
本日、NVIDIA は早期アクセス (EA) 向けの cuFFTMp をリリースしたことを発表しました。cuFFTMp は、cuFFT のマルチノード、マルチプロセス拡張で、科学者やエンジニアがエクサスケール プラットフォーム上で難題を解けるようにするものです。
FFT (高速フーリエ変換) は、分子動力学、信号処理、CFD (数値流体力学) からワイヤレス マルチメディア、機械学習アプリケーションまで、様々な分野で広く利用されています。NVIDIA は cuFFTMp により、単一システム内の複数の GPU だけでなく、複数ノードにまたがる多数の GPU をサポートするようになりました。
図 1 は、cuFFTMp が 1.8PFlop/s 以上に達し、この規模の変換におけるピーク時のマシン バンド幅の 70% 以上に相当することを示しています。
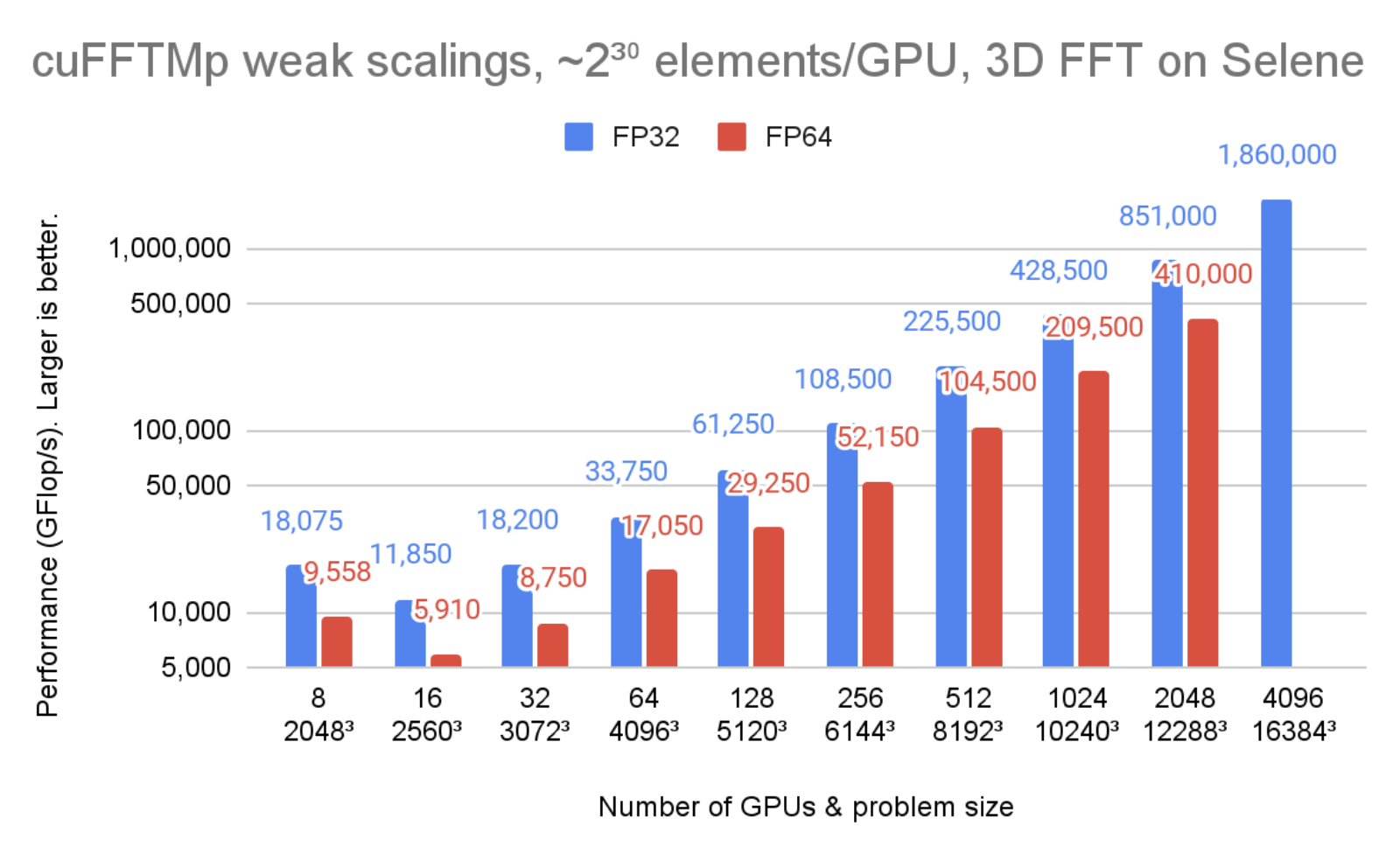
図 2 では、問題サイズはそのままに、 GPU の数が 8 から 2048 に増やされました。cuFFTMp が問題の強スケーリングに成功し、単精度時間が 8 GPU (1 ノード) で 78ms から、2048 GPU (256 ノード) で 4ms になったことがわかります。
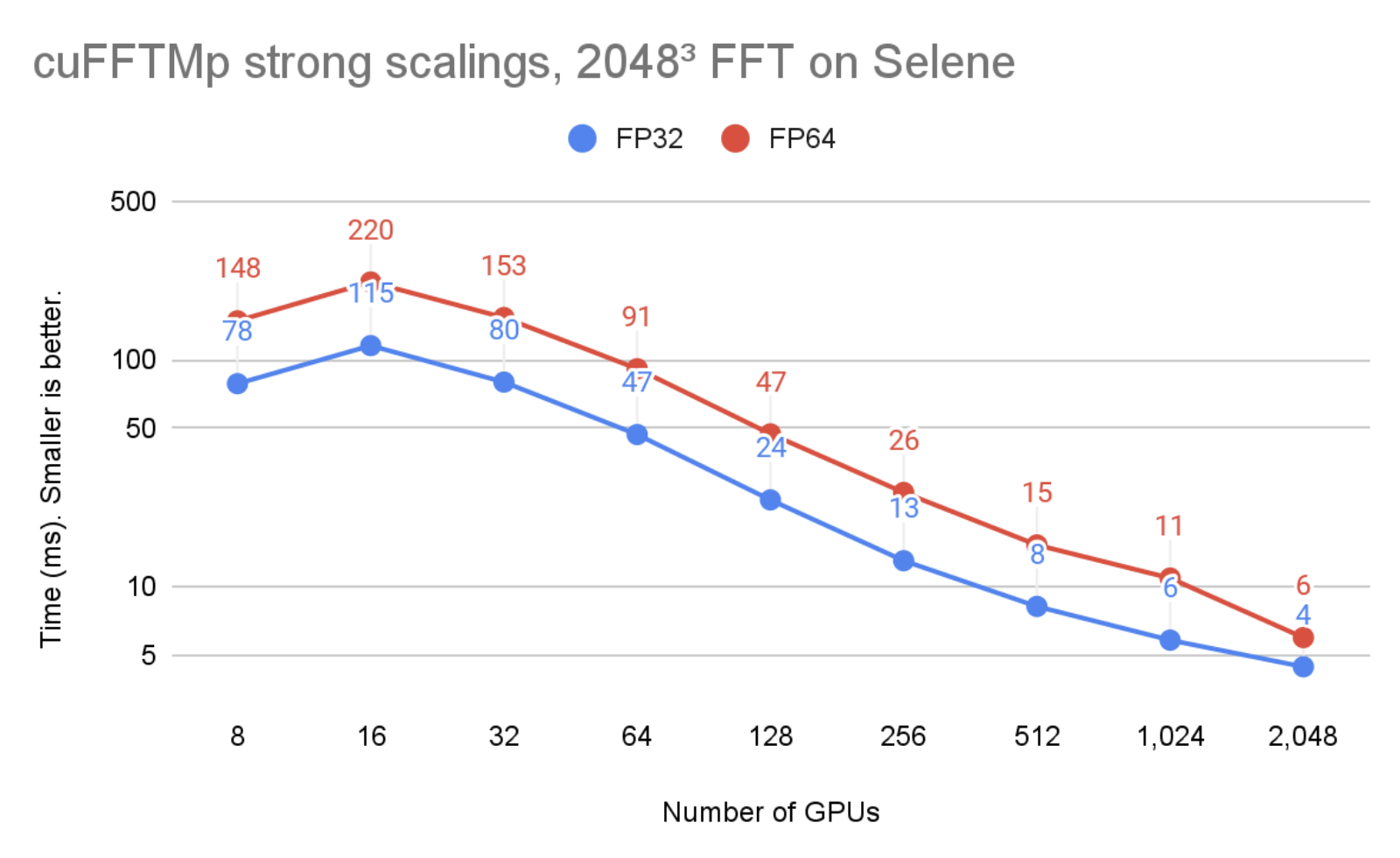
図 1、図 2 は Selene クラスター上で実行したものです。Selene は NVIDIA DGX A100 、ノードあたり 8xA100-80GB で NVSwitch (300GB/s/GPU、双方向) 、Mellanox Infiniband HDR (200GB/s/node、双方向) で構成されています。テストは CUDA 11.4 と、nvcr.io/NVIDIA/nvhpc:21.9-runtime-cuda11.4-ubuntu20.04 で入手できる NVIDIA HPC SDK 21.9 Docker コンテナーで実行されました。 GPU アプリケーション クロックは最大に設定しました。
パフォーマンスとスケーラビリティ
分散 3 次元 FFT は、MPI_Alltoallv 型のグローバル集団通信のため、通信律速であることがよく知られています。MPI_Alltoallv は、高い計算能力に対してノード間バンド幅が小さいため、分散 FFT の主なボトルネックとなり、all_to_all タイプの通信のアクセラレータ対応 MPI 実装は品質にばらつきがあります。
cuFFTMp は、OpenSHMEM 規格に基づき、カーネル主導の通信を実現することで NVIDIA GPU のために設計された新しい通信ライブラリ NVSHMEM を使用しています。NVSHMEM は、クラスター内のすべての GPU のメモリを含むグローバル アドレス空間を作成します。CUDA カーネル内部から通信を行うことで、きめ細かなリモート データ アクセスが可能になり、同期コストを削減するとともに、GPU の大規模な並列性を利用して通信オーバーヘッドを隠蔽することができます。
NVSHMEM を使用することで、cuFFTMp は MPI 実装の品質に依存しません。これは、MPI ごとに性能が大きく異なる可能性があるため、非常に重要なことです。詳細については、 Interim Report on Benchmarking FFT Libraries on High Performance Systems の第 3 章 を参照してください。
図 3 より、 GPU の数を 2 倍にしても、cuFFTMp は約 75% のピークを維持できていることがわかります。
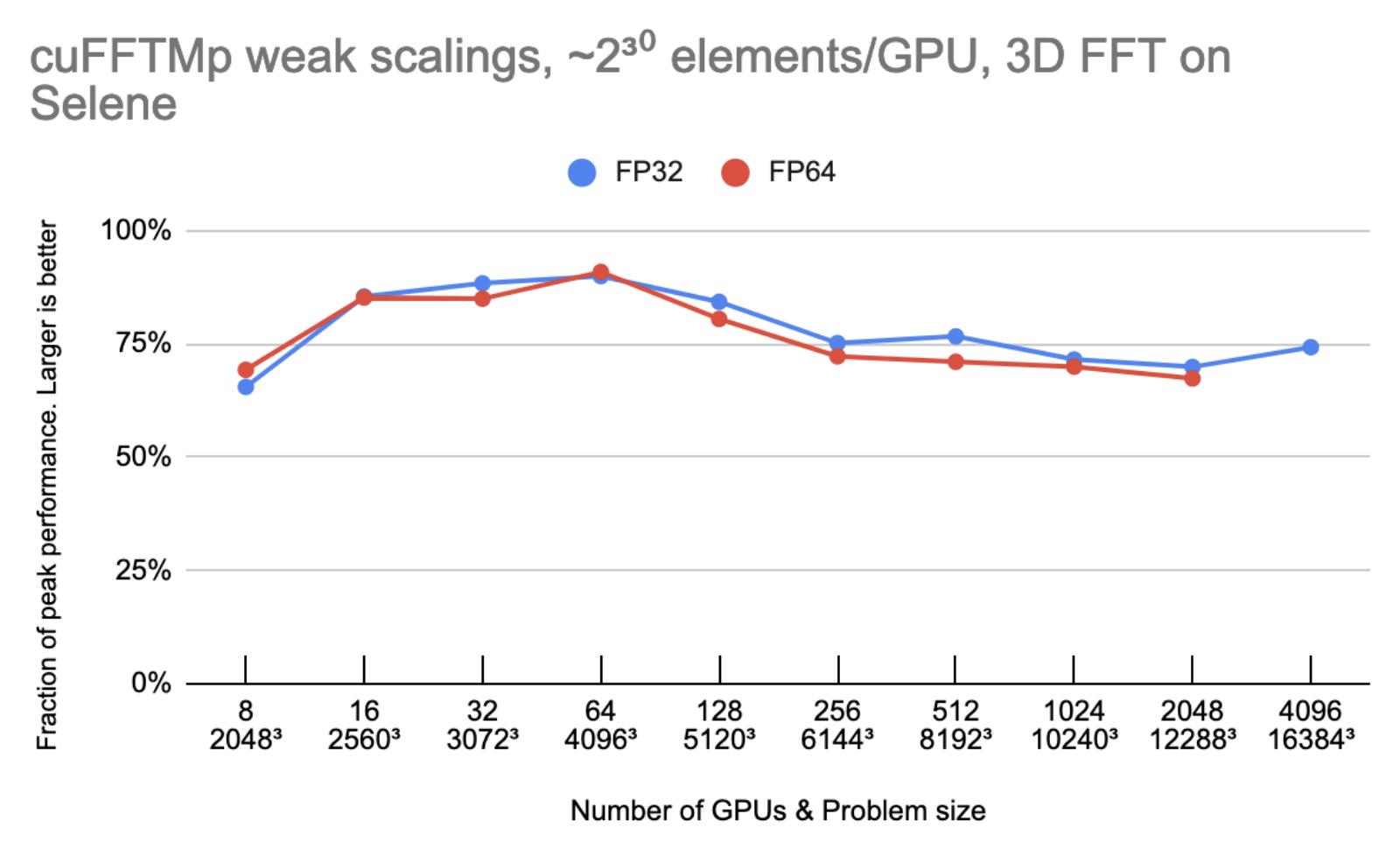
ピーク性能は、双方向グローバル メモリ帯域幅 2000 GB/s/gpu、双方向 NVLink 帯域幅 300GB/s/gpu、Infiniband 帯域幅 25GB/s/gpu を使用した場合です。
1 次元の変換サイズを N 、 G を GPU の個数とします。各 GPU は N3/G 要素 (それぞれ 8 または 16 バイト) を所有しており、このモデルでは、N3/G 要素がグローバル メモリ との間で 6 回読み書きされ、N3/G2 要素が各 GPU から他の GPU に 1 回送られると仮定されます。4096 GPU では、非 InfiniBand 通信に費やす時間は全体の 10% 未満になります。
MPI のポータビリティとマルチアーキテクチャのサポート
前述したように、cuFFTMp の性能は MPI 実装に依存しない。移植性のために、cuFFTMp は MPI を起動し、 CPU 上のデータ分散を管理する必要があります。
現在、cuFFTMp は NVSHMEM と静的にリンクしています。NVSHMEM は小さな MPI 「ブートストラップ プラグイン」 (nvshmem_bootstrap_mpi.so) を使用しており、これは MPI を使用して構築され、実行時に自動的にロードされるようになっています。このブートストラップは、HPC SDK に含まれる OpenMPI バージョンをターゲットとしています。他の MPI 実装に依存するユーザー アプリケーションのために、EA パッケージは、別の MPI をターゲットとするブートストラップを構築するためのヘルパー スクリプトを含んでいます。
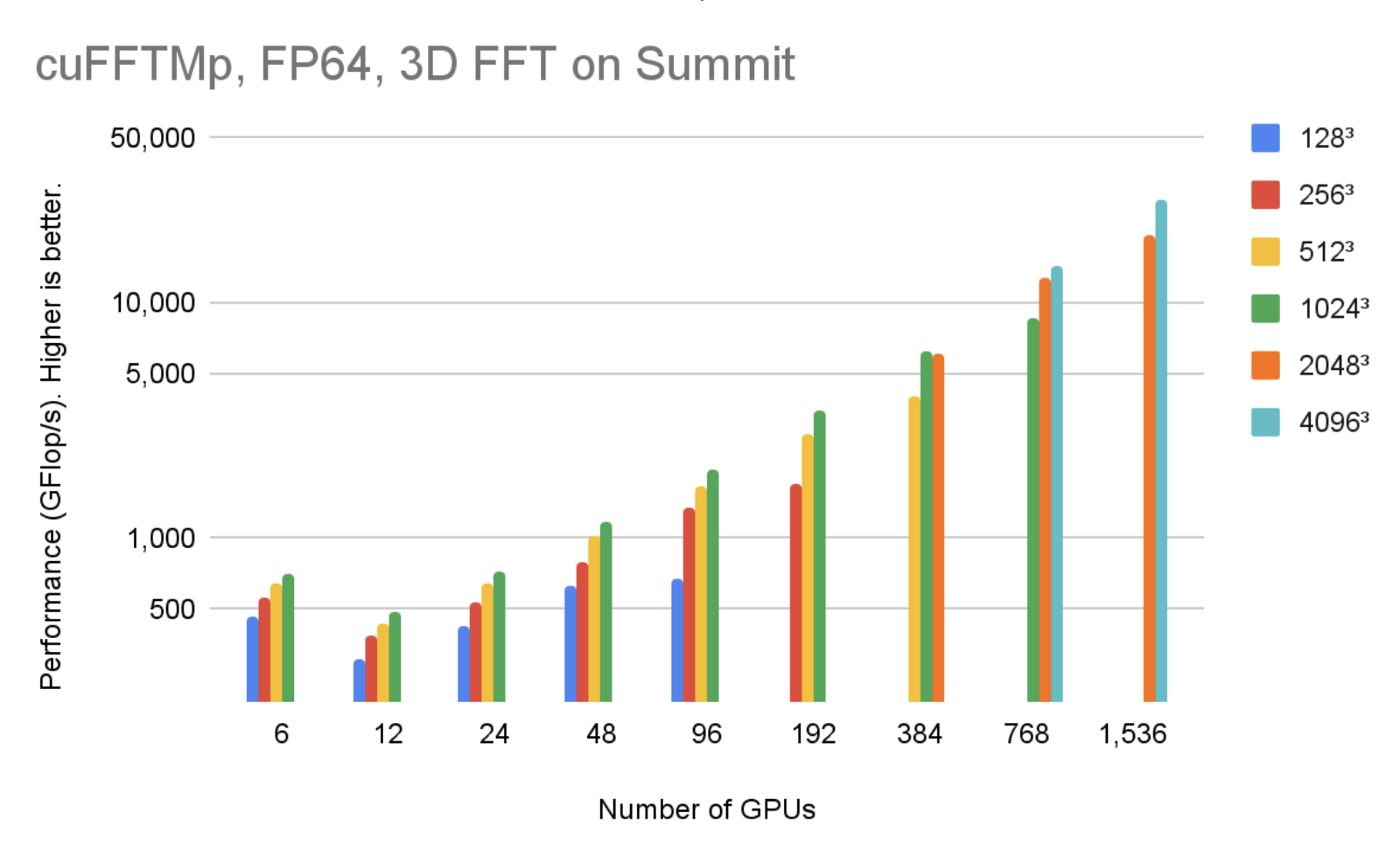
cuFFTMp は、Linux x86_64 と IBM POWER の両方のアーキテクチャをサポートしており、それぞれのアーキテクチャ用の EA パッケージをダウンロードすることができます。 図 4 は、256 ノードで 1536 基の V100 GPU を使用した場合、cuFFTMp は Summit システムのわずか 5% で 40963 個の複素数の変換が 50 TFlop/s 以上に到達できることを示しています
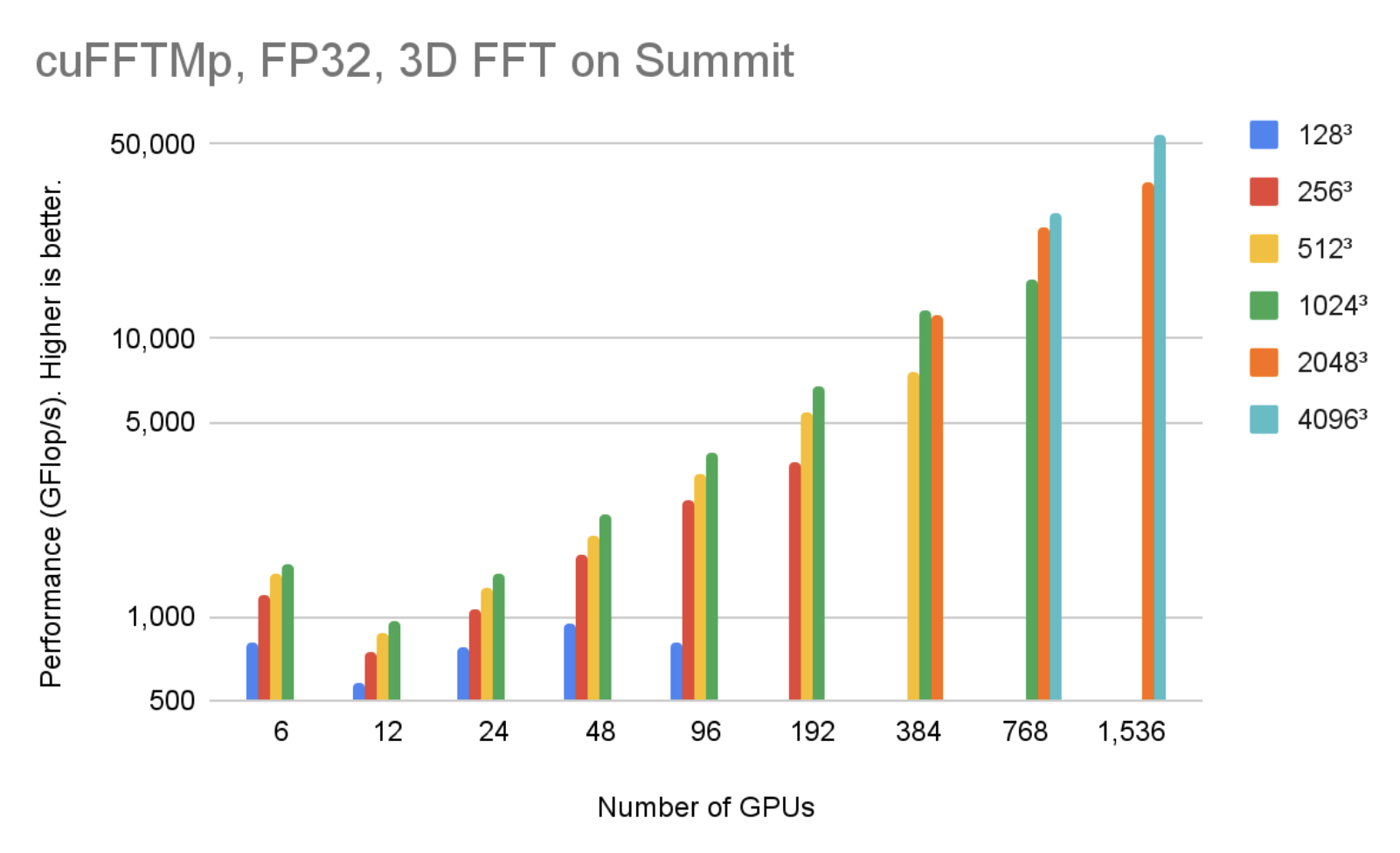
図 5 は、256 ノードで 1536 基の V100 GPU を使用した場合、cuFFTMp は Summit システムのわずか 5% で 40963 個の複素数の変換が 40 TFlop/s 以上に到達できることを示しています。
cuFFTMp への移行が容易
cuFFTMp は、現在のマルチ GPU cuFFT ライブラリの単なる拡張版です。既存のほとんどのマルチ GPU 関数が cuFFTMp に適用されます。分散マルチプロセス ライブラリとして、cuFFTMp は MPI をブートストラップ (「起動」) する必要があり、MPI プロセス間でデータが分散されることを想定しています。次の表は、マルチ GPU cuFFT を使用しているアプリケーションを cuFFTMp に変換するために必要なコードを示しています。
| Multi-GPU, single-process cuFFT | cuFFTMp |
|---|---|
#include <cufftXt.h> |
#include <cufftMp.h> |
| // host buffer h_f size NX*NY*NZ | // host buffer h_f size my_NX*NY*NZ |
| cufftHandle plan_c2c; cufftCreate(&plan_c2c); |
|
|
for (auto i = 0; i < NGPUS; ++i) |
MPI_Comm comm = MPI_COMM_WORLD; cufftMpAttachComm(plan_c2c, CUFFT_COMM_MPI, &comm); |
|
size_t worksize; |
|
| MPI_Finalize(); | |
スラブ分解、ペンシル分解、ブロック分解は、多次元 FFT アルゴリズムにおいて、ノード間での計算の並列化を目的としたデータ分散方法の代表的な名称です。cuFFTMp EA は最適化されたスラブ (1 次元) 分解のみをサポートします。ユーザーが他のデータ分散から cuFFTMp のスラブ データ分散に対応できるよう支援するために、cufftXtSetDistribution や cufftMpReshape などのヘルパー関数を提供します。
cuFFTMp EA パッケージには、C2C、R2C/C2R、ワークスペースを共有する異なるプラン、1 つの分散から他の分散へのデータのシャッフルや GPU 間の再分散など、様々な用途に対応する C++ および Fortran のサンプルが含まれています。cuFFTMp は、EA パッケージに含まれる HPC SDK 21.7+ コンパリラとラッパーを使用して、Fortran アプリケーションを完全にサポートしています。
ユーザー事例: 乱流シミュレーション
cuFFTMp は、物理学で最も古い未解決問題である流体の乱流の難問を研究することを可能にします。
インドのハイデラバードを拠点とする Tata Institute of Fundamental Research (TIFR) の研究チームは、乱流の挙動を理解するために、擬似スペクトル法を適用したナビエ ストークス方程式の直接数値シミュレーション (DNS) の CFD パッケージ Fluid3D を開発しました。Fluid3D を cuFFTMp と CUDA に移植することで、MPI を用いた CPU 版では不可能だった高レイノルズ数の流れを、数千の GPU で数時間以内にシミュレーションすることができるようになったのです。
図 6 において、乱流は異なるスケールの渦で構成されており、大きな運動スケールから小さなスケールにエネルギーが伝達されています。大規模な DNS の実行では、最小の乱流構造の等方的な挙動をシミュレーションし、理解することが重要です。

DNS は乱流の理解を深めるための重要なツールであり、その計算効率と精度の高さから、疑似スペクトル法がよく使われています。
乱流シミュレーションの課題は、高いレイノルズ数 (Re) を達成することである。計算の安定性を保つために、Re はグリッド解像度によって制限されます。つまり、Re2.25 < N3(N は各次元のグリッド点数) です。そのため、Re の高い乱流をシミュレーションに必要な数値解像度は計算コストがかかり、禁止されている場合もあります。
表 1 は、最大 Re に必要なグリッド解像度とシミュレーションに必要なメモリ量を示しています。
| Grid resolution | Simulated Reynolds number | Memory requirement (GB) |
| 10243 | 199.2 | 88 |
| 20483 | 316.2 | 704 |
| 40963 | 501.9 | 5,632 |
| 81923 | 796.8 | 45,056 |
| 122883 | 1044.1 | 152,064 |
| 163843 | 1264.8 | 360,448 |
Fluid3D は、フーリエ空間において 2 次の Exponential Adams-Bashforth タイム ステップ法を使用しています。シミュレーションは通常、数万回のタイムステップにわたって積分され、タイム ステップごとに 9 回の 3D-FFT を計算します。FFT はシミュレーションの実行時間の大部分を占めます。タイム ステップごとの経過時間は、数値実験で解を得るまでの時間が妥当かどうかを測るための重要な指標です。
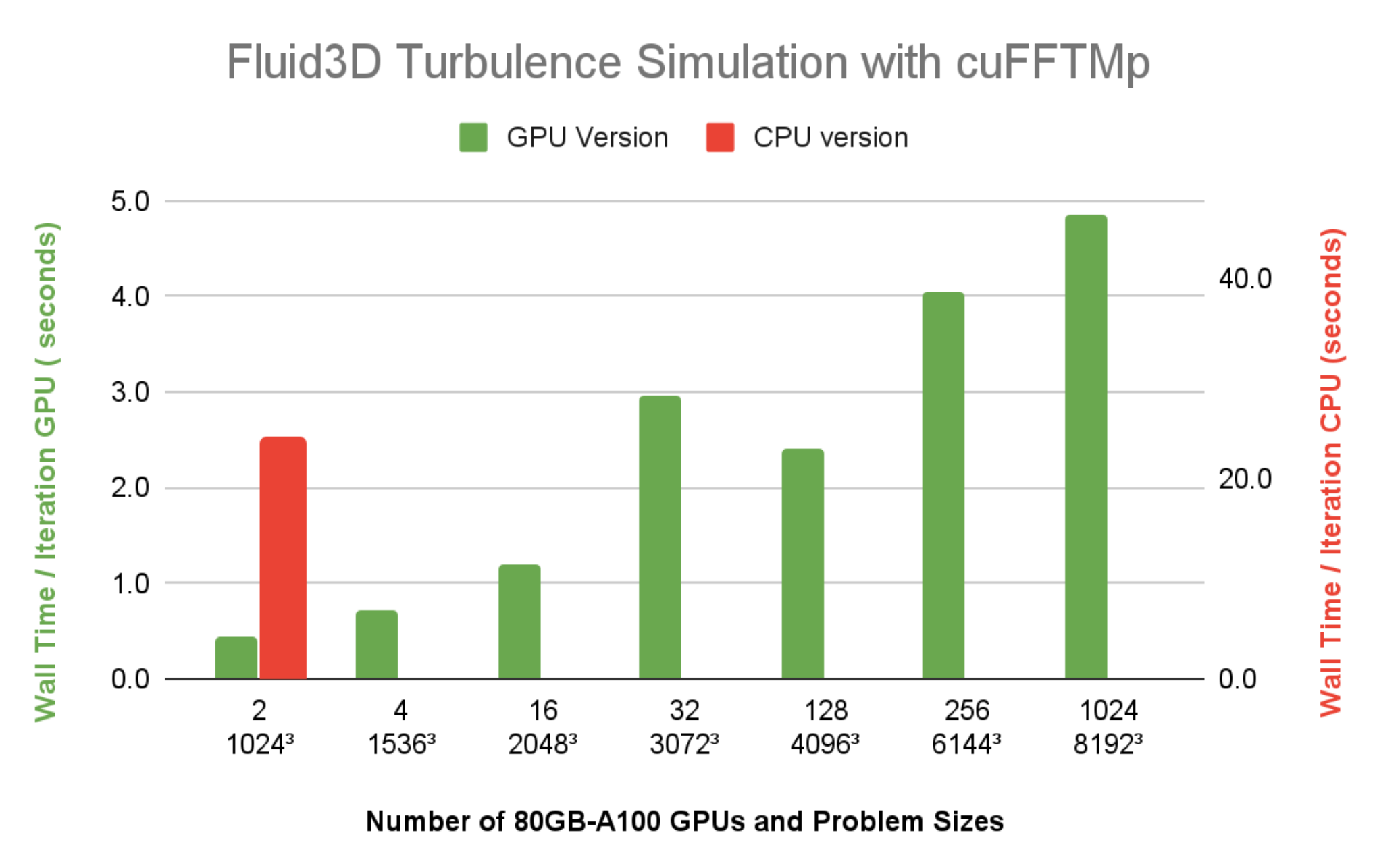
図 7 は、Selene で 1024 基の A100 GPU (128 ノード) を使用した Fluid3D では、解像度 81923 で時間ステップあたりの経過時間が 5 秒以下であることを示しています。64 コアの CPU シングル ノードで 64 MPI ランクを使用した FFTW-MPI を用いた CPU 版では、10243 の解像度で 1 回の反復に 23.9 秒かかります。同じ 10243 の問題サイズを 2 基の A100 GPU で実行したときの経過時間と比較すると、1 台の CPU ノードから 1 基の A100 への Fluid3D の高速化が 20 倍以上であることは明らかです。
cuFFTMp を始める
あなたのアプリケーションを複数ノード実行に移行するために、cuFFTMp を試してみたいと思われましたか? cuFFTMp EA のページにアクセスしてください。cuFFTMp をダウンロードした後、サンプル コードで遊んでみて、それらがマルチ GPU バージョンとどのように似ているか、そしてどのように複数ノードでスケールできるかを確認してみてください。
cuFFTMp では、バッチ型 API の追加や、通信を最小化するためのデータ圧縮など、引き続き改良に取り組んでいます。ご質問や新機能のご要望は、プロダクト マネージャーの Matthew Nicely までご連絡ください。
謝辞
インドのハイデラバードを拠点とする Tata Institute of Fundamental Research の Prasad Perlekar 氏のチームには、多相乱流コード Fluid3D へのアクセスを提供し、cuFFTMp の最初の採用者になったことに特別な感謝を表します。
また、cuFFTMp の開発をサポートしてくれた NVIDIA の NVSHMEM チーム全員にも感謝します。
翻訳に関する免責事項
この記事は、「Multinode Multi-GPU: Using NVIDIA cuFFTMp FFTs at Scale」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。