The world of embedded and edge computing is about to get faster, more efficient, and more versatile with the upcoming CUDA 13.0 release for Jetson Thor SoC powered by NVIDIA Blackwell GPU architecture.
At the heart of this release is a unified CUDA toolkit for Arm platforms, eliminating separate toolkits for server-class and embedded systems. Jetson Thor also gains Unified Virtual Memory (UVM) with full coherence, GPU sharing features like Multi-Process Service (MPS) and green contexts, enhanced developer tools, and new interoperability options. Together, these advancements deliver a more streamlined development workflow and open new possibilities for performance and portability across edge AI applications.
Unifying CUDA for Arm: Build once, deploy anywhere
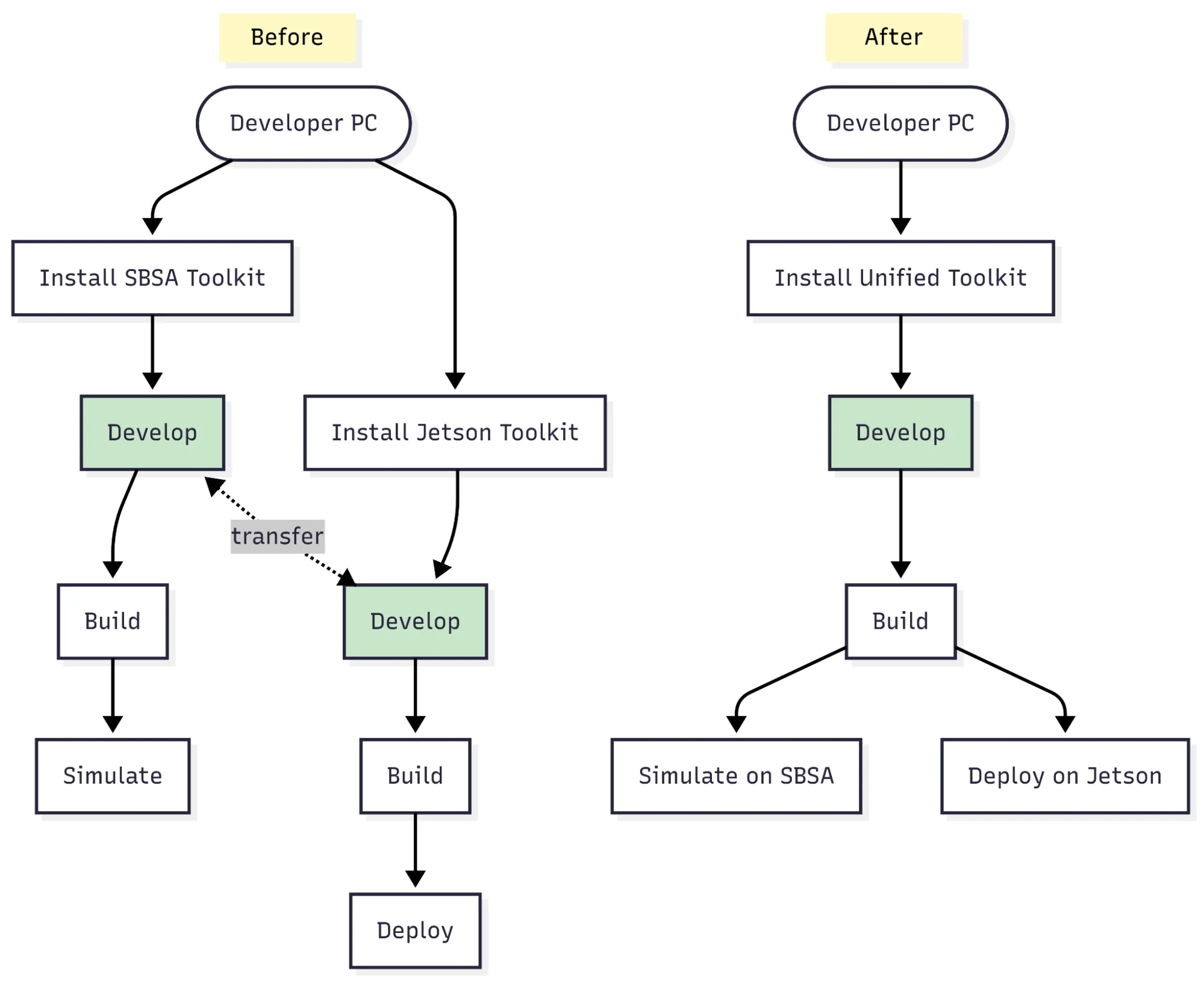
CUDA 13.0 streamlines development for Arm platforms by unifying the CUDA toolkit across server-class and embedded devices. You no longer need to maintain separate installations or toolchains for Server Base System Architecture (SBSA) compliant servers and next-generation embedded systems like Thor. The only exception is Orin (sm_87), which will continue on its current path for now.
This change unlocks a major productivity win. Developers can build a robotics or AI application once, simulate it on high-performance systems like GB200 and DGX Spark, and deploy the exact same binary—without any code changes—directly onto embedded targets like Thor. The compiler and runtime still generate optimized code for the target GPU architecture, but you don’t have to manage two toolchains to get there, as described in Figure 1 below.
The unification also extends to containers, consolidating our image ecosystem so that simulation, testing, and deployment workflows can rely on a shared container lineage. This reduces rebuilds, lowers continuous integration (CI) overhead, and provides a smoother path from code to hardware.
For teams, this means less duplication in CI pipelines, simpler container management, and fewer inconsistencies from juggling different SDKs. For organizations, it provides a single source of truth for builds across simulation and edge platforms, saving engineering time and improving portability across evolving GPU generations and platforms. It also paves the way for concurrent usage of integrated GPU (iGPU) and discrete GPU (dGPU) on Jetson and IGX platforms, delivering a seamless and efficient computing experience.
How Unified Virtual Memory (UVM) and full coherence work in CUDA 13.0
For the first time, NVIDIA Jetson platforms will support Unified Virtual Memory and full coherence. This also enables the device to access pageable host memory via the host’s page tables.
On Jetson Thor platforms, cudaDeviceProp::pageableMemoryAccessUsesHostPageTables is set to 1, indicating that the GPU can access pageable host memory through the host’s page tables. The GPU access to this CPU cached memory is also cached on GPU, with full coherence managed by the hardware interconnect. In practice, system-allocated memory created via mmap() or malloc() can now be used directly on the GPU.
Similarly, allocations created with cudaMallocManaged() will also report cudaDeviceProp::concurrentManagedAccess as 1, meaning that the device can access this memory concurrently with the CPU and that APIs like cudaMemPrefetchAsync() work as expected. In CUDA 13.0, however, cudaMallocManaged() allocations are not GPU-cached. These changes bring UVM functionality on Jetson platforms in line with dGPU systems.
The example below demonstrates mapping a file into memory with mmap() and using that pointer directly in a GPU kernel for a histogram operation. The output histogram buffer is also obtained via mmap(), with no CUDA allocation calls. Both input data and output histogram are cached in the GPU’s L2, and coherence is managed automatically. This eliminates the need for explicit CUDA allocations or cudaMemcpy() calls, while maintaining good performance.
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#define HIST_BINS 64
#define IMAGE_WIDTH 512
#define IMAGE_HEIGHT 512
// Error handling macro
#define CUDA_CHECK(call) \
if ((call) != cudaSuccess) { \
cudaError_t err = cudaGetLastError(); \
printf("CUDA error calling \""#call"\", code is %d\n", err); \
}
__global__ void histogram(
unsigned int elementsPerThread,
unsigned int *histogramBuffer,
unsigned int *inputBuffer)
{
unsigned int offset = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int stride = gridDim.x * blockDim.x;
for (unsigned int i = 0; i < elementsPerThread; i++) {
unsigned int indexToIncrement = inputBuffer[offset + i * stride] % HIST_BINS;
atomicAdd(&histogramBuffer[indexToIncrement], 1);
}
}
int main(int argc, char **argv)
{
size_t alloc_size = IMAGE_HEIGHT * IMAGE_WIDTH * sizeof(int);
size_t hist_size = HIST_BINS * sizeof(int);
unsigned int *histogramBuffer = (unsigned int*)mmap(NULL, hist_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
unsigned int *inputBuffer;
cudaEvent_t start, end;
float timeInMs;
const unsigned int elementsPerThread = 4;
const unsigned int blockSize = 512;
dim3 threads(blockSize);
dim3 grid((IMAGE_WIDTH * IMAGE_HEIGHT) / (blockSize * elementsPerThread));
int fd;
if (setenv("CUDA_MODULE_LOADING", "EAGER", 1) != 0) {
printf("Error: Unable to set environment variable CUDA_MODULE_LOADING.\n");
return -1;
}
fd = open("inputFile.bin", O_RDONLY, 0);
if (fd == -1) {
printf("Error opening input file: inputFile.bin\n");
return -1;
}
inputBuffer = (unsigned int*)mmap(NULL, alloc_size, PROT_READ, MAP_PRIVATE, fd, 0);
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&end));
CUDA_CHECK(cudaEventRecord(start, NULL));
histogram<<<grid, threads>>>(elementsPerThread, histogramBuffer, inputBuffer);
CUDA_CHECK(cudaEventRecord(end, NULL));
CUDA_CHECK(cudaStreamSynchronize(NULL));
CUDA_CHECK(cudaEventElapsedTime(&timeInMs, start, end));
printf("Elapsed Time was %f ms.\n", timeInMs);
munmap(histogramBuffer, hist_size);
munmap(inputBuffer, alloc_size);
close(fd);
return 0;
}
Improving GPU sharing across workloads
CUDA 13.0 continues to build on several GPU sharing features that improve GPU utilization and performance.
Unlocking full GPU potential on Tegra with MPS
As Tegra GPUs evolve with increased compute capacity, individual processes often fail to fully utilize the available GPU resources—especially when workloads are small or bursty such as multiple small generative-AI agents in an application. This may lead to inefficiencies in multi-process systems.
MPS addresses this problem by enabling multiple processes to share the GPU concurrently, avoiding the context-switch overhead and enabling true parallel execution. MPS consolidates lightweight workloads into a single GPU context, improving occupancy, throughput, and scalability. Importantly, MPS requires no application code changes, making it easy to adopt in existing multi-process architectures.
For developers building modern, multi-process applications, MPS is essential to unlock the full performance potential of Tegra GPUs.
Getting started with MPS on Tegra:
There are two binaries associated with MPS, nvidia-cuda-mps-control and nvidia-cuda-mps-server, which are typically stored under /usr/bin.
To start MPS Control Daemon, follow the below steps:
export CUDA_MPS_PIPE_DIRECTORY=<Path to pipe dir>
export CUDA_MPS_LOG_DIRECTORY=<Path to log dir>
nvidia-cuda-mps-control -d # Start the control daemon in background mode
ps –ef | grep mps # To check if MPS control daemon has started
To run an application as an MPS client, set the same pipe and log directory as the daemon, then run the application normally. Logs are stored in $CUDA_MPS_LOG_DIRECTORY/control.log and $CUDA_MPS_LOG_DIRECTORY/server.log. To stop MPS:
echo quit | nvidia-cuda-mps-control
For more details refer to MPS documentation.
Deterministic GPU scheduling with green contexts
Green contexts are lightweight CUDA contexts that pre-assign GPU resources, specifically streaming multiprocessors (SMs) to ensure deterministic execution. By allocating SMs ahead of time, each context can run without being affected by the activity of others, improving predictability in latency-sensitive workloads.
For example, a robotics application on Jetson might run SLAM, object detection, and motion planning simultaneously, each with different real-time constraints. To meet the combined requirements of predictable latency, resource isolation, and efficient GPU utilization, the developer can use a combination of Multi-Instance GPU (MIG, an upcoming feature in future releases), green contexts, and MPS.
MIG partitions the GPU into isolated slices so that time-critical modules like SLAM are unaffected by the resource demands of less time-sensitive tasks. Within each MIG slice, green contexts enable deterministic allocation of SMs to specific CUDA contexts. Multiple processes can each create their own green contexts with non-overlapping SM allocations using CUDA Driver API calls such as cuDevSmResourceSplitByCount and cuGreenCtxCreate.The below code snippet demonstrates how green contexts can be used:
CUdevResource fullSMs;
CUdevResource smGroupA, smGroupB;
CUdevResourceDesc descA, descB;
CUgreenCtx ctxA, ctxB;
CUstream streamA, streamB;
// Get all SMs from device
cuDeviceGetDevResource(device, &fullSMs, CU_DEV_RESOURCE_TYPE_SM);
// Split SMs: assign 1 SM to ctxA, rest to ctxB
unsigned int minCount = 1;
cuDevSmResourceSplitByCount(&smGroupA, &nbGroups, &fullSMs, &smGroupB, 0, minCount);
// Generate descriptors
cuDevResourceGenerateDesc(&descA, &smGroupA, 1);
cuDevResourceGenerateDesc(&descB, &smGroupB, 1);
// Create Green Contexts
cuGreenCtxCreate(&ctxA, descA, device, CU_GREEN_CTX_DEFAULT_STREAM);
cuGreenCtxCreate(&ctxB, descB, device, CU_GREEN_CTX_DEFAULT_STREAM);
// Create streams bound to contexts
cuGreenCtxStreamCreate(&streamA, ctxA, CU_STREAM_NON_BLOCKING, 0);
cuGreenCtxStreamCreate(&streamB, ctxB, CU_STREAM_NON_BLOCKING, 0);
When used with MPS, this setup allows concurrent execution across processes while preserving SM isolation, as long as the CUDA_MPS_ACTIVE_THREAD_PERCENTAGE environment variable is set to 100 or left unset. This configuration maintains consistent performance for each module and is particularly valuable in robotics, where real-time guarantees and efficient multitasking are essential for safe and responsive operation.
Better visibility and control with enhanced developer tools
CUDA 13.0 brings important developer tool enhancements to the Jetson Thor platform, including support for the nvidia-smi utility and the NVIDIA Management Library (NVML). These tools, already familiar to many dGPU developers, now give Jetson developers better insight into GPU usage and greater control over resources.
With nvidia-smi, developers can query GPU details such as device name, model, driver version, and supported CUDA version. It can also report real-time GPU utilization, making it easier to monitor workload behavior during development and debugging.
The NVML library provides programmatic access to similar functionality through C and Python APIs. This allows integration of GPU monitoring and management into custom tools, CI pipelines, or deployment scripts.
While nvidia-smi and NVML are now supported on Jetson Thor, certain features—such as clock, power, and thermal queries; per-process utilization; and SoC memory monitoring—are not yet available. This release is a significant step forward, with broader feature parity expected in future updates.
Simplifying memory sharing with DMABUF
CUDA 13.0 introduces the capability to convert CUDA-allocated buffers into dmabuf file descriptors and vice versa on platforms supporting the Open-Source GPU driver OpenRM. On Linux, dmabuf provides a standardized interface for sharing and synchronizing access to I/O buffers across various kernel mode device drivers. Applications receive these buffers in user space as Linux file descriptors (FD), enabling zero-copy sharing between subsystems.
On Tegra platforms such as Jetson Automotive, EGL or NvSci solutions are typically used for memory sharing. With the introduction of OpenRM and L4T plugins adopting FD-based mechanisms, integration of dmabuf—alongside existing proprietary options—is a significant step toward seamless interoperability between CUDA, third-party devices, and open source software stacks.
Importing a dmabuf into CUDA memory uses the CUDA External Resource Interoperability API with dmabuf added as a new external memory type. Figure 2 gives an overview of the same.

Exporting a CUDA allocation as a dmabuf is done through the Driver API call cuMemGetHandleForAddressRange() on supported OpenRM platforms. Applications can check support using cuDeviceGetAttribute() with the CU_DEVICE_ATTRIBUTE_HOST_ALLOC_DMA_BUF_SUPPORTED attribute, which returns 1 if dmabuf retrieval from CUDA host memory allocations is available. Figure 3 covers how an application can import and export dmabuf fds into CUDA and vice-versa

Porting NUMA-aware apps to Jetson Thor
CUDA 13.0 also introduces Non-Uniform Memory Access (NUMA) support for Tegra. NUMA architectures group CPU cores and memory into nodes, with each node having lower-latency access to its local memory than to other nodes’ memory. This allows NUMA-aware applications to explicitly control memory placement for improved performance.
This feature streamlines development for multi-socket systems while also improving compatibility for single-socket ones. Previously, NUMA-aware applications being ported from dGPU platforms required modifications because cuMemCreate() with CU_MEM_LOCATION_TYPE_HOST_NUMA was not supported on Jetson. While Jetson Thor has only one NUMA node, this update enables applications originally written for dGPU platforms to run on Tegra seamlessly without any code changes.
The usage steps are as per the following code snippet:
CUmemGenericAllocationHandle handle;
CUmemAllocationProp prop;
// size = <required size>; numaId = <desired Numa Id>
memset(&prop, 0, sizeof(CUmemAllocationProp));
prop.location.type = CU_MEM_LOCATION_TYPE_HOST_NUMA;
prop.location.id = numaId;
prop.requestedHandleTypes = CU_MEM_HANDLE_TYPE_NONE;
prop.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop.win32HandleMetaData = NULL;
CHECK_DRV(cuMemCreate(&handle, size, &prop, 0ULL));
What’s coming next
The Multi-Instance GPU/MIG feature will allow partitioning of a large GPU into smaller devices with dedicated resources providing isolation and freedom from interference from one another. This enables workloads with mixed criticality to run in parallel, improving determinism and fault isolation.
In robotics, for instance, certain workloads such as SLAM are considered higher priority than tasks like path planning. By partitioning the (Thor) GPU into two instances—one dedicated to running critical workloads and the other handling lesser critical tasks—we can ensure a great degree of determinism for the higher priority processes. This setup prevents critical workloads from having to compete for GPU resources with other tasks, enabling more predictable real-time performance.
As CUDA 13.0 brings in support for the nvidia-smi utility and the NVIDIA Management Library (NVML), certain features such as clock, power, thermal queries, per-process utilization, and SoC memory monitoring are expected to come in future JetPack releases.
The new features in CUDA 13 for Jetson Thor are a big step toward a unified and simplified developer experience, moving from juggling parallel toolchains to a single CUDA install on Arm. The new driver capabilities and advanced features like UVM, MIG, and MPS position the Jetson platform to deliver strong performance and versatility.
You can start exploring the CUDA 13.0 toolkit today in the JetPack 7.0 release. Join the NVIDIA Developer Forums to share your experiences or get support as you bring these capabilities into your applications.
And stay tuned for more updates as we continue to innovate and push the boundaries of what’s possible in the world of CUDA.
Acknowledgments
Thanks to the following NVIDIA contributors: Saumya Nair, Ashish Srivastava, Debalina Bhattacharjee, Alok Parikh, Quinn Zambeck, Ashutosh Jain, and Raveesh Nagaraja Kote.