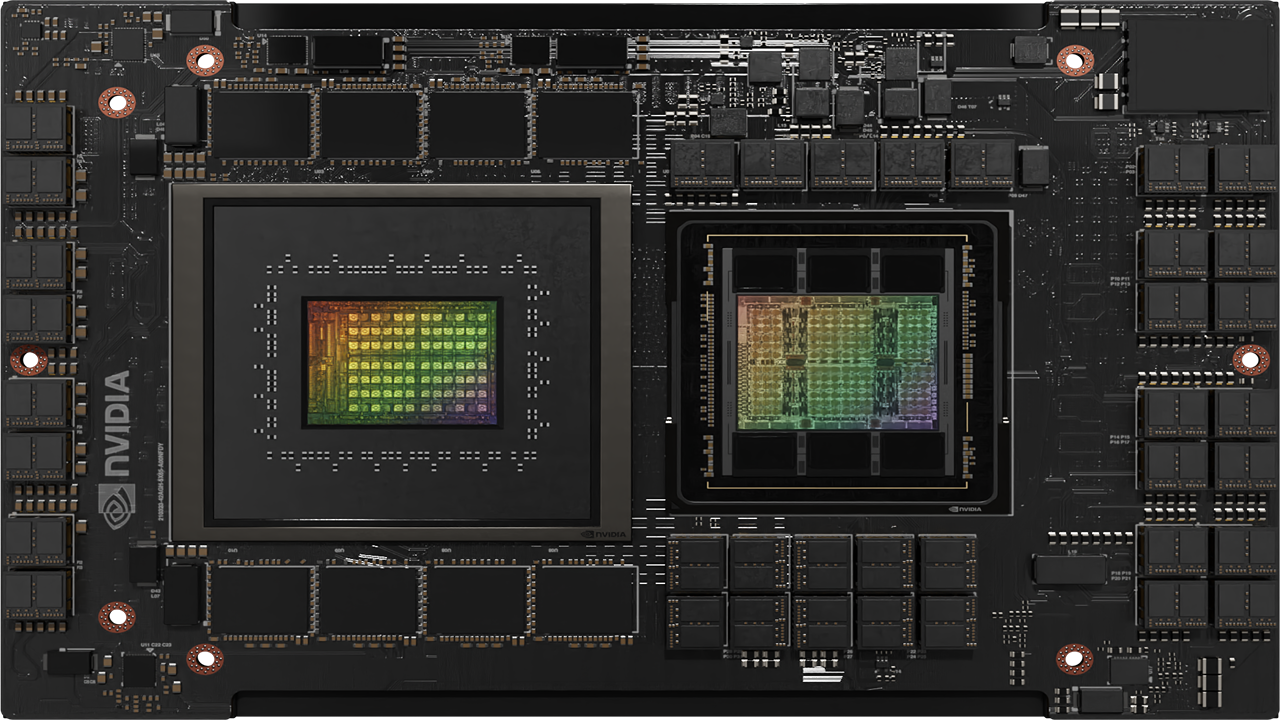
NVIDIA Grace CPU は、NVIDIA が開発した初のデータ センター向け CPU です。世界初のスーパーチップを実現するために、ゼロから作り上げられました。
デジタル ツイン、クラウド ゲーミングとグラフィックス、AI、ハイパフォーマンス コンピューティング (HPC) を強化する現代のデータ センターのワークロードの要求を満たすために、優れた性能とエネルギー効率を実現するように設計された NVIDIA Grace CPU は、Arm Scalable Vector Extensions version 2 (SVE2) 命令セットを実装する 72 基の Armv9 CPU コアを搭載しています。また、このコアは、ネストされた仮想化機能と S-EL2 サポートを備えた仮想化拡張機能を内蔵しています。
また、NVIDIA Grace CPU は、以下の Arm 仕様に準拠しています。
- RAS v1.1 汎用割り込みコントローラー (GIC) v4.1
- メモリ パーティショニングとモニタリング (MPAM)
- システム メモリ管理ユニット (SMMU) v3.1
Grace CPU は、NVIDIA Hopper GPU と組み合わせて、大規模な AI トレーニング、推論、HPC 向けの NVIDIA Grace Hopper Superchip を構築するか、別の Grace CPU と組み合わせて、HPC やクラウド コンピューティング ワークロードのニーズを満たす高性能 CPU を構築するために開発されました。
Grace CPU の主な特徴については、以下を読み進めてください。
NVLink-C2C による高速チップ間インターコネクト
Grace Hopper Superchip と Grace CPU Superchip は、いずれもスーパーチップ通信のバックボーンとなる NVIDIA NVLink-C2C 高速チップ間インターコネクトによって実現されています。
NVLink-C2C は、サーバー内の複数の GPU を接続するために使用される NVIDIA NVLink を拡張し、NVLink Switch System を使用すれば、複数の GPU ノードを接続することができます。
パッケージ上のダイ間で 900 GB/秒そのままの双方向帯域幅を持つ NVLink-C2C は、PCIe Gen 5 x 16 リンクの 7 倍の帯域幅 (NVLink 使用時に NVIDIA Hopper GPU 間で利用できる帯域幅と同じ) と低レイテンシを実現します。また、NVLink-C2C は、わずか1.3 ピコジュール/ビットの発熱で済み、PCIe Gen 5 の 5 倍以上のエネルギー効率となります。
NVLink-C2C はコヒーレントなインターコネクトでもあり、Grace CPU スーパーチップを用いた標準的なコヒーレント CPU プラットフォームと、Grace Hopper Superchip を用いたヘテロジニアス プログラミング モデルの両方をプログラミングする際に一貫性を持たせることが可能です。
NVIDIA Grace CPU 搭載の標準規格準拠のプラットフォーム
NVIDIA Grace CPU Superchip は、ソフトウェア開発者に標準に準拠したプラットフォームを提供するために構築されています。Arm は、Arm エコシステムに標準化をもたらすことを目的とした SystemReady イニシアチブの一環として、一連の仕様を提供しています。
Grace CPU は、Arm システム規格をターゲットとして、既製のオペレーティング システムやソフトウェア アプリケーションとの互換性を提供し、Grace CPU は最初から NVIDIA Arm ソフトウェア スタックを活用することにしています。
また、Grace CPU は Arm Server Base System Architecture (SBSA) に準拠しており、標準に準拠したハードウェアおよびソフトウェア インターフェイスを実現します。さらに、Grace CPU 搭載システムで標準的なブート フローを実現するために、Grace CPU は Arm Server Base Boot Requirements (SBBR) に対応するよう設計されています。
キャッシュと帯域のパーティショニング、および帯域のモニタリングのために、Grace CPU は Arm Memory Partitioning and Monitoring (MPAM) もサポートしています。
Grace CPU には Arm Performance Monitoring Unit も含まれており、CPU コアだけでなく、システム オン チップ (SoC) アーキテクチャ内の他のサブシステムのパフォーマンスも監視することが可能です。これにより、Linux perf などの標準的なツールを使って性能調査を行うことができます。
Grace Hopper Superchip 搭載ユニファイド メモリ
Grace CPU と Hopper GPU を組み合わせた NVIDIA Grace Hopper Superchip は、CUDA 8.0 で初めて導入された CUDA ユニファイド メモリ プログラミング モデルを発展させたものです。
NVIDIA Grace Hopper Superchip は、共有ページ テーブルを持つユニファイド メモリを導入し、Grace CPU と Hopper GPU が CUDA アプリケーションでアドレス空間とページ テーブルまで共有できるようにしました。
Grace Hopper GPU はページング可能なメモリ割り当てにアクセスすることもできます。Grace Hopper Superchip では、プログラマがシステム アロケーターを使って GPU のメモリを割り当てることができ、GPU と malloc メモリへのポインターを交換できる機能もあります。
NVLink-C2C は、Grace CPU と Hopper GPU 間のネイティブな atomic のサポートを可能にし、CUDA 10.2 で初めて導入された C++ atomic の可能性を完全に解き放ちます。
NVIDIA Scalable Coherency Fabric
Grace CPU は、NVIDIA Scalable Coherency Fabric (SCF) を採用しています。NVIDIA によって設計された SCF は、データ センターのニーズに合わせて拡張できるように設計されたメッシュ ファブリックと分散キャッシュです。SCF は、NVLink-C2C、CPU コア、メモリ、システム IO 間のデータ トラフィックの流れを確保するために、3.2 TB/秒のバイセクション帯域幅を提供します。
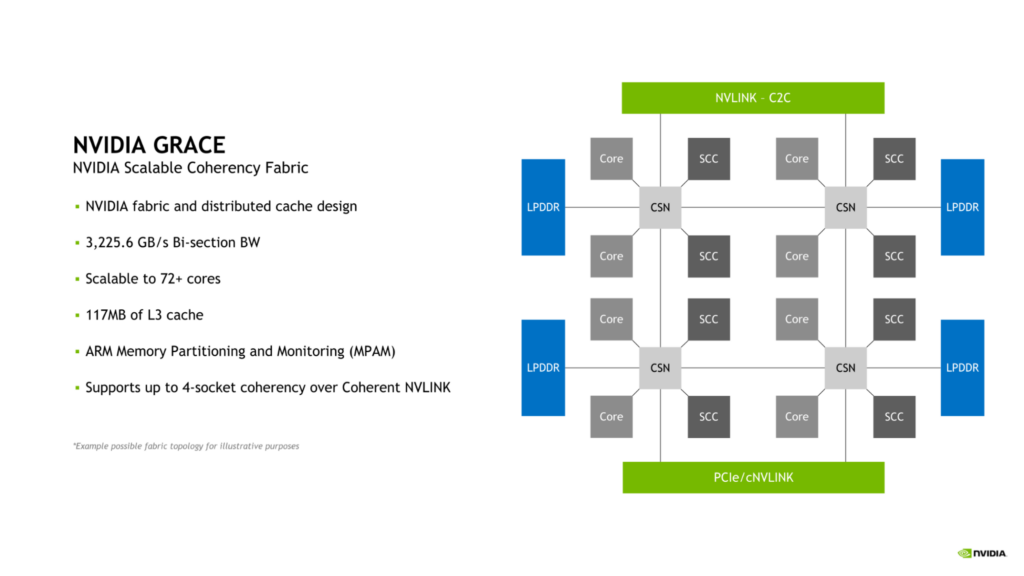
1 基の Grace CPU では、72 個の CPU コアと 117 MB のキャッシュを内蔵していますが、SCF はこの構成を超えてスケーラビリティを確保できるように設計されています。2 つの Grace CPU を組み合わせて Grace Superchip を構成すると、それぞれ 144 個の CPU コアと 234 MB の L3 キャッシュに倍増されます。
CPU コアと SCF キャッシュ パーティション (SCC) はメッシュ全体に分散配置されています。キャッシュ スイッチ ノード (CSNs) は、ファブリックを介してデータをルーティングし、CPU コア、キャッシュ メモリ、およびシステムの残りの部分の間のインターフェイスとして機能し、全体的に高帯域幅を可能にします。
メモリ パーティショニングとモニタリング
Grace CPU は、システム キャッシュとメモリ リソースのパーティショニングのための Arm 標準である MPAM (Memory System Resource Partitioning and Monitoring) 機能をサポートしています。
MPAM は、システム内の要求元にパーティション ID (PARTID) を割り当てることで機能します。この設計により、キャッシュ容量やメモリ帯域幅などのリソースを、それぞれの PARTID に基づいてパーティショニングまたは監視することが可能になります。
Grace CPU の SCF キャッシュは、MPAM を使用してキャッシュ容量とメモリ帯域幅の両方のパーティショニングをサポートしています。さらに、PMG (Performance Monitor Groups) を使って、リソースの使用状況を監視することもできます。
メモリ サブシステムで帯域とエネルギー効率を向上させる
優れた帯域幅とエネルギー効率を実現するために、Grace CPU は 32 チャネルの LPDDR5X メモリ インターフェイスを実装しています。これにより、最大 512 GB のメモリ容量と最大 546 GB/秒 のメモリ帯域幅を提供します。
拡張 GPU メモリ
Grace Hopper Superchip の鍵となる機能は、Extended GPU Memory (EGM) の採用です。より大きな NVLink ネットワークから接続された任意の Hopper GPU が、Grace Hopper Superchip の Grace CPU に接続された LPDDR5X メモリにアクセスできるようにすることで、GPU が利用できるメモリ プールが大幅に拡張されます。
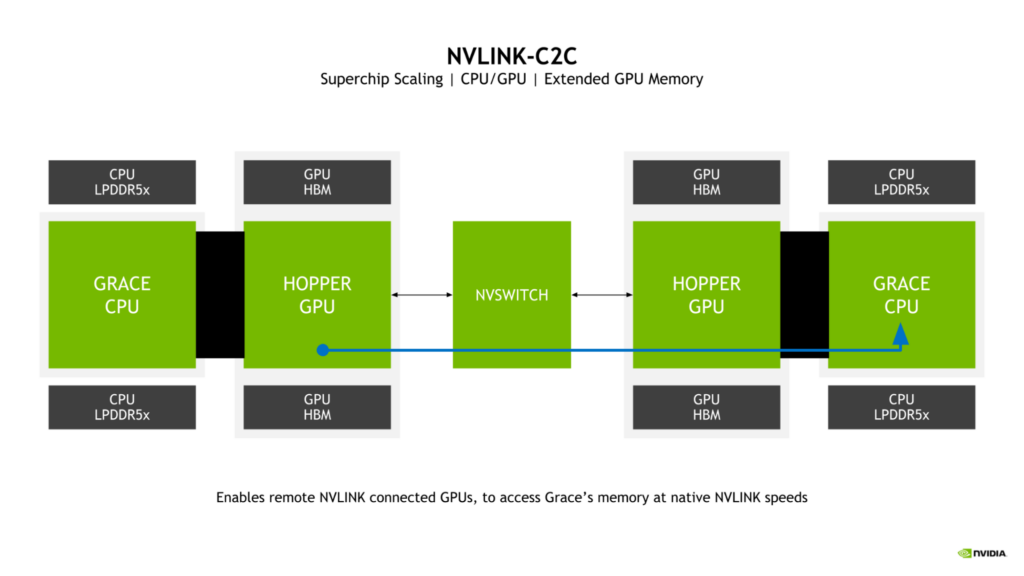
GPU 間の NVLink と NVLink-C2C の双方向帯域幅をスーパーチップで一致させ、Hopper GPU が NVLink 本来の速度で Grace CPU メモリにアクセスできるようにしています。
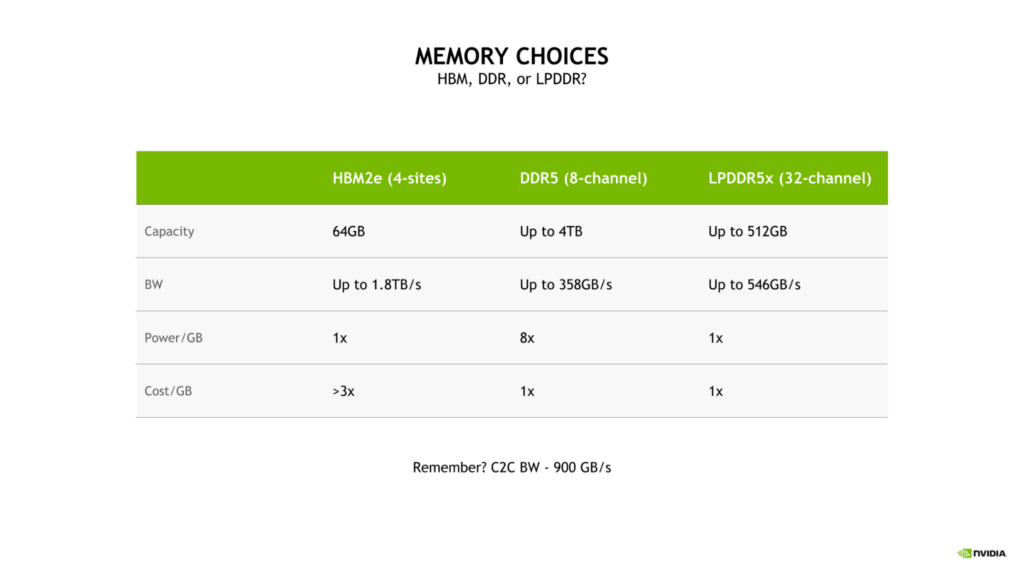
LPDDR5X による帯域幅とエネルギー効率のバランス
Grace CPU に LPDDR5X を選択したのは、大規模な AI や HPC のワークロードに対応するため、帯域、エネルギー効率、容量、コストの最適なバランスをとる必要があるためです。
4 サイトの HBM2e メモリ サブシステムは、かなりのメモリ帯域幅と優れたエネルギー効率を提供しますが、ギガバイトあたりのコストが DDR5 または LPDDR5X の 3 倍以上となります。
さらに、このような構成では、メモリ容量が LPDDR5X を搭載した Grace CPU の最大容量の 8 分の 1 である 64 GB に制限されます。
従来の 8 チャネル DDR5 設計と比較して、Grace CPU の LPDDR5X メモリ サブシステムは最大 53% 増の帯域幅を提供し、ギガバイトあたりの消費電力はわずか 8 分の 1 と、大幅に電力効率が向上しています。
LPDDR5X の優れた電力効率により、CPU コアや GPU ストリーミング マルチプロセッサ (SM) などのコンピューティング リソースに総電力量の多くを割り当てることができます。
NVIDIA Grace CPU の I/O
Grace CPU は、最新のデータ センターのニーズに対応するために、高速 I/O を搭載しています。Grace CPU SoC は、最大 68 レーンの PCIe 接続と、最大 4 つの PCIe Gen 5 x16 リンクを提供します。各 PCIe Gen 5 x16 リンクは、最大 128 GB/秒の双方向帯域幅を提供し、さらに接続性を高めるために 2 つの PCIe Gen 5 x8 リンクに分岐させることが可能です。
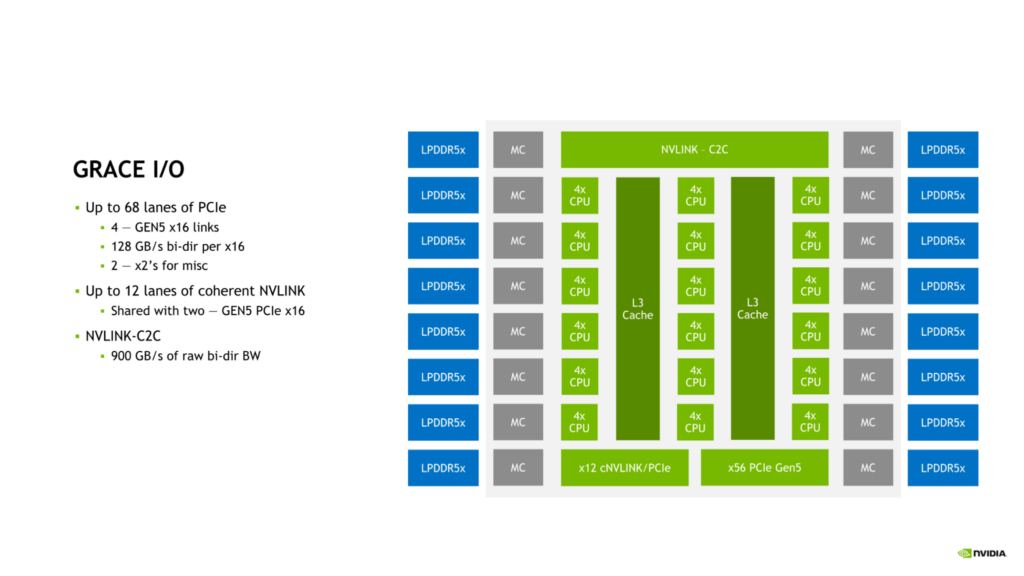
この接続性は、Grace CPU を別の Grace CPU または NVIDIA Hopper GPU に接続するために使用できるオンダイの NVLink-C2C リンクに加えられます。
NVLink、NVLink-C2C、PCIe Gen 5 の組み合わせにより、Grace CPU は、最新のデータ センターで性能を拡張するために必要な豊富な接続オプションと十分な帯域幅を提供します。
NVIDIA Grace CPU の性能
NVIDIA Grace CPU は、シングルチップおよび Grace Superchip の両方の構成で優れた計算性能を発揮するように設計されており、SPECrate2017_int_base の推定スコアはそれぞれ 370 および 740 です。これらのプレシリコン推定値は、GNU Compiler Collection (GCC) を使用した場合の値です。
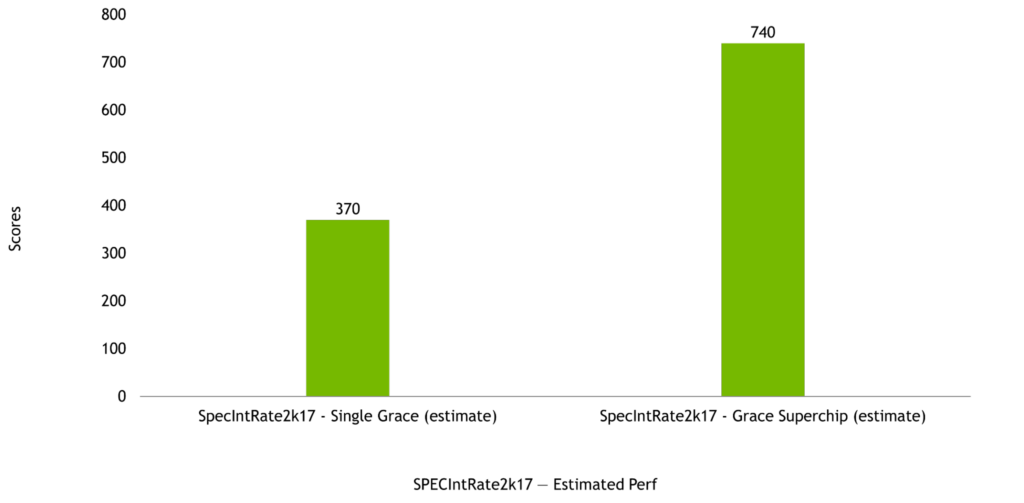
Grace CPU が設計されたワークロードでは、メモリ帯域幅が非常に重要です。Stream Benchmark では、1 つの Grace CPU で最大 536 GB/秒の帯域幅を実現し、チップのピーク理論帯域幅の 98% 以上になると予想されています。
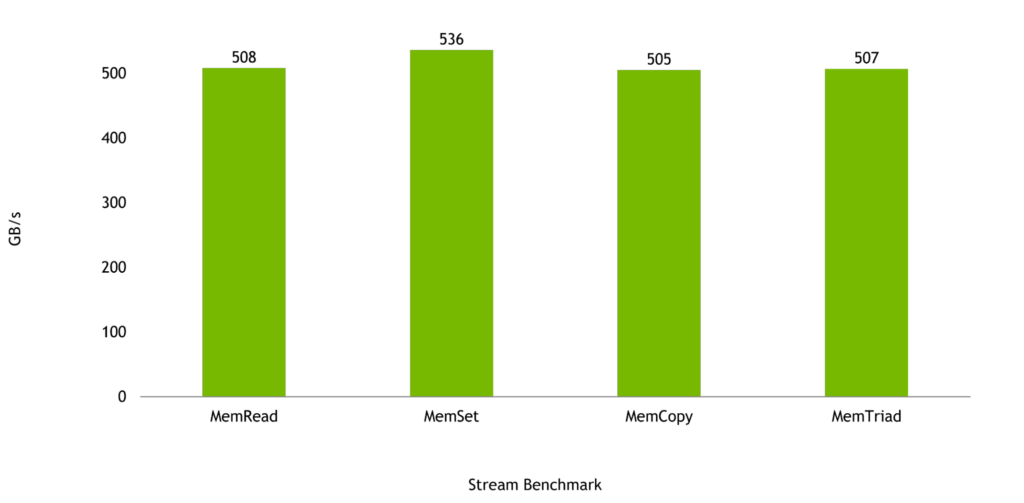
そして最後に、Hopper GPU と Grace CPU 間の帯域幅は、Grace Hopper Superchip の性能を最大化するために非常に重要です。GPU から CPU へのメモリの読み出しと書き込みはそれぞれ 429 GB/秒と 407 GB/秒と予想され、これは NVLink-C2C の理論ピーク片方向転送速度の 95% 以上と 90% 以上となります。
読み出しと書き込みを合わせた性能は 506 GB/秒となる見込みで、これは 1 つの NVIDIA Grace CPU SoC で利用できる理論ピークメモリ帯域幅の 92% 以上に相当します。
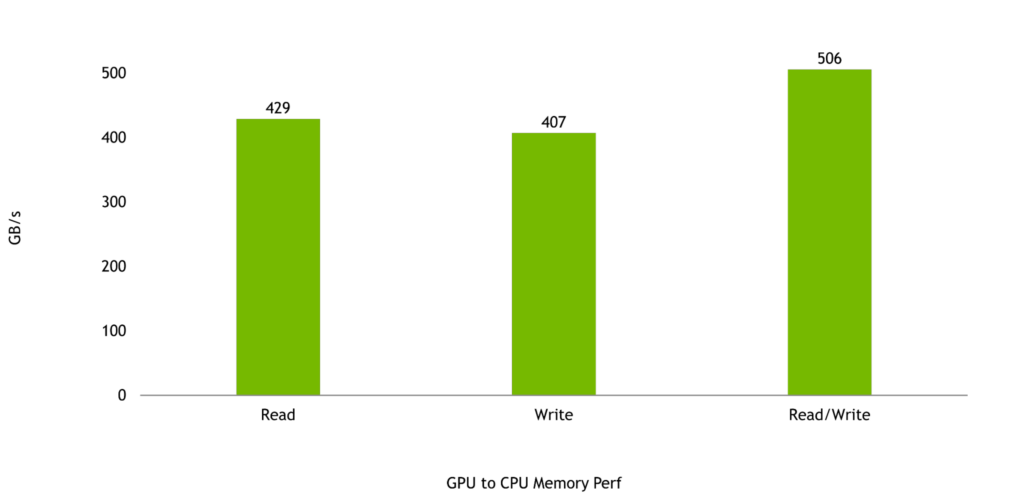
NVIDIA Grace CPU Superchip のメリット
144 コアと 1 TB/秒のメモリ帯域幅を持つ NVIDIA Grace CPU Superchip は、CPU ベースの高性能コンピューティング アプリケーションに前例のない性能を提供します。HPC アプリケーションは計算負荷が高いため、成果を加速するために、最高性能のコア、最高のメモリ帯域幅、コアごとの適切なメモリ容量が要求されます。
NVIDIA は、Grace CPU Superchipについて、HPC、スーパーコンピューティング、ハイパースケール、クラウドの大手企業と協力しており、Grace CPU Superchip と Grace Hopper Superchip は、2023 年前半に発売される予定です。
NVIDIA Grace Hopper Superchip と NVIDIA Grace CPU Superchip の詳細については、NVIDIA Grace CPU をご覧ください。