2022 年 3 月の NVIDIA GTC 基調講演において、NVIDIA の創業者/CEO であるジェンスン フアンが、新しい NVIDIA Hopper GPU アーキテクチャに基づく NVIDIA H100 Tensor コア GPU を紹介しました。この記事では、新しい H100 GPU の内部と、NVIDIA Hopper アーキテクチャ GPU の重要な新機能について説明します。
NVIDIA H100 Tensor コア GPUの紹介
NVIDIA H100 Tensor コア GPU は、大規模な AI や HPC において前世代の NVIDIA A100 Tensor コア GPU と比較して桁違いの性能の飛躍を実現するために設計された NVIDIA の第 9 世代データ センター GPU です。H100 は、AI と HPC ワークロードでの強スケーリング性能を改善すべく、A100 の主要な設計上の焦点を引き継ぎ、アーキテクチャの効率性を大幅に向上させました。

現在主流の AI や HPC モデルにおいて、InfiniBand インターコネクトを搭載した H100 は、A100 の最大 30 倍の性能を実現します。新しい NVLink Switch システム インターコネクトは、複数の GPU ノードにわたるモデル並列処理が必要になる、極めて大規模かつ困難なコンピューティング ワークロードをターゲットにしています。これらのワークロードは、さらに世代を超えた性能の飛躍を遂げ、場合によっては、InfiniBand を使用した H100 に比べて性能がさらに 3 倍になることもあります。
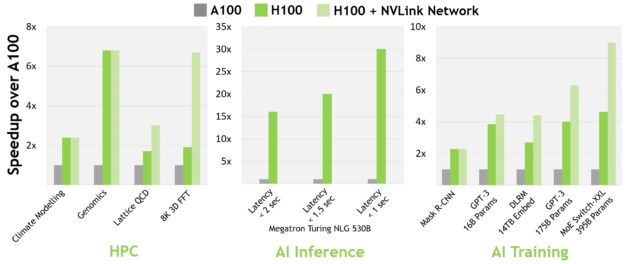
すべての性能数値は、現時点での予想であり、出荷製品で変更される可能性があります。A100 クラスター。 HDR IB ネットワーク。H100 クラスター。NDR IB ネットワーク、NVLink スイッチ システム (指定箇所)。# GPU: 気候モデリング 1K、LQCD 1K、ゲノミクス 8、3D-FFT 256、MT-NLG 32 (バッチ サイズ: MRCNN 8 (バッチ 32)、GPT-3 16B 512 (バッチ 256)、DLRM 128 (バッチ 64K)、GPT-3 16K (バッチ 512)、MoE 8K (バッチ 512、GPU ごとにエキスパート 1 名) です。
2022 年春の GTC ではまた、NVIDIA Grace Hopper スーパーチップが発表されました。テラバイト規模のアクセラレーテッド コンピューティング向けに専用設計され、大規模モデル AI や HPC において 10 倍以上の性能を提供する、この新しい CPU + GPU アーキテクチャには NVIDIA Hopper H100 Tensor コア GPU が搭載されます。
NVIDIA Grace Hopper スーパーチップは、Arm アーキテクチャの柔軟性を活用し、アクセラレーテッド コンピューティングのために一から設計された CPU とサーバー アーキテクチャを構築しています。H100 と NVIDIA Grace CPU は、PCIe Gen5 の 7 倍にあたる 900 GB/秒の総帯域幅を持つ超高速 NVIDIA チップ間インターコネクトで接続されます。この革新的な設計により、現在最速のサーバーと比較して最大 30 倍の総帯域幅を実現し、テラバイト単位のデータを使用するアプリケーションでは最大 10 倍の性能を発揮することができます。
NVIDIA H100 GPU 主要機能概要
- 新しい streaming multiprocessor (SM) は、多くの性能と効率の向上を実現しました。主な新機能は以下の通りです。
- 新しい 第 4 世代 Tensor コアは、SM 自体の高速化、SM 数の増加、クロック周波数の向上等により、A100 との比較で最大 6 倍高速化されています。SM 単位で見ると、Tensor コアは、前世代である A100 SM の FP16 性能との比較において、同等のデータ型で 2 倍、新しい FP8 データ型なら 4 倍の MMA (行列積和) 演算レートを実現しています。Sparsity 機能は、ディープラーニング ネットワークにおける細粒度構造化スパース性を利用し、標準的な Tensor コア 演算の性能を 2 倍に向上させます。
- 新しい DPX 命令は、動的計画法のアルゴリズムを A100 GPU の最大 7 倍まで加速します。その例として、ゲノム処理のための Smith-Waterman アルゴリズムと、動的な倉庫環境におけるロボット群の最適経路を見つけるために使用されるワーシャル–フロイド法が挙げられます。
- IEEE FP64、FP32 の 演算性能が A100 比で 3 倍に向上。これには同一クロック周波数での比較で 2 倍になった SM 単体性能に加え、SM 数の増加、クロック周波数の向上が貢献しています。
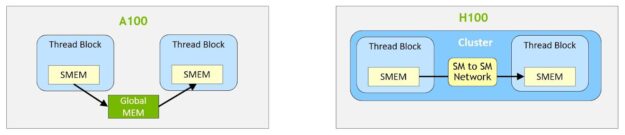
- 新しいスレッド ブロック クラスター機能では、単一 SM 上のスレッド ブロックよりも大きな粒度で局所性をプログラム的に制御することができます。これは、 スレッド、スレッド ブロック、スレッド ブロック クラスター、そしてグリッドという形でプログラミング階層にもう 1 つのレベルを追加することで、 CUDA プログラミング モデルを拡張します。クラスターでは、複数の SM で並列に動作する複数のスレッド ブロックを同期させ、共同でデータの取得や交換を行うことができます。
- 分散シェアード メモリは、複数 SM のシェアード メモリ ブロックにまたがるロード、ストア、アトミック操作について、SM 間直接通信を可能にします。
- 非同期実行の新機能として、グローバル メモリとシェアード メモリ間で大きなデータ ブロックを効率的に転送できる新しい Tensor Memory Accelerator (TMA) ユニットが搭載されています。TMA は、クラスター内のスレッド ブロック間の非同期コピーもサポートしています。また、アトミックなデータ移動と同期を行うための新しい非同期トランザクション バリアも用意されています。
- 新しい Transformer Engine は、Transformer モデルのトレーニングと推論を高速化するために特別に設計されたソフトウェアとカスタム NVIDIA Hopper Tensor コア テクノロジを組み合わせています。Transformer Engine は、各レイヤーの計算をインテリジェントに管理して FP8 と FP16 を動的に選択し、リキャストとスケーリングを自動的に処理することで、前世代の A100 と比較して、大規模言語モデルの AI トレーニングを最大 9 倍、AI 推論を最大 30 倍高速化します。
- HBM3 メモリ サブシステムにより、前世代に比べ約 2 倍の帯域幅を実現。H100 SXM5 GPU は、クラス最高の 3TB/秒のメモリ帯域幅を実現する HBM3 メモリを搭載した世界初の GPU です。
- 50MB L2 キャッシュ アーキテクチャは、モデルやデータセットの大部分をキャッシュして繰り返しアクセスできるようにし、HBM3 へのトリップを軽減します。
- 第 2 世代マルチ インスタンス GPU (MIG) は、A100 と比較して、 GPU インスタンスあたりの計算能力が約 3 倍、メモリ帯域が約 2 倍に向上しています。MIG レベルの TEE によるコンフィデンシャル コンピューティング機能が初めて提供されました。最大 7 つの GPU インスタンスをサポートし、それぞれに専用の NVDEC および NVJPG ユニットを搭載。各インスタンスには、NVIDIA 開発者ツールで動作する独自のパフォーマンス モニターのセットが含まれるようになりました。
- 新しいコンフィデンシャル コンピューティングのサポートは、ユーザー データを保護し、ハードウェアおよびソフトウェア攻撃を防御し、仮想化環境および MIG 環境において仮想マシン (VM) を互いに分離して保護することが可能です。H100 は世界初のネイティブ コンフィデンシャル コンピューティング GPU を実装し、CPU の信頼された実行環境 (TEE) をPCIe フル ライン レートで GPU 側へ拡張します。
- 第 4 世代の NVIDIA NVLink は、マルチ GPU IO の総帯域幅 900 GB/秒 を実現。これは前世代の NVLink の 1.5 倍、PCIe Gen 5 の 7 倍に達します。また、all-reduce 操作では前世代の 3 倍の帯域幅を提供します。
- 第 3 世代 NVSwitch テクノロジは、ノードの内側と外側の両方にスイッチを搭載し、サーバー、クラスター、データ センター環境において複数の GPU を接続します。ノード内の各 NVSwitch は、第 4 世代 NVLink リンクを 64 ポート提供し、スイッチの総スループットは、前世代の 7.2 Tbits/sec から 13.6 Tbits/sec に増加します。新しい第 3 世代の NVSwitch 技術は、マルチキャストと NVIDIA SHARP テクノロジによる集合演算のハードウェア アクセラレーションも提供します。
- 新しい NVLink Switch システム インターコネクト技術と第 3 世代の NVSwitch 技術に基づく新しい第 2 レベルの NVLink Switch は、アドレス空間の分離と保護を導入し、最大 32 ノードまたは 256 GPU を、2 対 1 のテーパー ファット ツリー トポロジで NVLink を介して接続できるようにします。これらの接続されたノードは、57.6 TB/秒の all-to-all 帯域幅を提供し、FP8 スパース AI コンピューティングで 1 エクサフロップという驚異的な性能を実現します。
- PCIe Gen5 は、Gen4 の 64 GB/秒 (各方向 32 GB/秒) に対して、128 GB/秒 (各方向 64 GB/秒) の総帯域幅を提供します。PCIe Gen5 により、H100 は最高性能の x86 CPU や SmartNIC、DPU との接続が可能になります。
その他にも、強力なスケーリング、レイテンシとオーバーヘッドの削減、一般的な GPU プログラミングの簡素化など、多くの新機能が含まれています。
NVIDIA H100 GPU アーキテクチャの徹底解説
新しい NVIDIA Hopper GPU アーキテクチャに基づく NVIDIA H100 GPU は、複数の革新的な技術を搭載しています。
- 新しい第 4 世代の Tensor コアは、AI や HPC のさらに幅広いタスクにおいて、これまで以上に高速な行列計算を実行します。
- 新開発の Transformer Engine により、H100 は前世代の A100 と比較して、大規模言語モデルの AI 学習を最大 9 倍、AI 推論を最大 30 倍高速化することが可能です。
- 新しい NVLink ネットワーク インターコネクトは、複数のコンピュート ノードにわたり最大 256 基の GPU 間接続を可能にします。
- セキュアな MIG は、 GPU を隔離された適切なサイズのインスタンスに分割し、小規模なワークロードのサービス品質 (QoS) を最大化することができます。
その他にも多くの新アーキテクチャを採用し、多くのアプリケーションで最大 3 倍もの性能向上を実現しています。
NVIDIA H100 は、初の真の非同期型 GPU です。H100 は、A100 のグローバル メモリからシェアード メモリへの非同期転送をすべてのアドレス空間にわたって拡張し、テンソル メモリ アクセス パターンをサポートするようになりました。これにより、アプリケーションは、データをチップに移動したり、チップから移動したりするエンドツーエンドの非同期パイプラインを構築し、データ移動と計算を完全にオーバーラップさせて遅延を隠蔽することができます。
新しい Tensor Memory Accelerator を使用して H100 のメモリ バンド幅をフルに管理するために必要な CUDA スレッドはごく少数で、他のほとんどの CUDA スレッドは新世代の Tensor コア用のデータの前処理や後処理などの汎用計算に集中することができるようになりました。
H100 では、 CUDA スレッド グループの階層を拡張し、スレッド ブロック クラスターという新しい階層を追加しました。クラスターは、同時スケジューリングが保証されたスレッド ブロックのグループで、複数の SM にまたがるスレッドの効率的な協力とデータ共有を可能にします。また、クラスターは Tensor Memory Accelerator や Tensor コアなどの非同期ユニットを協調させ効率的に駆動します。
増え続けるオンチップ アクセラレータと多様な汎用スレッド群のオーケストレーションには、同期が必要です。例えば、出力を消費するスレッドやアクセラレータは、出力を生成するスレッドやアクセラレータを待つ必要があります。
NVIDIA 非同期トランザクション バリアは、クラスタ内の汎用 CUDA スレッドとオンチップ アクセラレータが、別々の SM に存在する場合でも、効率的に同期することを可能にします。これら全ての新機能により、全てのユーザーとアプリケーションが H100 GPU の全てのユニットを常にフルに使用することができ、H100 はこれまでで最も強力で、最もプログラムしやすく、電力効率の良い NVIDIA GPU になっています。
H100 GPU を搭載するフル GH100 は、NVIDIA 向けにカスタマイズされた TSMC 4N プロセスで製造されており、814 mm2 のダイ サイズに、800 億トランジスタを集積し、より高い周波数での設計が可能です。
NVIDIA GH100 GPU は、複数の GPU プロセッシング クラスター (GPC) 、テクスチャ プロセッシング クラスター (TPC) 、ストリーミング マルチプロセッサ (SM) 、L2 キャッシュ、HBM3 メモリ コントローラーで構成されています。
GH100 GPU のフル実装には、以下のユニットが含まれます。
- 8 GPC、72 TPC (9 TPC/GPC) 、2 SM/TPC、GPU 全体で 144 SM
- FP32 CUDA コアを SM あたり 128、GPU 全体で 18432 個
- 第 4 世代 Tensor コアを SM あたり 4 個、GPU 全体で 576 個
- HBM3 または HBM2e スタック × 6、512 ビット メモリ コントローラー × 12
- 60 MB L2 キャッシュ
- 第 4 世代 NVLink と PCIe Gen 5
SXM5 ボード フォーム ファクターの NVIDIA H100 GPU には、以下のユニットが含まれています。
- 8 GPC、66 TPC、2 SMs/TPC、GPU 全体で 132 SM
- FP32 CUDA コアを SM あたり 128、GPU 全体で 16896 個
- 第 4 世代 Tensor コアをSMあたり 4 個、GPU 全体で 528 個
- 80 GB HBM3、HBM3 スタック x 5、512 ビット メモリ コントローラー x 10
- 50MB L2 キャッシュ
- 第 4 世代 NVLink とPCIe Gen 5
PCIe Gen 5 ボード フォーム ファクターの NVIDIA H100 GPU は、以下のユニットを含みます。
- 7 または 8 の GPC、57 TPC、2 SMs/TPC、GPU 全体で 114 SM
- FP32 CUDA コアを SM あたり 128、GPU 全体で 14592 個
- 第 4 世代 Tensor コアを SM あたり 4 個、GPU 全体で 456 個
- 80 GB HBM2e、HBM2e スタック x 5、512 ビット メモリ コントローラー x 10
- 50MB L2 キャッシュ
- 第 4 世代 NVLink と PCIe Gen 5
TSMC 4N プロセスを採用した H100 は、TSMC 7nm N7 プロセスを採用した前世代の GA100 GPU と比較して、 GPU コア周波数の向上、ワット当たりの性能向上、およびより多くの GPC、TPC、SM の搭載を可能にしました。
図 3 は、GH100 GPU のフルモデルで、144 個の SM を搭載しています。H100 SXM5 GPU は 132 個、PCIe 版は 114 個の SM を搭載しています。H100 GPU は、主に AI、HPC、データ分析などのデータ センターやエッジ コンピュートのワークロードを実行するために作られており、グラフィックス処理向きではありません。SXM5 と PCIe 版 H100 GPU の両方で、グラフィックス対応 (つまり、バーテックス、ジオメトリ、ピクセルシェーダを実行可能) の TPC は 2 つだけです
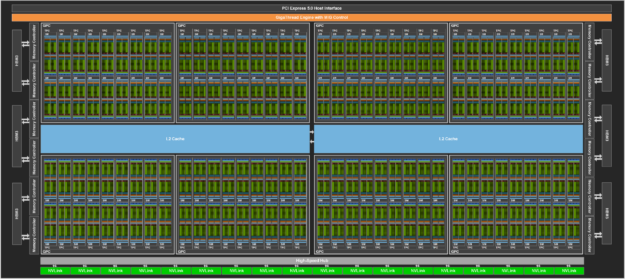
H100 SM アーキテクチャ
NVIDIA A100 Tensor コア GPU の SM アーキテクチャをベースにした H100 SM は、FP8 の導入により SM あたりの ピーク浮動小数点演算能力が A100 の 4 倍になり、同一クロックの場合で、以前の A100 の SM の演算能力、つまり Tensor コア、FP32、FP64 コアのすべての性能が 2 倍になりました。
新しい Transformer Engine は、NVIDIA Hopper FP8 Tensor コアとの組み合わせにより、前世代の A100 と比較して、大規模言語モデルの AI トレーニングを最大 9 倍、AI 推論を 30 倍高速化することを実現しています。新しい NVIDIA Hopper DPX 命令により、ゲノムおよびタンパク質配列の Smith-Waterman アルゴリズム処理を最大 7 倍高速化することができます。
新しい NVIDIA Hopper 第 4 世代 Tensor コア、Tensor Memory Accelerator、およびその他の多くの新しい SM と一般的な H100 アーキテクチャの改善により、多くのケースで最大 3 倍高速な HPC と AI パフォーマンスを提供します。
| NVIDIA H100 SXM51 | NVIDIA H100 PCIe1 | |
| Peak FP641 | 30 TFLOPS | 24 TFLOPS |
| Peak FP64 Tensor Core1 | 60 TFLOPS | 48 TFLOPS |
| Peak FP321 | 60 TFLOPS | 48 TFLOPS |
| Peak FP161 | 120 TFLOPS | 96 TFLOPS |
| Peak BF161 | 120 TFLOPS | 96 TFLOPS |
| Peak TF32 Tensor Core1 | 500 TFLOPS | 1000 TFLOPS2 | 400 TFLOPS | 800 TFLOPS2 |
| Peak FP16 Tensor Core1 | 1000 TFLOPS | 2000 TFLOPS2 | 800 TFLOPS | 1600 TFLOPS2 |
| Peak BF16 Tensor Core1 | 1000 TFLOPS | 2000 TFLOPS2 | 800 TFLOPS | 1600 TFLOPS2 |
| Peak FP8 Tensor Core1 | 2000 TFLOPS | 4000 TFLOPS2 | 1600 TFLOPS | 3200 TFLOPS2 |
| Peak INT8 Tensor Core1 | 2000 TOPS | 4000 TOPS2 | 1600 TOPS | 3200 TOPS2 |
- H100 の性能は現時点での予想であり、出荷製品で変更される可能性があります。
- スパース性機能を用いた実効 TFLOPS / TOPS
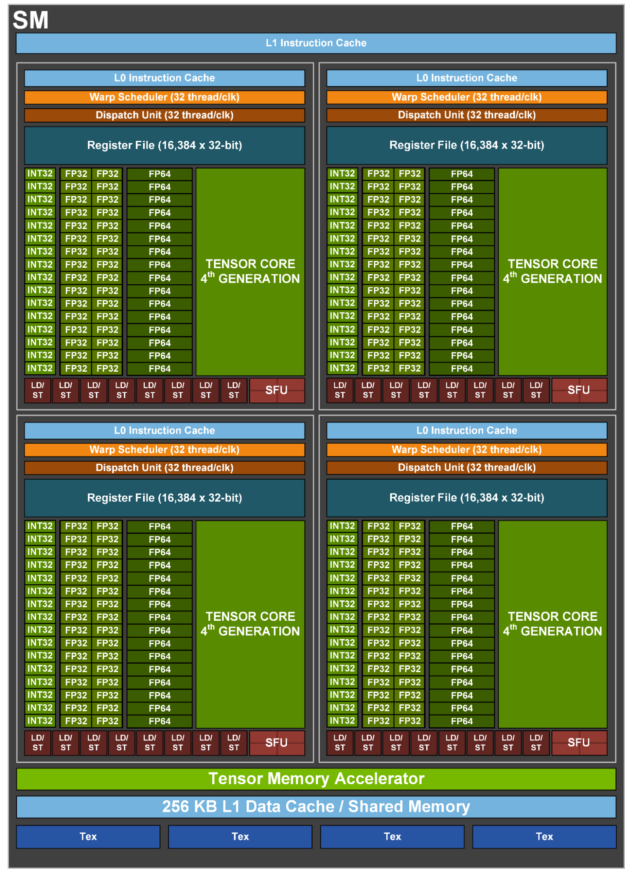
H100 SM の主な機能概要
- 第 4 世代 Tensor コア
- SM 自体の高速化、SM 数の増加、クロック周波数の向上等により、A100 との比較で最大 6 倍高速化されています。
- SM 単位で見ると、Tensor コアは、前世代である A100 SM の FP16 性能との比較において、同等のデータ型で 2 倍、新しい FP8 データ型なら 4 倍の MMA (行列積和) 演算レートを実現しています。
- Sparsity 機能は、ディープラーニング ネットワークにおける細粒度構造化スパース性を利用し、標準的な Tensor コア 演算の性能を 2 倍に向上させます
- 新しい DPX 命令は、動的計画法のアルゴリズムを A100 GPU の最大 7 倍に高速化します。その例として、ゲノム処理のための Smith-Waterman アルゴリズムと、動的な倉庫環境におけるロボット群の最適経路を見つけるために使用されるワーシャル–フロイド法が挙げられます。
- IEEE FP64、FP32 の 演算性能が A100 比で 3 倍に向上 これには同一クロック周波数での比較で 2 倍になった SM 単体性能に加え、SM 数の増加、クロック周波数の向上が貢献しています。
- シェアード メモリと L1 データ キャッシュを合わせて 256 KB とA100 の 1.33 倍になりました。
- 新しい非同期実行機能として、グローバル メモリとシェアード メモリ間で大きなデータ ブロックを効率的に転送できる新しい Tensor Memory Accelerator (TMA) ユニットがあります。TMA は、クラスター内のスレッド ブロック間の非同期コピーもサポートしています。また、アトミックなデータ移動と同期を行うための新しい非同期トランザクション バリアも用意されています。
- 新しいスレッド ブロック クラスター機能は、複数の SM にまたがるローカリティの制御を公開します。
- 分散型シェアード メモリにより、複数の SM シェアード メモリ ブロック間でロード、ストア、アトミックなどの SM 間直接通信が可能です。
H100 Tensor コア アーキテクチャ
Tensor コアは、AI や HPC アプリケーションに画期的なパフォーマンスを提供する、MMA (Matrix Multiply and Accumulate) 演算に特化した高性能コンピュート コアです。1 つの NVIDIA GPU の SM 間で並列に動作する Tensor コアは、標準的な浮動小数点 (FP) 、整数 (INT) 、および融合積和 (FMA) 演算に比べて、スループットと効率を大幅に向上させることが可能です。
Tensor コアは、NVIDIA V100 GPU で初めて導入され、NVIDIA GPU アーキテクチャの各新世代でさらに強化されています。
H100 の新しい第 4 世代 Tensor コア アーキテクチャは、A100 と比較して、SM あたりの密行列および疎行列の計算スループットがクロックごとに 2 倍になり、A100 よりも H100 の GPU ブースト クロックが高い事を考慮するとさらに高くなります。FP8、FP16、BF16、TF32、FP64、INT8 MMA データ タイプがサポートされています。また、新しい Tensor コアは、より効率的なデータ管理を行い、オペランド送出電力を最大 30% 削減します。
NVIDIA Hopper FP8 データ フォーマット
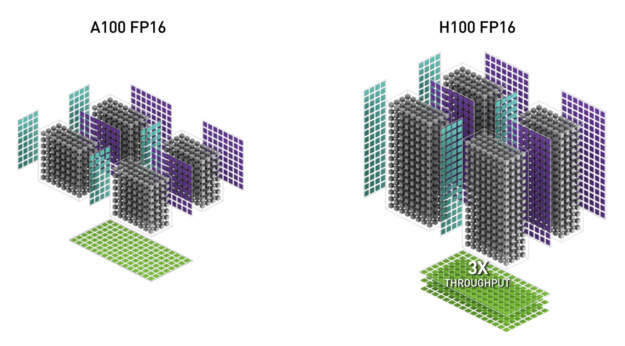
H100 GPU では、FP8 Tensor コアを追加し、AI の学習と推論の両方を高速化しました。図 6 に示すように、FP8 Tensor コアは FP32 と FP16 のアキュムレータをサポートし、新たに 2 種類の FP8 入力をサポートしています。
- E4M3 指数 4 ビット、仮数 3 ビット、符号 1 ビット
- E5M2、指数 5 ビット、仮数 2 ビット、符号 1 ビット
E4M3 はより少ないダイナミック レンジでより高い精度を必要とする計算をサポートし、E5M2 はより広いダイナミック レンジでより低い精度を提供します。FP8 は、FP16 や BF16 と比較して、データ ストレージの要件を半減し、スループットを 2 倍にすることができます。
後述する新しい Transformer Engine は、FP8 と FP16 の両方の精度を使って、メモリ使用量を減らし、性能を向上させながら、大規模言語などのモデルでも精度を維持できるようにしています。
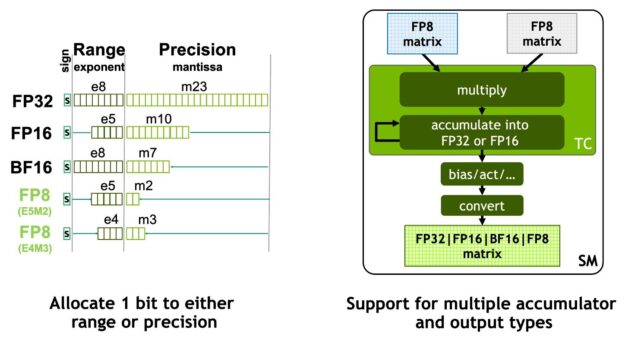
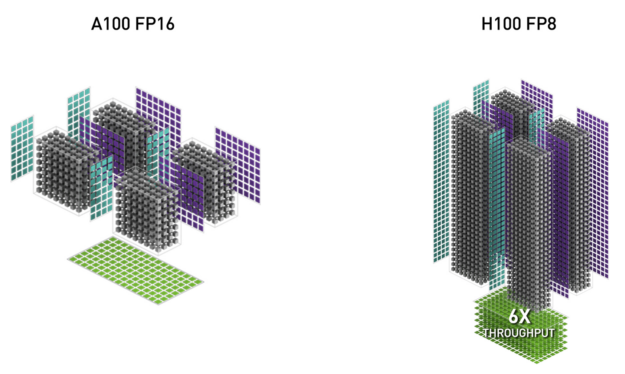
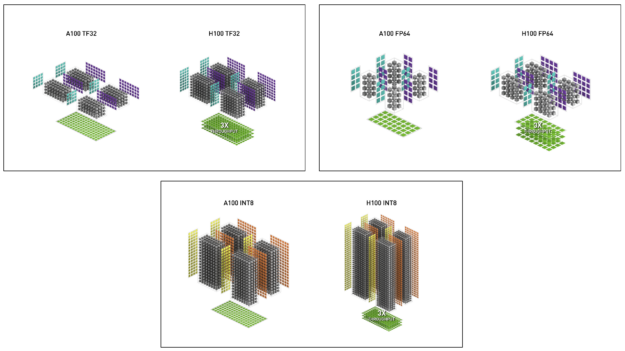
表 2 は、複数のデータ型について、A100 に対する H100 の演算速度向上を示したものです。
| (measurements in TFLOPS) | A100 | A100 Sparse | H100 SXM51 | H100 SXM51 Sparse | H100 SXM51 Speedup vs A100 |
| FP8 Tensor Core | 2000 | 4000 | 6.4x vs A100 FP16 | ||
| FP16 | 78 | 120 | 1.5x | ||
| FP16 Tensor Core | 312 | 624 | 1000 | 2000 | 3.2x |
| BF16 Tensor Core | 312 | 624 | 1000 | 2000 | 3.2x |
| FP32 | 19.5 | 60 | 3.1x | ||
| TF32 Tensor Core | 156 | 312 | 500 | 1000 | 3.2x |
| FP64 | 9.7 | 30 | 3.1x | ||
| FP64 Tensor Core | 19.5 | 60 | 3.1x | ||
| INT8 Tensor Core | 624 TOPS | 1248 TOPS | 2000 | 4000 | 3.2x |
1 – H100 の性能は現時点での予想であり、出荷製品で変更される可能性があります。
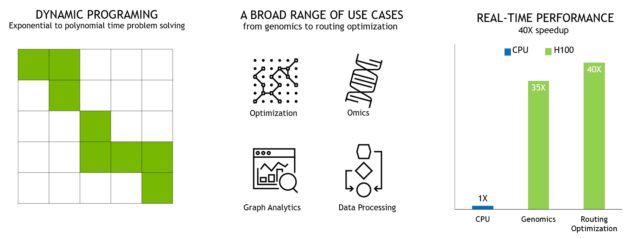
ダイナミック プログラミングを高速化する新しい DPX 命令
多くのブルート フォース最適化アルゴリズムは、より大きな問題を解く際に、部分問題の解が何度も再利用されるという性質を持っています。動的計画法 (DP) は、複雑な再帰的問題をより単純な部分問題に分解して解くアルゴリズム手法です。部分問題の解を保存しておけば、後で必要なときに再計算する必要がないため、指数関数的な問題群の計算量を線形にすることができます。
DP は、最適化、データ処理、ゲノミクスの幅広いアルゴリズムで一般的に使用されています。
- 急速に発展しているゲノム解読の分野では、Smith-Waterman アルゴリズムが最も重要な手法の 1 つとなっている。
- ロボット分野では、ワーシャル–フロイド法が、ダイナミックな倉庫環境でロボット群の最適経路をリアルタイムに探索するための重要なアルゴリズムである。
H100 では、DPX 命令を導入し、NVIDIA Ampere GPU と比較して DP アルゴリズムの性能を最大 7 倍に高速化しました。これらの新しい命令は、多くの DP アルゴリズムの内部ループのための高度な融合オペランドをサポートします。これにより、疾病診断、物流経路の最適化、さらにはグラフ解析において、解決までの時間を劇的に短縮することができます。
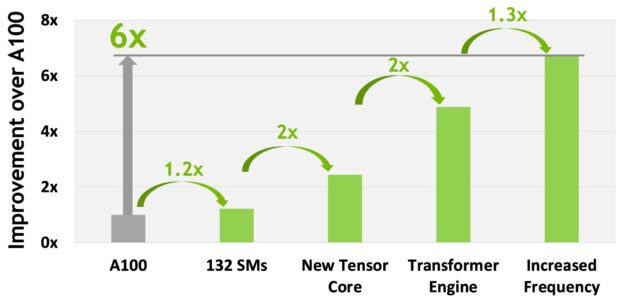
H100 のコンピュート パフォーマンス概要
H100 の新しいコンピュート テクノロジの進歩をすべて考慮すると、全体として H100 は A100 の約 6 倍のコンピュート性能の向上を実現しています。図 10 は、H100 の改善点をカスケード式にまとめたものです。
- 132 個の SM は、A100 の 108 個の SM と比較して 22% の SM 数の増加をもたらします。
- H100 SM は、新しい第 4 世代 Tensor コアにより、 2 倍高速化されています。
- 各 Tensor コアでは、新しい FP8 フォーマットと関連する Transformer Engine によって、さらに 2 倍の改善が実現されています。
- H100 ではクロック周波数が向上し、さらに約 1.3 倍の性能向上を実現しました。
これらの改良により、H100 は A100 の約 6 倍のピーク演算スループットを達成し、世界で最も演算負荷の高いワークロードにおいて大きな飛躍を遂げました。
H100 は、世界で最も計算負荷の高いワークロードに対して 6 倍のスループットを提供します。
H100 GPU 階層と非同期性の改善
並列プログラムの高性能化には、データ局所性と非同期実行の 2 つが重要な鍵を握っています。非同期実行は、メモリ転送や他の処理と重なる独立したタスクを見つけることです。目標は、 GPU のすべてのユニットを完全に使用し続けることです。
次のセクションでは、NVIDIA Hopper の GPU プログラミング階層に追加された重要な新階層について、単一の SM 上の単一スレッド ブロックより大きなスケールでの局所性を公開します。また、パフォーマンスを向上させ、同期のオーバーヘッドを削減する新しい非同期実行機能についても説明します。
スレッド ブロック クラスター
CUDA プログラミング モデルは、複数のスレッド ブロックを含むグリッドを使用してプログラムの局所性を活用する GPU コンピューティング アーキテクチャに長年依存してきました。スレッド ブロックは、1 つの SM 上で同時に実行される複数のスレッドを含み、スレッドは高速なバリアで同期し、SM のシェアード メモリを使ってデータを交換することができます。しかし、GPU が 100 SM を超え、計算プログラムがより複雑になると、プログラミング モデルで表現される唯一の局所性の単位であるスレッド ブロックでは、実行効率を最大化するのに不十分となることが分かっています。
H100 では、1 つの SM 上の1つのスレッド ブロックよりも大きな粒度で局所性を制御できる、新しいスレッド ブロック クラスター アーキテクチャを導入しました。スレッド ブロック クラスターは、 CUDA プログラミング モデルを拡張し、GPU の物理プログラミング階層に、スレッド、スレッド ブロック、スレッド ブロック クラスター、グリッドを含む別のレベルを追加しています。
クラスターとは、複数の SM に同時スケジューリングされることが保証されているスレッド ブロックのグループで、複数の SM にまたがるスレッドの効率的な協調を可能にすることが目的です。H100 のクラスタは、GPC 内の SM 間で同時に実行されます。
GPC とは、ハードウェア階層において、常に物理的に近接している SM のグループのことです。クラスターには、ハードウェアで加速されたバリアと、次のセクションで説明する新しいメモリ アクセス連携機能があります。GPC 内の SM 専用の SM 間ネットワークは、クラスター内のスレッド間で高速なデータ共有を実現します。
CUDA では、図 11 に示すように、グリッド内のスレッド ブロックをカーネル 起動時にオプションでクラスターにグループ化でき、クラスター機能を CUDA cooperative_groups API から活用できる。
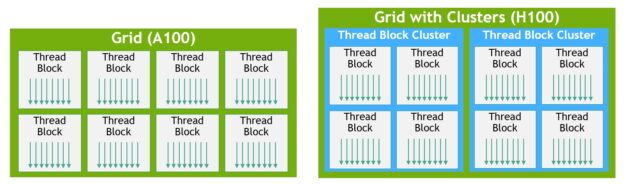
グリッドは、A100 のようなレガシー CUDA プログラミング モデルで、図の左半分に示すようにスレッド ブロックで構成されています。NVIDIA Hopper アーキテクチャ では、図の右半分に示すように、オプションでクラスター階層が追加されます。
分散型シェアードメモリ
クラスターでは、すべてのスレッドが他の SM の共有メモリにロード、ストア、アトミック操作で直接アクセスすることが可能です。この機能は、共有メモリの仮想アドレス空間がクラスター内のすべてのブロックに論理的に分散されていることから、分散共有メモリ (DSMEM) と呼ばれています。
DSMEM は、データの受け渡しのためにグローバル メモリへの書き込み、グローバル メモリからの読み出しが不要になり、SM 間でより効率的なデータ交換を可能にします。クラスター専用の SM 間ネットワークにより、遠隔地の DSMEM に高速かつ低レイテンシでアクセスすることができます。グローバル メモリの使用と比較して、DSMEM はスレッド ブロック間のデータ交換を約7倍に高速化します。
CUDA レベルでは、クラスター内のすべてのスレッド ブロックのすべての DSMEM セグメントが各スレッドの汎用アドレス空間にマッピングされ、すべての DSMEM が単純なポインターで直接参照できるようになっています。CUDA ユーザーは cooperative_groups API を利用して、クラスター内の任意のスレッド ブロックへの汎用ポインターを作成できます。DSMEM の転送は、完了を追跡するために共有メモリベースのバリアと同期した非同期コピー操作として表現することもできます。
図 13 は、異なるアルゴリズムでクラスターを使用した場合の性能上の利点を示しています。クラスターは、単一の SM よりも GPU のより大きな部分を直接制御することができるため、性能が向上します。クラスターは、単一のスレッド ブロックで可能なよりも大きな共有メモリのプールにアクセスすることで、より多くのスレッドと協調して実行することができます。
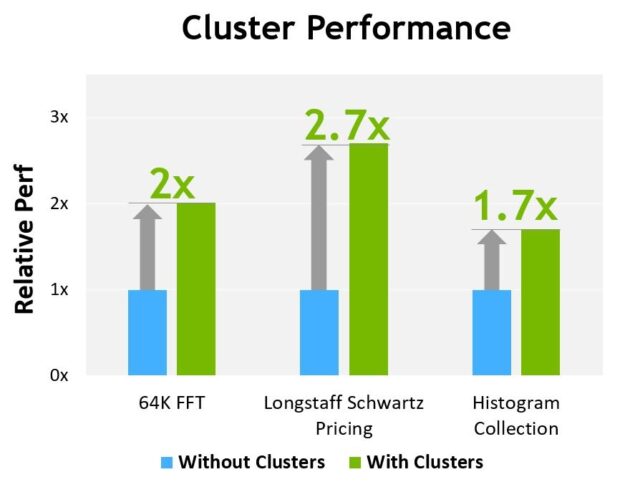
H100 の性能は現時点での予想であり、出荷製品で変更される可能性があります。
非同期実行
NVIDIA GPU の各新世代は、性能、プログラマビリティ、電力効率、 GPU 利用、その他多くの要素を改善するために、数多くのアーキテクチャの強化がなされています。最近の NVIDIA GPU 世代には、データ移動、計算、および同期の重複を可能にする非同期実行機能が含まれています。
NVIDIA Hopper アーキテクチャは、非同期実行を改善し、メモリ コピーと計算およびその他の独立した作業のさらなるオーバーラップを可能にすると同時に、同期ポイントを最小限に抑える新機能を提供します。Tensor Memory Accelerator (TMA) と呼ばれる新しい非同期メモリ コピー ユニットと新しい非同期トランザクション バリアについて説明します。
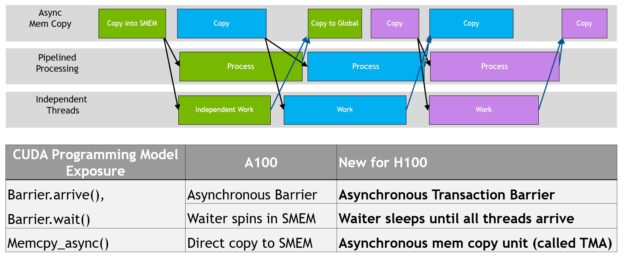
データ移動、計算、同期のプログラム上のオーバーラップ。非同期並行処理と同期ポイントの最小化が性能のカギとなる。
テンソル メモリ アクセラレータ
強力で新しい H100 Tensor コアのデータ処理を支援する為に、データ フェッチの効率が新しい Tensor Memory Accelerator (TMA) により改善されています。これにより、大きなデータ ブロックと多次元テンソルをグローバル メモリからシェアード メモリに転送したり、元に戻すことができるようになりました。
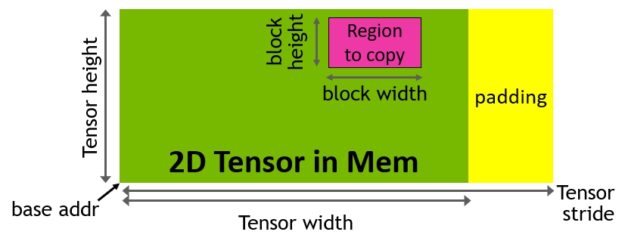
TMA の操作は、要素ごとのアドレス指定ではなく、テンソル次元とブロック座標でデータ転送を指定するコピー記述子を用いて起動されます (図 15) 。シェアード メモリ容量までの大きなデータ ブロックを指定し、グローバル メモリからシェアード メモリにロードしたり、シェアード メモリからグローバル メモリにストアしたりすることが可能です。TMA は、様々なテンソル レイアウト (1 次元 – 5 次元テンソル) 、異なるメモリ アクセス モード、リダクションおよびその他の機能サポートにより、アドレス指定の オーバーヘッドを大幅に削減し、効率を向上させることが可能です。
TMA 演算は非同期であり、A100 で導入されたシェアード メモリベースの非同期バリアを利用します。また、TMA プログラミング モデルはシングルスレッドであり、ワープ内の単一スレッドが選択されて非同期 TMA 操作 (cuda::memcpy_async) を発行し、テンソルをコピーします。その結果、複数のスレッドが cuda::barrier でデータ転送の完了を待つことができます。H100 SM では、さらに性能を向上させるために、これらの非同期バリア待ちの操作を高速化するハードウェアを追加しています。
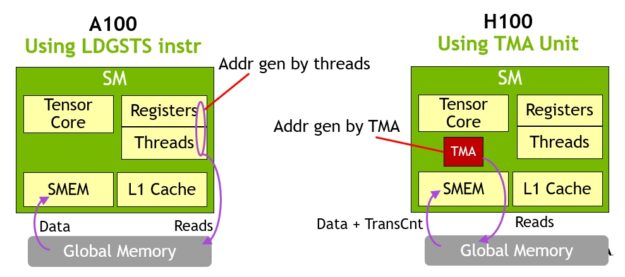
TMA の主な利点は、スレッドを解放して他の独立した作業を実行できることです。A100 (図 16、左) では、特殊な LoadGlobalStoreShared 命令を用いて非同期メモリ コピーを実行したため、スレッドはすべてのアドレスの生成とコピー領域全体のループを担当しました。
NVIDIA Hopper では、TMA がすべてを引き受けます。1 つのスレッドが TMA を起動する前にコピー ディスクリプタを作成し、それ以降のアドレス生成とデータ移動はハードウェアで処理されます。TMA は、テンソルのセグメントをコピーする際に、ストライド、オフセット、境界の計算を行うタスクを引き継ぐため、よりシンプルなプログラミング モデルを提供します。
非同期トランザクション バリア
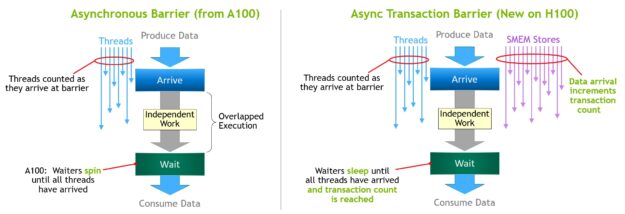
非同期バリアはもともと NVIDIA Ampere アーキテクチャで導入されたものです (図 17、左) 。一連のスレッドがデータを生成し、バリアの後にそのデータをすべて消費する例を考えてみましょう。非同期バリアは、同期化プロセスを 2 つのステップに分割します。
- まず、スレッドは共有データの自分の部分の生成が終わると、
Arriveのシグナルを送ります。このArriveはノンブロッキングで、スレッドは他の独立した作業を自由に行えるようになっています。 - 最終的に、スレッドは他のすべてのスレッドが生成したデータを必要とします。この時点で、彼らは
Waitを実行し、すべてのスレッドがArriveのシグナルを送るまで、それらをブロックします。
非同期バリアの利点は、早く到着したスレッドが待っている間に独立した作業を実行できることです。このオーバーラップが性能アップの源となります。すべてのスレッドに十分な独立した作業がある場合、すべてのスレッドがすでに到着しているので、Wait 命令はすぐに終了できるため、バリアは事実上解放されます。
NVIDIA Hopper の新機能は、待機中のスレッドが他のすべてのスレッドが到着するまでスリープすることです。以前のチップでは、待機中のスレッドはシェアード メモリ内のバリア オブジェクトでぐるぐると回っていました。
非同期バリアは今でも NVIDIA Hopper プログラミングモデルの一部ですが、非同期トラン ザクションバリアという新しい形式のバリアが追加されています。非同期トランザクションバリアは、非同期バリアと似ています (図 17、右) 。これも分割バリアですが、スレッドの到着だけをカウントするのではなく、トランザクションもカウントします。
NVIDIA Hopper には、共有メモリを書き込むための新しいコマンドが含まれており、書き込むデータとトランザクション カウントの両方を渡します。トランザクション カウントは基本的にバイト数です。非同期トランザクション バリアは、全てのプロデューサー スレッドが Arrive を実行し、全てのトランザクション カウントの合計が期待値に達するまで、Wait コマンドのところでスレッドをブロックします。
非同期トランザクション バリアは、非同期 mem コピーやデータ交換のための強力で新しいプリミティブです。先に述べたように、クラスターは暗黙の同期を伴うデータ交換のためにスレッド ブロック間通信を行うことができ、このクラスター機能は非同期トランザクション バリヤの上に構築されているのです。
H100 HBM と L2 キャッシュ メモリのアーキテクチャ
GPU のメモリ アーキテクチャと階層構造の設計は、アプリケーションの性能に大きく影響し、GPU サイズ、コスト、消費電力、プログラマビリティに影響を及ぼします。GPU には、オフチップ DRAM (フレーム バッファ) デバイス メモリ、さまざまなレベルやタイプのオンチップ メモリ、SM 内の演算に使用されるレジスタ ファイルなど、多くのメモリ サブシステムが存在します。
H100 HBM3 および HBM2e DRAM サブシステム
HPC、AI、データ分析のデータセットが増え続け、計算問題がますます複雑化する中、より大きな GPU メモリ容量とメモリ帯域幅が必要になってきています。
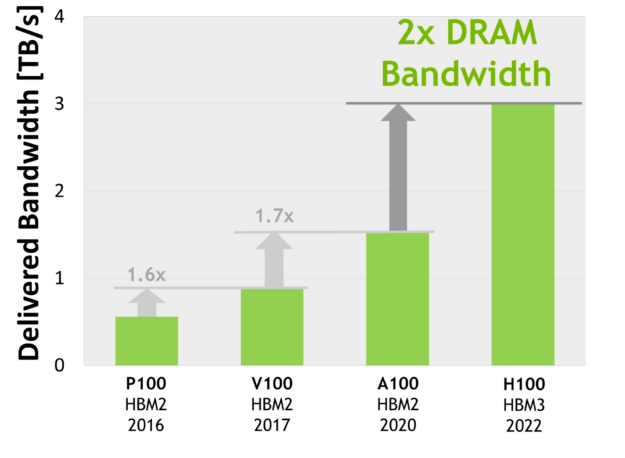
- NVIDIA P100 は、世界で初めて GPU アーキテクチャで高帯域幅の HBM2 メモリ技術に対応しました。
- NVIDIA V100 は、さらに高速、高効率、大容量の HBM2 の実装を実現しました。
- NVIDIA A100 GPU では、HBM2 の性能と容量をさらに向上させました。
H100 SXM5 GPU は、80GB (5 スタック) の高速 HBM3 メモリをサポートし、3 TB/秒以上のメモリ帯域幅を提供する事でレベルを大幅に引き上げます。これは、わずか 2 年前に発売されたばかりの A100 のメモリ帯域幅の実質 2 倍です。PCIe H100 は、80 GB の高速 HBM2e をサポートし、2 TB/sec 以上のメモリ帯域幅を実現します。
メモリ データのレートは最終決定されたものではなく、最終製品で変更される可能性があります。
H100 L2 キャッシュ
H100 の 50 MB L2 キャッシュは、A100 の 40 MB L2 に比べて 1.25 倍の容量となります。これにより、モデルやデータセットのさらに大きな部分をキャッシュして繰り返しアクセスすることが可能になり、HBM3 や HBM2e DRAM へのトリップを減らし、パフォーマンスを向上させることができます。
L2 キャッシュは、パーティション化されたクロスバー構造により、パーティションに直接接続された GPC の SM からのメモリ アクセスに対してデータを局所化し、キャッシュを行います。L2 キャッシュの常駐コントロールにより、キャッシュに残すべきデータと退避させるべきデータを選択的に管理し、容量利用を最適化することが可能です。
HBM3 または HBM2e DRAM と L2 キャッシュ サブシステムの両方が、メモリとキャッシュの使用と性能を最適化するデータ圧縮/伸張技術に対応しています。
| GPU Features | NVIDIA A100 | NVIDIA H100 SXM51 | NVIDIA H100 PCIe1 |
| GPU アーキテクチャ | NVIDIA Ampere | NVIDIA Hopper | NVIDIA Hopper |
| GPU ボード フォーム ファクタ | SXM4 | SXM5 | PCIe Gen 5 |
| SMs | 108 | 132 | 114 |
| TPCs | 54 | 66 | 57 |
| SM あたりの FP32 コア | 64 | 128 | 128 |
| GPU 全体での FP32 コア | 6912 | 16896 | 14592 |
| SM あたりの FP64 コア (Tensor コアを除く) | 32 | 64 | 64 |
| GPU 全体での FP64 コア (Tensor コアを除く) | 3456 | 8448 | 7296 |
| SM あたりの INT32 コア | 64 | 64 | 64 |
| GPU 全体での INT32 コア | 6912 | 8448 | 7296 |
| SM あたりの Tensor コア | 4 | 4 | 4 |
| GPU 全体での Tensor コア | 432 | 528 | 456 |
| GPU ブースト クロック (H100 は未確定) |
1410 MHz | 未確定 | 未確定 |
| Peak FP8 Tensor TFLOPS (FP16 累算)1 | N/A | 2000/40002 | 1600/32002 |
| Peak FP8 Tensor TFLOPS (FP32 累算)1 | N/A | 2000/40002 | 1600/32002 |
| Peak FP16 Tensor TFLOPS (FP16 累算)1 | 312/6242 | 1000/20002 | 800/16002 |
| Peak FP16 Tensor TFLOPS (FP32 累算)1 | 312/6242 | 1000/20002 | 800/16002 |
| Peak BF16 Tensor TFLOPS (FP32 累算)1 | 312/6242 | 1000/20002 | 800/16002 |
| Peak TF32 Tensor TFLOPS1 | 156/3122 | 500/10002 | 400/8002 |
| Peak FP64 Tensor TFLOPS1 | 19.5 | 60 | 48 |
| Peak INT8 Tensor TOPS1 | 624/12482 | 2000/40002 | 1600/32002 |
| Peak FP16 TFLOPS (non-Tensor)1 | 78 | 120 | 96 |
| Peak BF16 TFLOPS (non-Tensor)1 | 39 | 120 | 96 |
| Peak FP32 TFLOPS (non-Tensor)1 | 19.5 | 60 | 48 |
| Peak FP64 TFLOPS (non-Tensor)1 | 9.7 | 30 | 24 |
| Peak INT32 TOPS1 | 19.5 | 30 | 24 |
| テクスチャ ユニット数 | 432 | 528 | 456 |
| メモリ インターフェイス | 5120-bit HBM2 | 5120-bit HBM3 | 5120-bit HBM2e |
| メモリ サイズ | 40 GB | 80 GB | 80 GB |
| メモリ データ レート (H100 は未確定)1 |
1215 MHz DDR | Not finalized | Not finalized |
| メモリ帯域幅1 | 1555 GB/sec | 3000 GB/sec | 2000 GB/sec |
| L2 キャッシュ サイズ | 40 MB | 50 MB | 50 MB |
| SM あたりのシェアード メモリ サイズ | Configurable up to 164 KB | Configurable up to 228 KB | Configurable up to 228 KB |
| SM あたりのレジスタ ファイル サイズ | 256 KB | 256 KB | 256 KB |
| GPU 全体でのレジスタ ファイル ファイズ | 27648 KB | 33792 KB | 29184 KB |
| TDP1 | 400 Watts | 700 Watts | 350 Watts |
| トランジスタ数 | 54.2 billion | 80 billion | 80 billion |
| GPU ダイサイズ | 826 mm2 | 814 mm2 | 814 mm2 |
| TSMC 製造プロセス | 7 nm N7 | 4N customized for NVIDIA | 4N customized for NVIDIA |
- H100 の仕様は現時点での予想であり、出荷製品で変更される可能性があります。
- スパース性機能を用いた実効 TOPS / TFLOPS
H100 および A100 Tensor コア GPU は、高性能サーバーやデータ センターのラックに搭載して AI や HPC の計算ワークロードを強化することを目的としているため、ディスプレイ コネクタ、レイトレーシングを加速する NVIDIA RT コア、NVENC エンコーダーは含まれていません。
Compute Capability
H100 GPU は、新しい Compute Capability 9.0 に対応しています。表 4 は、NVIDIA GPU アーキテクチャの異なる Compute Capability のパラメーターを比較したものです。
| Data Center GPU | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 |
| GPU アーキテクチャ | NVIDIA Volta | NVIDIA Ampere | NVIDIA Hopper |
| Compute capability | 7.0 | 8.0 | 9.0 |
| Warp あたりのスレッド数 | 32 | 32 | 32 |
| SM あたりの最大 Warp 数 | 64 | 64 | 64 |
| SM あたりの最大スレッド数 | 2048 | 2048 | 2048 |
| SM あたりの 最大ブロック (CTA) 数 |
32 | 32 | 32 |
| クラスタあたりの最大ブロック数 | N/A | N/A | 16 |
| SM あたりの 最大 32 ビット レジスタ数 |
65536 | 65536 | 65536 |
| ブロック (CTA) あたりの 最大レジスタ数 |
65536 | 65536 | 65536 |
| スレッドあたりの最大レジスタ数 | 255 | 255 | 255 |
| 最大ブロック サイズ (スレッド数) | 1024 | 1024 | 1024 |
| SM あたりの FP32 コア数 | 64 | 64 | 128 |
| SM のレジスタとFP32コア数比 | 1024 | 1024 | 512 |
| SM あたりの シェアード メモリ サイズ |
Configurable up to 96 KB | Configurable up to 164 KB | Configurable up to 228 KB |
Transformer Engine
Transformer モデルは、 BERT から GPT-3 まで現在広く使われている言語モデルのバックボーンであり、膨大な計算資源を必要とします。当初は自然言語処理 (NLP) のために開発されましたが、コンピューター ビジョンや創薬など、多様な分野での応用が進んでいます。
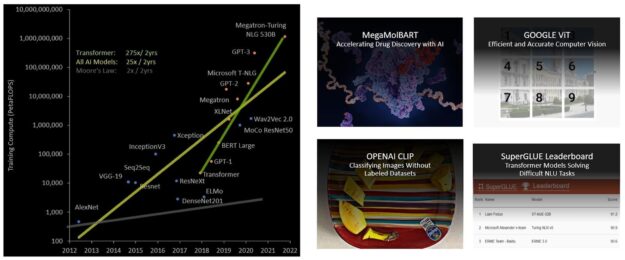
そのサイズは指数関数的に増加し続け、現在では数兆個のパラメーターに達しており、数か月にまで増加した学習時間は大量の計算リソースを必要とするため、ビジネスの観点から実用的ではありません。例えば、 Megatron Turing NLG (MT-NLG) の場合、2048 台の NVIDIA A100 GPU を 8 週間かけて学習させる必要があります。全体として、 transformer モデルは、過去 5 年間、2 年ごとに 275 倍の割合で、他のほとんどの AI モデルよりはるかに速く成長しています (図 19) 。
H100 には、ソフトウェアとカスタム NVIDIA Hopper Tensor コア テクノロジを用いて、 transformer の AI 計算を劇的に加速させる新しい Transformer Engine が搭載されています。
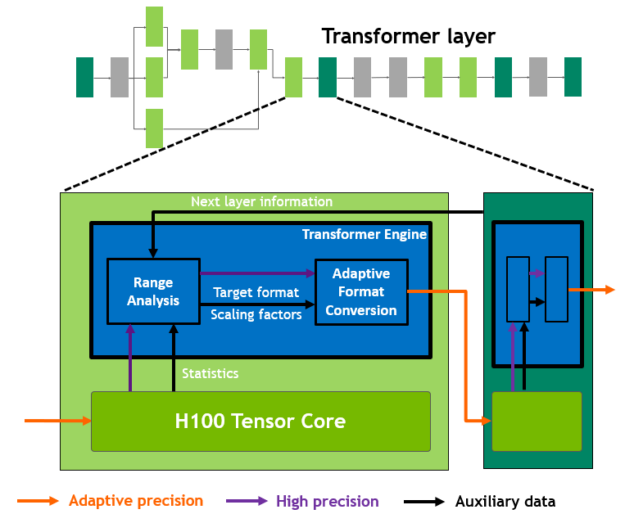
混合精度の目標は、精度をインテリジェントに管理して精度を維持しながら、より小さく高速な数値フォーマットの性能を得ることです。Transformer モデルの各レイヤーで、Transformer Engine は Tensor コアによって生成された出力値の統計量を分析します。
次に来るニューラル ネットワークの層の種類と、それが必要とする精度についての知識をもとに、Transformer Engine はテンソルをメモリに格納する前に、どのフォーマットに変換するかも決定します。FP8 の表現できる範囲は、他の数値フォーマットよりも限定されています。
利用可能な範囲を最大限利用するために、 Transformer Engine はテンソルの統計量から計算されるスケーリング係数を用いて、テンソル データを表現可能な範囲へ動的にスケーリングします。そのため、各レイヤーは必要な範囲の中で動作し、最適な方法で加速されます。
第 4 世代 NVLink と NVLink ネットワーク
エクサスケール HPC や超人的な対話型 AI のようなタスクのための 1 兆パラメーター AI モデルの新興クラスは、スーパーコンピューターでもトレーニングに数か月を必要とします。この長い学習時間を数か月から数日に短縮し、よりビジネスに役立てるためには、サーバー クラスターの各 GPU 間で高速かつシームレスな通信を行う必要があります。PCIe は帯域が限られているため、ボトルネックになってしまいます。最もパワフルなエンドツーエンド コンピューティング プラットフォームを構築するためには、より高速でスケーラブルな NVLink インターコネクトが必要なのです。
NVLink は、NVIDIA の高帯域幅、高エネルギー効率、低レイテンシ、ロスレスの GPU 間 インターコネクトで、リンクレベルのエラー検出やパケット再送メカニズムなどのレジリエンス機能を備え、データの正常伝送を保証するものです。新しい第 4 世代の NVLinkは、H100 GPU に実装され、NVIDIA A100 Tensor コア GPU で使用されている従来の第 3 世代 NVLink と比較して、1.5 倍の通信帯域幅を実現します。
マルチ GPU I/O および共有メモリアクセスで 900 GB/秒の総帯域幅で動作する新しい NVLink は、PCIe Gen 5 の 7 倍の帯域幅を提供します。A100 GPU の第 3 世代 NVLink は、各方向に 4 つの差動ペア (レーン) を使用して単一のリンクを作成し、各方向に 25 GB/秒の有効帯域幅を提供します。これに対し、第 4 世代 NVLink は、各方向に 2 つの高速差動ペアのみを使用して 1 つのリンクを形成し、同じく各方向に 25 GB/秒の実効帯域幅を実現します。
- H100 は、18 本の第 4 世代 NVLink リンクを搭載し、合計 900 GB/秒の帯域幅を実現しています。
- A100 は、12 本の第 3 世代 NVLink リンクを搭載し、合計 600 GB/秒の帯域幅を実現しています。
第 4 世代の NVLink に加えて、H100 では、新しい NVLink ネットワーク インターコネクトを導入しました。これは、複数の計算ノードに渡る最大 256 GPU での GPU 間通信を可能にする NVLink のスケーラブルなバージョンです。
すべての GPU が共通のアドレス空間を共有し、 GPU 物理アドレスを使用して直接リクエストをルーティングする通常の NVLink とは異なり、NVLink ネットワークでは新しいネットワーク アドレス空間を導入しています。これは、H100 の新しいアドレス変換ハードウェアによってサポートされ、すべての GPU アドレス空間を互いに分離し、ネットワーク アドレス空間からも分離します。これにより、NVLink Network は、より多くの GPU に安全に拡張することができます。
NVLink ネットワークのエンドポイントは、共通のメモリ アドレス空間を共有していないため、NVLink ネットワークの接続は、システム全体で自動的に確立されるわけではありません。その代わり、InfiniBand などの他のネットワーキング インターフェイスと同様に、ユーザー ソフトウェアは必要に応じてエンドポイント間の接続を明示的に確立する必要があります。
第 3 世代 NVSwitch
新しい第 3 世代の NVSwitch テクノロジには、ノードの内側と外側の両方に存在するスイッチがあり、サーバー、クラスター、およびデータ センター環境において複数の GPU を接続します。ノード内の各第 3 世代 NVSwitch は、第 4 世代 NVLink リンクを 64 ポート備え、マルチ GPU の接続を加速させることができます。スイッチの総スループットは、前世代の 7.2 Tbits/sec から 13.6 Tbits/sec に向上しています。
新しい第 3 世代の NVSwitch は、マルチキャストと NVIDIA SHARP ネットワーク内リダクションによる集合演算のハードウェア アクセラレーションも提供します。高速化されたコレクティブには、write broadcast (all_gather) 、reduce_scatter、broadcast atomics が含まれます。ファブリック内マルチキャストとリダクションにより、A100 で NVIDIA 集合通信ライブラリ (NCCL) を使用した場合と比較して、小さいブロック サイズのコレクティブでレイテンシを大幅に削減しながら最大 2 倍のスループット向上を実現します。NVSwitch によるコレクティブの加速により、集合通信のための SM の負荷が大幅に軽減されます。
新しい NVLink Switch システム
新しい NVLink ネットワーク技術と新しい第 3 世代 NVSwitch を組み合わせることで、NVIDIA は前例のない水準の通信帯域を持つ、大規模なスケールアップした NVLink Switch システム ネットワークを構築することができます。各 GPU ノードでは、ノード内の GPU の全 NVLink 帯域幅を 2:1 のテーパード レベルで公開します。ノードは、コンピュート ノードの外側に存在し、複数のノードを共に接続する NVLink Switch モジュールに含まれる、第 2 レベルの NVSwitch を介して互いに接続されます。
NVLink Switch システムは、最大 256 GPU まで対応します。接続されたノードは 57.6 TB の All-to-all 帯域幅を実現し、FP8 スパース AI 計算において 1 exaFLOP という驚異的な数値を供給することが可能です。
図 21 は、A100 ベースと H100 ベースの 32 ノード、256 GPU の DGX SuperPOD を比較したものです。H100 ベースの SuperPOD では、オプションとして新しい NVLink Switch を使用して DGX ノードの相互接続を行います。
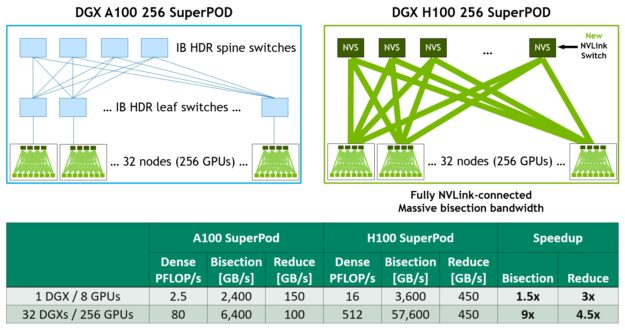
DGX H100 SuperPOD は、第 3 世代の NVSwitch 技術に基づく新しい NVLink Switch を使用して、NVLink Switch システム上で完全に接続された最大 256 GPU に拡張することが可能です。
2:1 テーパード ファット ツリー トポロジの NVLink ネットワーク インターコネクトは、前世代の InfiniBand システムに比べ、例えば All-to-all エクスチェンジではバイセクション帯域幅を 9 倍に、All-Reduce スループットを 4.5 倍にする驚異的な増加を実現しました。DGX H100 SuperPOD には、NVLink Switch システムがオプションで用意されています。
PCIe Gen 5
H100 は、PCI Express Gen5 x 16 のレーン インターフェイスを搭載し、A100 に含まれる PCIe Gen4 の総帯域幅 64 GB/秒 (各方向 32 GB/秒) に対し、128 GB/秒 (各方向 64 GB/秒) の総帯域幅を実現しています。
H100 は、PCIe Gen5 インターフェイスを使用して、最高性能の x86 CPU や SmartNIC および データ プロセシング ユニット (DPU) と接続することが可能です。H100 は、安全な HPC および AI ワークロードを実現するための、NVIDIA BlueField-3 DPU による 400 Gb/s Ethernet または Next Data Rate (NDR) 400 Gb/s InfiniBand ネットワーク アクセラレーションによる、最適な接続性のために設計されています。
H100 では、32 ビットおよび 64 ビット データ型に対するアトミック CAS、アトミック Exchange、アトミック Fetch Add といったネイティブ PCIe アトミック演算をサポートし、 CPU と GPU 間の同期とアトミック演算を加速させます。また、H100 はシングル ルート入出力仮想化 (SR-IOV) をサポートしており、単一の PCIe 接続された GPU を複数のプロセスやVMで共有し仮想化することが可能です。H100 は、単一の SR-IOV PCI 接続の GPU から、NVLink を介して相手の GPU にアクセスする仮想機能 (VF) または物理機能 (PF) を可能にします。
まとめ
アプリケーションのパフォーマンスを向上させるその他の H100 の新機能や改良点の詳細については NVIDIA H100 Tensor コア GPU アーキテクチャ ホワイトペーパーをご覧ください。
謝辞
Stephen Jones、Manindra Parhy、Atul Kalambur、Harry Petty、Joe DeLaere、Jack Choquette、Mark Hummel、Naveen Cherukuri、Brandon Bell、Jonah Alben、そしてこの投稿にご協力いただいた多くの NVIDIA GPU 設計者とエンジニアに感謝いたします。
翻訳に関する免責事項:
この記事は、「NVIDIA Hopper Architecture In-Depth」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。