MobileNetv3 のモデルを ONNX フォーマットで出力します。
python export_smp.py -m mobilenetv3_unet_scratch --shape 512 --activation softmax作成された mobilenetv3_unet_scratch.onnx を ONNX モデルの可視化ができる netron で確認します。localhost:8080 でブラウザーにアクセスして確認します。(ポート番号は他のアプリケーションが使用している場合は変更されます。)
TAOでサポートしているレイヤーのみ ONNX 変換が可能です。サポートしているレイヤーはこちらを参照ください。この ONNX モデルの HardSigmoid はサポートされていないため、カスタム レイヤーが必要になります。
netron onnx_models/mobilenetv3_unet_scratch.onnx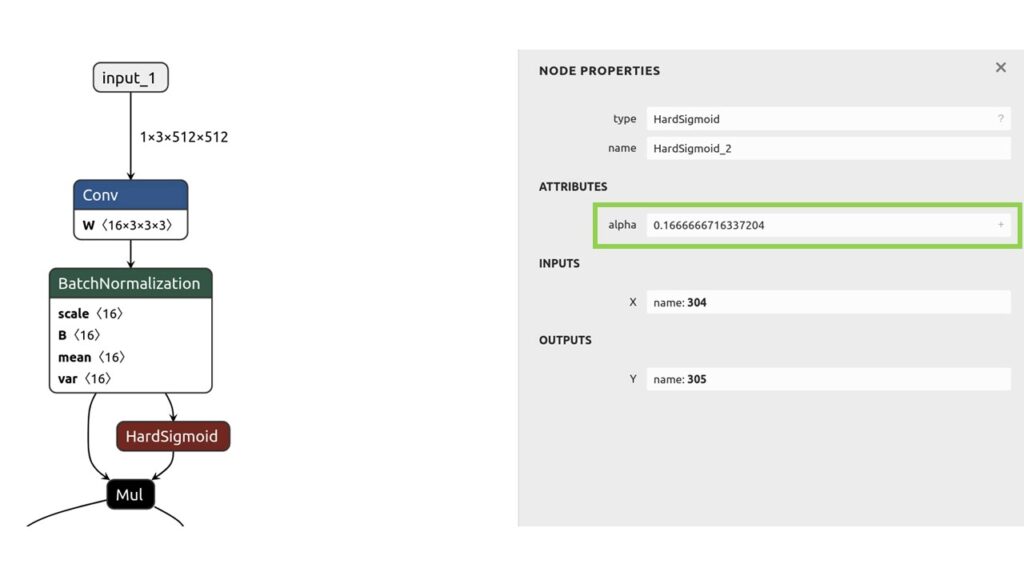
サポートされていないレイヤーは Keras 実装が必要です。
ONNX のドキュメンテーションと PyTorch のドキュメンテーションを確認すると alpha 値が0.2 (ONNX) と 0.167 (PyTorch) で異なるため、ハードシグモイド関数を実装する際に ONNX の値を設定する必要があります。Keras でレイヤーを実装する際は official documentation を参考に実装する必要があります。
TAO BYOM に登録する変換関数
mobilenetv3/user_generated_layer.py を用いて、ONNX ノードを Keras ノードに変換します。
下記ステップで動作します。
- ノードの必要な属性と入力を全て取得する
- ノードからの numpy 入力を TF テンソルに変換する
- ノードに対応する Keras レイヤーを呼び出す
- Keras レイヤーの出力を layers[node_name] に渡す
- ラムダ関数やカスタム Keras レイヤーを使用している場合は、lambda_func[node_name] で指定する
完了したら、mobilenetv3/custom_meta.json のファイル情報を更新します。
ハードシグモイド関数は下記実装を用います。
ONNX モデルから TAO フォーマットへの変換
mobilenetv3/custom_meta.json の ABS_TOP_DIR を下記のように修正する必要があります。
ABS_TOP_DIR:"<Your path>/tao_byom_examples/semantic_segmentation/mobilenetv3"下記コマンドで ONNX モデルを TAO フォーマットに変換します。
PYTHONPATH=${PWD} tao_byom -m onnx_models/mobilenetv3_unet_scratch.onnx -r results/mobilenetv3_unet_scratch -n mobilenetv3_unet_scratch_dagm -c mobilenetv3/custom_meta.json -k nvidia_tlt -p 531results/mobilenetv3_unet_scratch ディレクトリに.tltb フォーマットに変換されたモデルが保存されます。
変換されたモデルの使用方法
BYOM は画像分類とセグメンテーションモデルの UNET のみ現在サポートしています。将来的に物体検出モデルも対応予定です。
- BYOM Image Classification — TAO Toolkit 3.22.05 documentation
https://docs.nvidia.com/tao/tao-toolkit/text/byom/byom_classification.html - BYOM UNET — TAO Toolkit 3.22.05 documentation
https://docs.nvidia.com/tao/tao-toolkit/text/byom/byom_unet.html
TAO でモデルを学習する際に Spec ファイルと呼ばれる設定ファイルを用います。この Spec ファイルはモデルのハイパーパラメータやデータのパスなどを指定します。Spec ファイルに関してはこちらを参照ください。
変換したモデルを使用する際は Spec ファイルの arch を byom を設定し、byom_model に変換したモデルのパスを設定します。モデルのパスはローカルではなく Docker 内のパスを設定します。TAO は Docker を用いて動作しています。詳しくはこちらを参照ください。
model_config {
:
arch: "byom"
byom_model: <変換したモデルのパス>
:
}TensorBoard による可視化
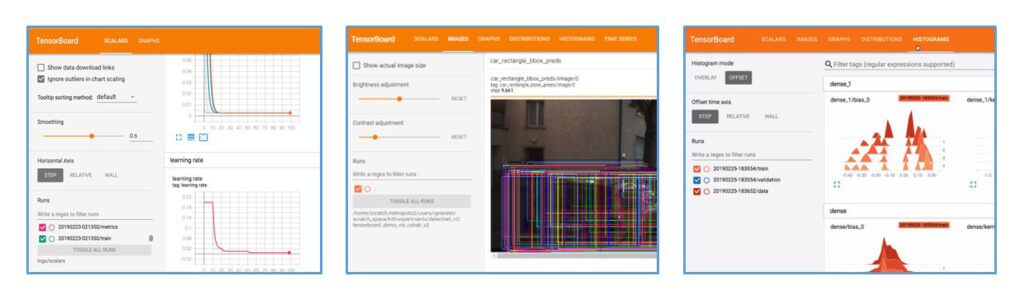
今回のアップデートでTensorBoardの可視化機能が追加されました。こちらのリンクで詳細確認できます。
- Loss と精度が確認できるようになり、オーバーフィッティングを防ぎやすくなりました。
- エポックごとの予測値を可視化することで学習を止めるタイミングを把握することができます。
- 重みのヒストグラムを可視化できるようになりました。一般的に学習後のニューラル ネットワークの重みの絶対値は小さな値におさまり、ReLU 活性化関数によって 0 付近の値が多くなる傾向があります。ヒストグラムによってこの傾向を確認できます。この性質によって学習の収束を確認するのに有効な情報になります。また重みのヒストグラムによって適切な枝刈りの閾値設定の参考になります。
- 参考:DSD: DENSE-SPARSE-DENSE TRAINING FOR DEEP NEURAL NETWORKS:https://arxiv.org/abs/1607.04381
Spec ファイルの training_config のセクションに下記設定を追加するだけで TensorBoard の可視化が有効になります。
training_config {
:
visualizer{
enabled: true
}
}下記コマンドで TensorBoard を起動し、localhost:8080 でブラウザーにアクセスして確認します。$RESULTS_DIR は TAO の学習の際に指定する出力ディレクトリです。(ポート番号は他のアプリケーションが使用している場合は変更する必要があります。)
tensorboard --logdir $RESULTS_DIR --host 0.0.0.0 --port 8080まとめ
TAO Toolkit 3.22.05 アップデートで導入された BYOM と TensorBoard の可視化を紹介しました。
BYOM により手持ちのモデルを TAO の枝刈りと量子化の恩恵により高速なモデルにすることが可能になり、学習時の状態を TensorBoard によって確認できるようになりました。
これらの機能がより高精度かつ高速な Deep Learning モデルの導入の助けになれば幸いです。
その他の資料については、以下のリンクをご覧ください。
- TAO Whitepaper (日本語):
https://developer.nvidia.com/ja-jp/tao-toolkit-usecases-whitepaper/1-introduction - TAO User Guide:
https://docs.nvidia.com/tao/tao-toolkit/index.html