
NVIDIA Grace Hopper Superchip アーキテクチャは、ハイパフォーマンス コンピューティング (HPC) と AI ワークロードのための、初の真のヘテロジニアス アクセラレーション プラットフォームです。GPU と CPU の両方の強みを活かしてアプリケーションを加速させるとともに、これまでで最もシンプルで生産性の高い分散型のヘテロジニアス プログラミング モデルを提供します。科学者やエンジニアは、世界で最も重要な問題の解決に集中することができます。
この記事では、Grace Hopper Superchip のすべてを学び、NVIDIA Grace Hopper が実現する画期的な性能に注目します。NVIDIA Hopper H100 GPU を使用した最も強力な PCIe ベースのアクセラレーション プラットフォームに対して Grace Hopper が達成した高速化の詳細については、NVIDIA Grace Hopper Superchip アーキテクチャのホワイトペーパーをご覧ください。
HPC や巨大な AI ワークロードを強力にスケーリングするための性能と生産性
NVIDIA Grace Hopper Superchip アーキテクチャは、NVIDIA Hopper GPU の画期的な性能と NVIDIA Grace CPU の汎用性を、高帯域かつメモリ一貫性を持つ NVIDIA NVLink Chip-2-Chip (C2C) で接続してスーパーチップを構成し、新しい NVIDIA NVLink Switch System にも対応します。
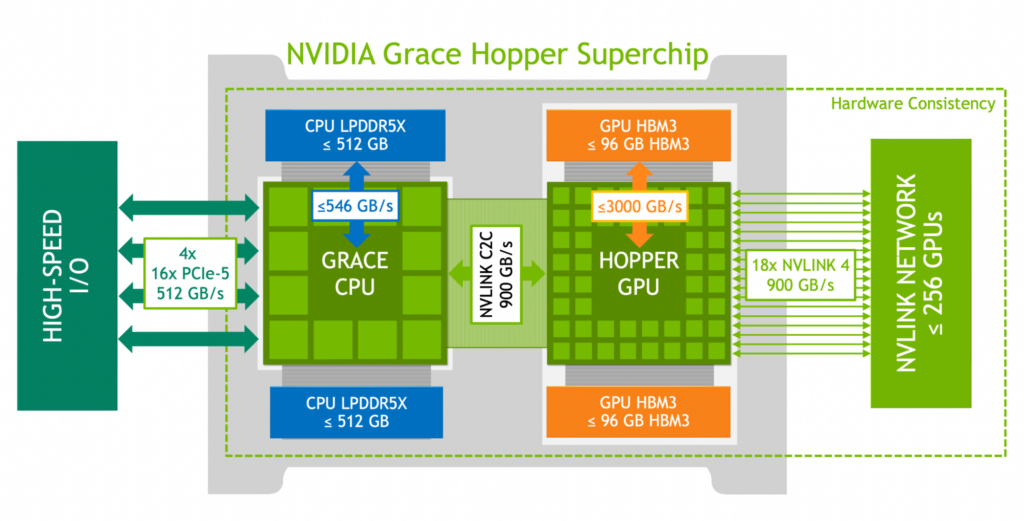
NVIDIA NVLink-C2C は、メモリ一貫性があり、高帯域、低遅延な NVIDIA のスーパーチップ インターコネクトです。Grace Hopper Superchip の心臓部であり、最大 900GB/s の総帯域幅を提供します。これは、高速化されたシステムで一般的に使用されている PCIe Gen5 x16 レーンよりも 7 倍高い帯域幅となります。
NVLink-C2C のメモリ一貫性は、開発者の生産性とパフォーマンスを向上させ、GPU が大量のメモリにアクセスできるようにします。CPU と GPU のスレッドは、CPU と GPU の両方のメモリに同時かつ透過的にアクセスできるようになり、明示的メモリ管理ではなく、アルゴリズムに集中できるようになりました。
メモリ一貫性により、ページ全体を GPU との間で移行することなく、必要なデータのみを転送することができます。また、CPU と GPU の両方からネイティブなアトミック操作を可能にすることで、GPU と CPU のスレッド間で軽量の同期プリミティブを実現します。Address Translation Services (ATS) を備えた NVLink-C2C は、NVIDIA Hopper Direct Memory Access (DMA) コピー エンジンを活用し、ホストとデバイス間のページング可能なメモリのバルク転送を加速させます。
NVLink-C2C は、アプリケーションが GPU のメモリをオーバーサブスクライブし、NVIDIA Grace CPU のメモリを高帯域幅で直接利用できるようにします。Grace Hopper Superchip ごとに最大 512 GBの LPDDR5X CPU メモリを搭載し、GPU は HBM を使用した場合に比べて 4 倍のメモリに直接高帯域幅でアクセスすることができます。NVIDIA NVLink Switch System と組み合わせることで、最大 256 個の NVLink 接続された GPU 上で動作する全ての GPU スレッドが、最大 150 TB のメモリに高帯域幅でアクセスできるようになりました。第 4 世代の NVLink は、ダイレクト ロード、ストア、アトミック操作を使用して相手のメモリにアクセスできるようにし、加速されたアプリケーションがこれまで以上に簡単により大きな問題を解決できるようにします。
NVIDIA のネットワーキング技術と共に、Grace Hopper Superchips は、次世代の HPC スーパーコンピューターと AI ファクトリーのためのレシピを提供します。お客様は、より大きなデータセット、より複雑なモデル、新しいワークロードを引き受け、以前よりも迅速に解決することができます。
NVIDIA Grace Hopper Superchip の主な技術革新は以下のとおりです。
- NVIDIA Grace CPU:
- Armv9.0-A ISA とコア当たり 4 × 128 ビット SIMD ユニットを持つ Arm Neoverse V2 コアを最大 72 個まで搭載可能。
- 最大 117 MBの L3 キャッシュを搭載。
- 最大 512 GB の LPDDR5X メモリを搭載し、最大 546GB/s のメモリ帯域幅を提供。
- 最大 64x PCIe Gen5 レーンを搭載。
- NVIDIA Scalable Coherency Fabric (SCF) 最大 3.2 TB/s のメモリ帯域幅を持つメッシュ型分散キャッシュ。
- CPU 毎に 1 つの NUMA ノードで高い開発生産性を実現。
- NVIDIA Hopper GPU:
- 第 4 世代Tensor コア、Transformer Engine、DPX 命令を備える最大 144 個の SM で、 NVIDIA A100 GPU と比較して 3 倍高い FP32 と FP64 スループット。
- 最大 96 GB の HBM3 メモリを搭載し、最大 3000 GB/s の速度を提供。
- 60 MB L2 キャッシュ。
- NVLink 4 と PCIe 5。
- NVIDIA NVLink-C2C:
- Grace CPU と Hopper GPU の間のハードウェア コヒーレントなインターコネクト。
- 総帯域幅最大 900 GB/s (双方向)、450 GB/s (片方向)。
- 拡張 GPU メモリ機能により、Hopper GPU はすべての CPU メモリを GPU メモリとしてアドレス可能。各 Hopper GPU はスーパーチップ内で最大 608 GB のメモリにアクセス可。
- NVIDIA NVLink Switch System:
- NVLink 4 を使用して最大 256 基 の NVIDIA Grace Hopper Superchip を接続。
- NVLink で接続された各 Hopper GPU は、ネットワーク内の全てのスーパーチップの HBM3 および LPDDR5X メモリ全てをアドレス指定でき、最大 150 TB のメモリを実現。
性能、移植性、生産性を追求したプログラミング モデル
PCIe 接続のアクセラレータを搭載した従来のヘテロジニアスなプラットフォームでは、ユーザーはデバイスのメモリ割り当てやホストとのデータ転送を手動で管理するような複雑なプログラミング モデルに従わなければなりませんでした。
NVIDIA Grace Hopper Superchip プラットフォームは、ヘテロジニアスでプログラミングが容易であり、NVIDIA は、選択したプログラミング言語に依存せず、すべての開発者とアプリケーションにアクセス可能にすることを約束します。
Grace Hopper Superchip とプラットフォームの両方が、目の前のタスクに適した言語を選択できるように構築されており、NVIDIA CUDA LLVM コンパイラ API により、NVIDIA コンパイラやツールと同じレベルのコード生成品質と最適化で好みのプログラミング言語を CUDA プラットフォームに導入することが可能です。
NVIDIA が CUDA プラットフォーム向けに提供する言語 (図 3) には、ISO C++、ISO Fortran などの高速化された標準言語や Python が含まれています。また、このプラットフォームは、OpenACC、OpenMP、CUDA C++、CUDA Fortran などのディレクティブ ベースのプログラミング モデルもサポートしています。NVIDIA HPC SDK は、プロファイリングやデバッグのための豊富な高速化されたライブラリやツールとともに、これらすべてのアプローチをサポートしています。

NVIDIA は、ISO C++ および ISO Fortran プログラミング言語コミュニティのメンバーであり、ISO C++ および ISO Fortran 標準に準拠したアプリケーションを、言語拡張なしに NVIDIA CPU および NVIDIA GPU の両方で実行できるようにしました。GPU 上での ISO に準拠したアプリケーションの実行に関する詳細は、「標準並列 C++ によるマルチ GPU プログラミング、パート 1」および「Using Fortran Standard Parallel Programming For GPU Acceleration」をご参照ください。
この技術は、NVIDIA NVLink-C2C および NVIDIA Unified Virtual Memory が提供するハードウェア アクセラレーションによるメモリ一貫性に大きく依存しています。図 4 に示すように、ATS のない従来の PCIe 接続の x86+Hopper システムでは、CPU と GPU は独立したプロセスごとのページ テーブルを持ち、システム割り当てメモリは GPU から直接アクセスできません。プログラムがシステム アロケーターでメモリを割り当てても、そのページ エントリが GPU のページ テーブルで利用できない場合、GPU のスレッドからメモリへのアクセスに失敗します。
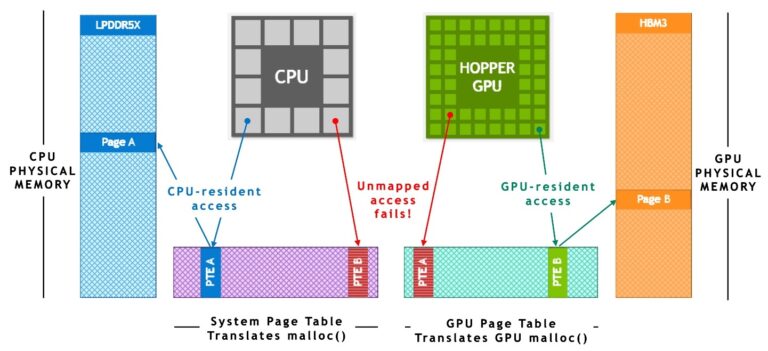
NVIDIA Grace Hopper Superchip ベースのシステムでは、ATS によって、CPU と GPU が単一のプロセスごとのページ テーブルを共有し、全ての CPU および GPU スレッドが、物理 CPU または GPU メモリに存在可能な全てのシステム割り当てメモリにアクセスすることが可能になります。CPU ヒープ、CPU スレッド スタック、グローバル変数、メモリマップト ファイル、プロセス間メモリは、すべての CPU および GPU スレッドからアクセス可能です。
NVIDIA NVLink-C2C ハードウェア コヒーレンシは、Grace CPU がキャッシュライン粒度で GPU メモリをキャッシュし、GPU と CPU がページ移動せずとも互いのメモリにアクセスすることが可能です。
NVLink-C2C は、システムに割り当てられたメモリ上で CPU と GPU がサポートする全てのアトミック操作も高速化します。スコープ付きのアトミック操作が完全にサポートされており、システム内のすべてのスレッドにわたってきめ細かく拡張性の高い同期を可能にします。
ランタイムは、システムが割り当てたページに対して、CPU と GPU のどちらのスレッドが最初にアクセスしたかによって、LPDDR5X または HBM3 のいずれかの物理メモリを対応づけます。OS の観点では、Grace CPU と Hopper GPU は 2 つの独立した NUMA ノードに過ぎません。メモリは移行可能なので、ランタイムはページに対応する物理メモリ (LPDDR5X あるいは HBM3) を変更して、アプリケーションの性能を向上させたり、メモリのひっ迫に対処することができます。
x86 や Arm などの PCIe ベースのプラットフォームでは、NVIDIA Grace Hopper モデルと同じ Unified Memory プログラミング モデルを使用することができます。これは最終的には、CPU と GPU 間のメモリ一貫性をエミュレートするソフトウェアを使う、Linux カーネルの機能とNVIDIA ドライバーの機能を組み合わせた HMM (Heterogeneous Memory Management) 機能によって可能になります。
NVIDIA Grace Hopper では、これらのアプリケーションは、ソフトウェアを変更することなく、NVLink-C2C が提供する高帯域幅、低遅延、高いアトミック スループット、およびメモリ一貫性のためのハードウェアによる高速化の恩恵を透過的に受けることができるのです。
スーパーチップのアーキテクチャの特徴
NVIDIA Grace Hopper アーキテクチャの主な革新的な技術は以下のとおりです。
- NVIDIA Grace CPU
- NVIDIA Hopper GPU
- NVLink-C2C
- NVLink Switch System
- 拡張 GPU メモリ
NVIDIA Grace CPU
GPU の並列演算性能は世代毎に 3 倍の向上を続けており、ワークロードの並列化できない部分が計算時間の大半を占めることを防ぐためには、高速で効率的な CPU が重要です。
NVIDIA Grace CPU は、NVIDIA 初のデータ センター向け CPU で、HPC と AI のスーパーチップを作るために一から開発されました。Grace は最大 72 個の Arm Neoverse V2 CPU コアを提供します。これは Armv9.0-A ISA を採用し、Scalable Vector Extensions 2 (SVE2) SIMD 命令セットをサポートしたコアあたり 4×128 ビット幅の SIMD ユニットを持ちます。
NVIDIA Grace は、従来の CPU よりも高いエネルギー効率を実現しながら、スレッドごとの性能も第一級です。72 個の CPU コアは、SPECrate 2017_int_base で最大で 370 (推定) のスコアを提供し、HPC と AI 双方の要求を満たす高い性能を確保します。
機械学習やデータ サイエンスにおける最新の GPU ワークロードは、膨大な量のメモリにアクセスする必要があります。通常、こうしたワークロードは、複数の GPU を使用して、HBM メモリにデータセットを格納する必要があります。
NVIDIA Grace CPU は、最大 512 GB の LPDDR5X メモリを提供し、メモリ容量、エネルギー効率、および性能の最適なバランスを実現します。最大 546 GB/s の LPDDR5X メモリ帯域幅を提供し、NVLink-C2C により 900 GB/s の総帯域幅で GPU にアクセスすることができます。
NVIDIA Grace Hopper Superchip 1 個で、Hopper GPU に合計 608 GB の高速でアクセス可能なメモリを提供しており、これは前世代の 8 GPU システムである DGX A100 の GPU メモリ総量 (640 GB) にほぼ匹敵するものです。
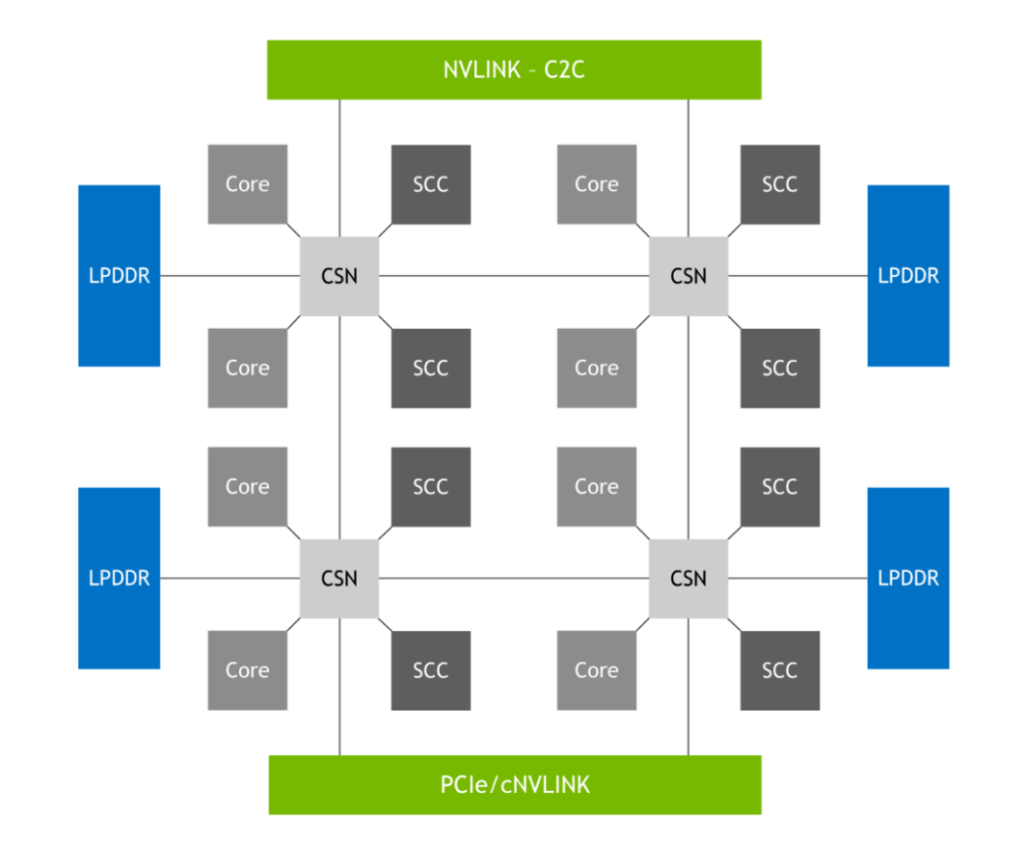
これを可能にするのが、図 7 に示す NVIDIA SCF で、メッシュ ファブリックと分散キャッシュは、最大 3.2 TB/s の総バイセクション帯域幅を提供し、CPU コア、メモリ、システム I/O および NVLink-C2C の性能をフルに発揮させることができます。CPU コアと SCF キャッシュ パーティション (SCC) はメッシュ全体に分散して配置され、キャッシュ スイッチ ノード (CSN) はファブリックを介してデータをルーティングし、CPU コア、キャッシュ メモリ、およびシステム間の残りの部分のインターフェイスとして機能します。
NVIDIA Hopper GPU
NVIDIA Hopper GPU は、第 9 世代の NVIDIA データ センター GPU です。前世代の NVIDIA Ampere GPU と比較して、大規模な AI および HPC アプリケーションに対して桁違いの改善をもたらすように設計されています。Hopper GPU は、以下の複数の革新的な技術も特徴としています。
- 新しい第 4 世代の Tensor コアは、AI や HPC のさらに幅広いタスクにおいて、これまで以上に高速な行列計算を実行します。
- 新しい Transformer Engineにより、H100 は前世代の NVIDIA A100 GPU と比較して、大規模言語モデルにおいて最大 9 倍の AI トレーニング速度と最大 30 倍の AI 推論速度向上を実現しました。
- 空間と時間のデータ局所性および非同期実行の機能の向上により、アプリケーションは常にすべてのユニットをビジー状態に保ち、電力効率を最大化することができます。
- セキュアな マルチ インスタンス GPU (MIG) は、GPU を適切なサイズのインスタンスに分割し、小規模なワークロードのサービス品質 (QoS) を最大化することができます。
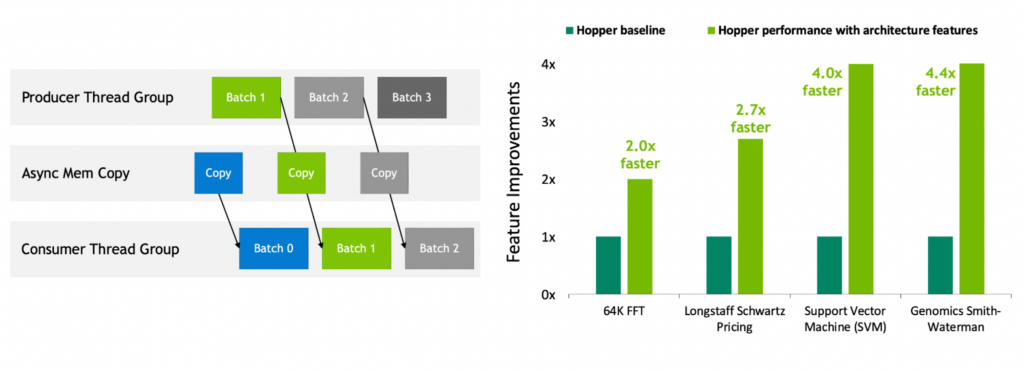
NVIDIA Hopper は、初の真に非同期な GPU です。その Tensor Memory Accelerator (TMA) と非同期トランザクション バリアは、スレッドのオーバーラップとパイプラインによる独立したデータ移動とデータ処理を可能にし、アプリケーションがすべてのユニットをフル活用できるようにします。
スレッド ブロック クラスター、分散共有メモリ、スレッド ブロック リコンフィギュレーションなどの新しい空間的/時間的局所性機能により、アプリケーションはより大量の共有メモリやツールに高速にアクセスできるようになります。これにより、アプリケーションはオンチップでのデータの再利用が容易になり、アプリケーションの性能をさらに向上させることができます。
詳細については、NVIDIA H100 Tensor Core Architecture Overview (NVIDIA H100 Tensor コアのアーキテクチャ概要) および NVIDIA Hopper アーキテクチャの徹底解説を参照してください。
NVLink-C2C: スーパーチップ向け高帯域チップ間インターコネクト
NVIDIA Grace Hopper は、NVIDIA Grace CPU と NVIDIA Hopper GPU を、NVIDIA NVLink-C2C (900 GB/s のチップ間コヒーレント インターコネクト) を通じて単一のスーパーチップに融合し、統一されたプログラミング モデルで Grace Hopper Superchip をプログラミングできるようにします。
NVLink Chip-2-Chip (C2C) インターコネクトは、Grace CPU と Hopper GPU 間を高帯域幅で直接接続し、AI や HPC アプリケーションの一時的な高速化のために設計された Grace Hopper Superchip を作成します。
900 GB/s の双方向帯域幅を持つ NVLink-C2C は、x16 PCIe Gen リンクの 7 倍の帯域幅を低遅延で提供します。また、NVLink-C2C は、ビット転送当たり 1.3 ピコジュールしか使用しないため、PCIe Gen 5 に比べて 5 倍以上エネルギー効率が向上しています。
さらに、NVLink-C2C は、システム全体のアトミック操作をハードウェアでネイティブにサポートするコヒーレント メモリ インターコネクトです。これにより、CPU と GPU のスレッドが他のデバイスのメモリにアクセスするような、非ローカル メモリへのメモリ アクセスの性能が向上します。また、ハードウェア コヒーレンシは、同期プリミティブの性能も向上させ、GPU や CPU が互いに待つ時間を減らし、システム全体の使用率を向上させます。
最後に、ハードウェア コヒーレンシは、一般的なプログラミング言語やフレームワークを使用したヘテロジニアスなコンピューティング アプリケーションの開発も簡素化します。詳細については、NVIDIA Grace Hopper Programming Model のセクションをご覧ください。
NVLink Switch System
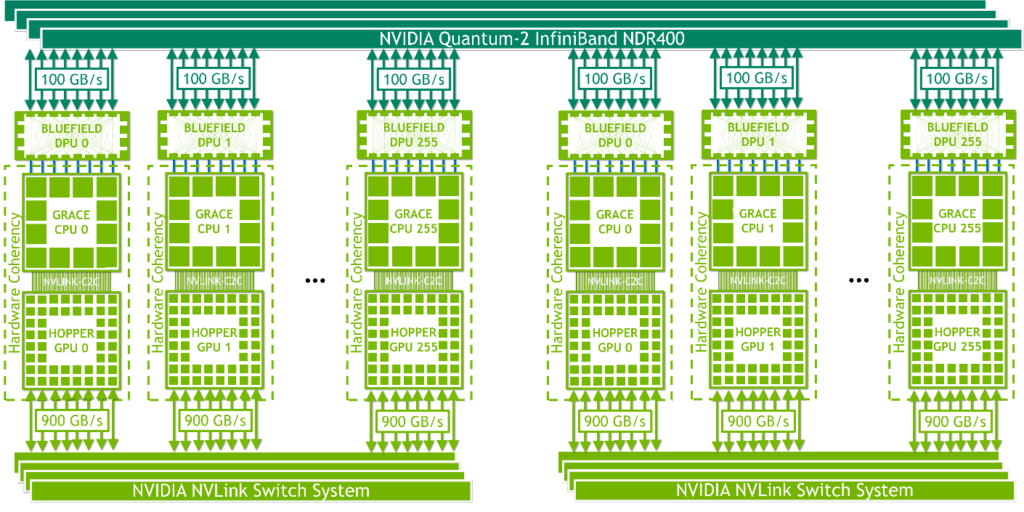
NVIDIA NVLink Switch System では、第 4 世代の NVIDIA NVLink 技術と新しい第 3 世代の NVIDIA NVSwitch が組み合わされています。NVSwitchの 単一レベルは、最大 8 個の Grace Hopper Superchip を接続し、ファットツリー トポロジの 2 番目のレベルは、NVLink で最大 256 個の Grace Hopper Superchip のネットワーキングを可能にします。Grace Hopper Superchip のペアは、最大 900 GB/s でデータを交換します。
最大 256 個の Grace Hopper Superchip により、ネットワークは、最大 115.2 TB/s の All-to-All 帯域幅を提供します。これは、NVIDIA InfiniBand NDR400 の All-to-All 帯域幅の 9 倍に相当します。

第 4 世代の NVIDIA NVLink 技術により、GPU スレッドは、通常のメモリ操作、アトミック操作、およびバルク転送を使用して、NVLink ネットワーク内のすべてのスーパーチップが提供する最大 150 TB のメモリをアドレス指定することができます。MPI、NCCL、NVSHMEM などの通信ライブラリは、利用可能な場合には、NVLink Switch System を透過的に活用します。
拡張 GPU メモリ
NVIDIA Grace Hopper Superchip は、単一のスーパーチップの HBM3 および LPDDR5X メモリの容量よりも大きく、非常に大きなメモリ フットプリントを持つアプリケーションを加速するために設計されています。詳細については、NVIDIA Grace Hopper Accelerated Applications のセクションをご覧ください。
高帯域幅の NVLink-C2C を介した EGM (Extended GPU Memory) 機能により、GPU はすべてのシステム メモリに効率的にアクセスすることができます。EGM は、マルチノードの NVSwitch 接続システムにおいて、最大 150 TB のシステム メモリを提供します。EGM を使用すると、マルチノード システム内のどの GPU スレッドからでもアクセスできるように物理メモリを割り当てることができます。すべての GPU は、GPU 間 NVLink または NVLink-C2C による最短経路で EGM にアクセスすることができます。
Grace Hopper Superchip 構成内のメモリ アクセスは、合計 900 GB/s のローカル高帯域幅 NVLink-C2C を経由します。リモート メモリへのアクセスは、GPU NVLink を介して行われ、アクセスするメモリによっては NVLink-C2C も使用します (図 11)。EGM により、GPU スレッドは、LPDDR5X と HBM3 の両方の NVSwitch ファブリック上で利用できるすべてのメモリ リソースに 450 GB/s でアクセスできるように なりました。

NVIDIA HGX Grace Hopper
NVIDIA HGX Grace Hopper は、ノードあたり 1 つの Grace Hopper Superchip を搭載し、BlueField-3 NIC または OEM 定義の I/O と、オプションでは NVLink Switch System 備えます。空冷または液冷が可能で、TDP は最大 1,000W です。

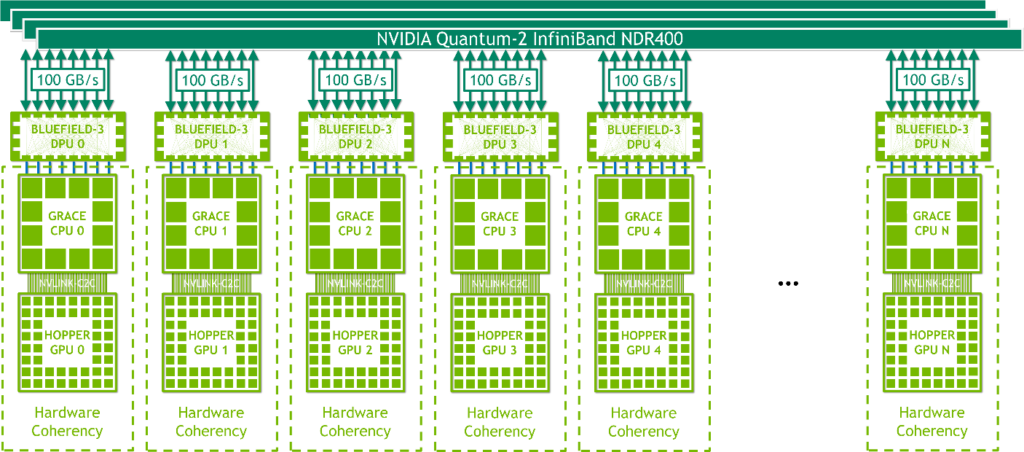
InfiniBand 搭載 NVIDIA HGX Grace Hopper
InfiniBand 搭載 NVIDIA HGX Grace Hopper (図 13) は、利用可能な最速のインターコネクトの 1 つである InfiniBand のネットワーク通信オーバーヘッドがボトルネックにならない、従来の機械学習 (ML) や HPC ワークロードのスケールアウトに理想的な製品です。
各ノードには、1 つの Grace Hopper Superchip と、NVMe SSD や BlueField-3 DPU、NVIDIA ConnectX-7 NIC、OEM 定義の I/O などの 1 つまたは複数の PCIe デバイスが搭載されています。PCIe Gen 5 x16 レーンを持つ NDR400 InfiniBand NIC は、スーパーチップ全体で最大 100 GB/s の総帯域幅を提供します。NVIDIA BlueField-3 DPU と組み合わせたこのプラットフォームは、管理と導入が容易で、従来の HPC および AI クラスター ネットワーキング アーキテクチャを使用します。
NVIDIA HGX Grace Hopper と NVLink Switch
NVLink Switch を搭載した NVIDIA HGX Grace Hopper は、巨大な機械学習や HPC ワークロードの強力な拡張に理想的です。これにより、NVLink 接続されたドメイン内のすべての GPU スレッドが、256 基の GPU の NVLink 接続システムにおいて、スーパーチップあたり最大 900GB/s の総帯域幅で最大 150 TB のメモリをアドレスすることが可能になります。シンプルなプログラミング モデルで、ポインターのロード、ストア、アトミック操作を使用します。450 GB/s の All-reduce 帯域幅と最大 115.2 TB/s のバイセクション帯域幅により、このプラットフォームは世界最大かつ最も困難な AI トレーニングおよび HPC ワークロードの強力なスケーリングに最適です。
例えば NVIDIA ConnectX-7 NIC または NVIDIA BlueField-3 DPU が NVIDIA Quantum 2 NDR スイッチや OEM 定義の I/O ソリューションと組み合わされるなど、NVLink で接続されたドメインは、NVIDIA InfiniBand 技術でネットワーク化されます。
性能のブレイクスルーを実現する
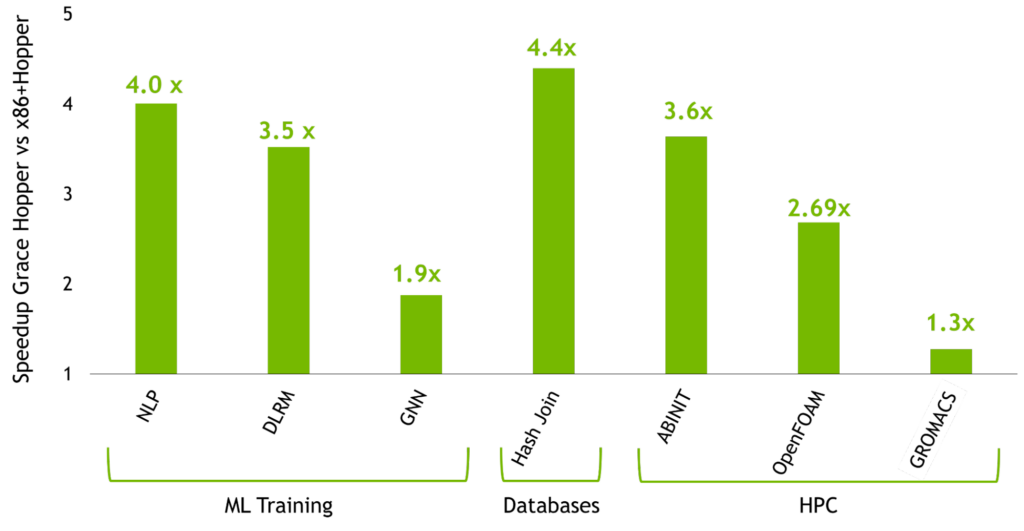
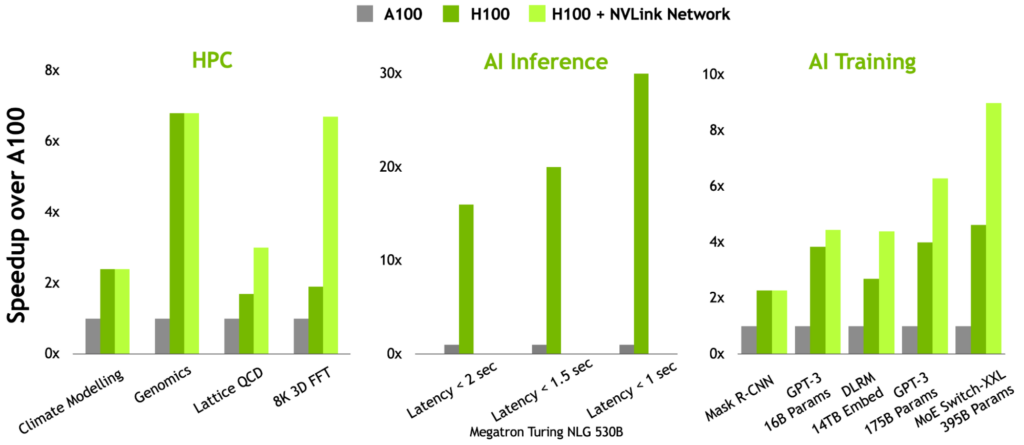
NVIDIA Grace Hopper Superchip アーキテクチャのホワイトペーパーでは、この記事の内容をさらに深め、Grace Hopper が、NVIDIA Hopper H100 PCIe GPU を搭載した現在最も強力な PCIe ベースのアクセラレーテッド プラットフォームに対し、図 1 に示すような性能のブレイクスルーをどのように実現するのかを詳細に解説しています。
NVIDIA Grace Hopper Superchip に最適なアプリケーションをご存知でしたら、原典のコメント欄で是非教えてください。
謝辞
Jack Choquette、Ronny Krashinsky、John Hubbard、Mark Hummel、Greg Palmer、Ryan Wells、Alex Ishii、Jonah Alben、そしてこの記事の執筆に協力してくれた多くの NVIDIA アーキテクトとエンジニアたちに感謝いたします。
翻訳に関する免責事項
この記事は、「NVIDIA Grace Hopper Superchip Architecture In-Depth」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。