
As more and more deep learning models are being deployed into production environments, there is a growing need for a separation between the work on the model itself, and the work of integrating it into a production pipeline. Windows ML caters to this demand by addressing efficient deployment of pretrained deep learning models into Windows applications.
Developing and training the model itself requires being involved with the science as well as know-hows behind it. However, when a pretrained model is being used in a pipeline for inference, it can be treated as simply a series of arbitrary computations on incoming data. These computations are fully described by an ONNX file representing the deep learning model. The ONNX model can be edited and processed to make some simple but often-needed tweaks and optimizations at the deployment stage.
Introducing Windows ML
Windows Machine Learning (Windows ML) allows you to write applications in C#, C++, JavaScript, or Python, and which operate on trained ONNX neural nets. This is an ideal framework if you want to perform inference using previously trained neural nets in your application pipeline without worrying about the internals and complexities of the neural net itself.
Unlike lower-level frameworks like CuDNN and DirectML, you don’t need to define and run each layer individually in Windows ML. Instead, this is all read from a specified .onnx file.
In Windows ML, a neural network can be treated as a black box for the intents of inference. Windows ML provides a convenient API that only requires that you know what inputs the neural net expects.

Anatomy of Windows ML
Windows ML is a high-level layer that uses DirectML for hardware acceleration, as shown in Figure 2.

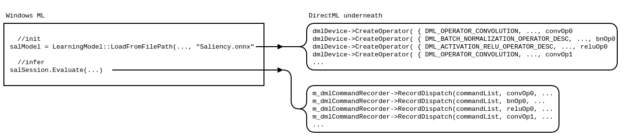
For more information, see the following resources:
- Windows Machine Learning product page
- Tutorial: Create a Windows Machine Learning Desktop application (C++) – Simple “Hello World” like tutorial that demonstrates loading, binding, and evaluating an ONNX model for inference.
- API Reference – All Windows ML APIs are documented here.
- Samples and Tools for Windows ML – Official Windows ML github page.
- WinMLRunner – Extremely useful tool for quickly launching .onnx files on specified hardware devices to measure performance as well as validating results.
- WinMLDashboard – Very useful tool for viewing, editing, converting, and validating .onnx models.
- Custom Operators on GPU – Example on defining and using custom operators on the GPU .
ONNX overview
Introduced by Facebook and Microsoft, ONNX is an open interchange format for ML models that allows you to more easily move between frameworks such as PyTorch, TensorFlow, and Caffe2. An actively evolving ecosystem is built around ONNX.
ONNX data serialization
ONNX is a protocol buffer (protobuf)-based data format. As such, the official protobuf utilities may be used to decode an .onnx file into a readable text format for editing and to encode it back.
Protobuf is an open data-serialization format developed by Google aimed at compactness. It involves specifying a human-readable schema in the form of a .proto or .proto3 file, both of which are referred to as proto files. These files define how the protocol buffer data is structured and therefore how it should be parsed.
To accomplish this, a proto file consists of messages, which specify the structure for segments of data. As such, ONNX has a proto file for both Protobuf version 2 and 3 that describes all messages that can be found in ONNX data. Here are the most up-to-date versions of these files:
- onnx.proto – Protobuf version 2
- onnx.proto3 – Protobuf version 3
For more information, see the following resources:
- Protocol Buffers detail page
- GitHub page
Viewing and editing an ONNX file
There are times when it’s convenient to be able to modify a trained neural network. Here are a few typical scenarios:
- Removing mathematically redundant computations present in the model that were overlooked during the training phase.
- Needing to add some custom operations not present in the ONNX operator set.
- Adding pre-processing or post-processing steps necessary for the model to work as intended.
- Viewing intermediate results for diagnostic purposes by marking them as additional outputs.
- Making the model adhere to requirements for certain specialized hardware optimizations as for for Tensor Cores. For more information, see X.
Windows ML also provides a graphical utility called WinMLDashboard for viewing and editing ONNX models. For more information, see Accelerating WinML and NVIDIA Tensor Cores. The next section describes the most rudimentary way of viewing and editing ONNX models.
Editing ONNX in a human-readable text form using protoc
While protocol buffers are a conveniently compact way of serializing often large neural networks, unlike formats such as XML or JSON, protocol buffers are not human-readable. The simplest and most straightforward way to obtain a human-readable representation of protocol buffer data is to use the protoc tool.
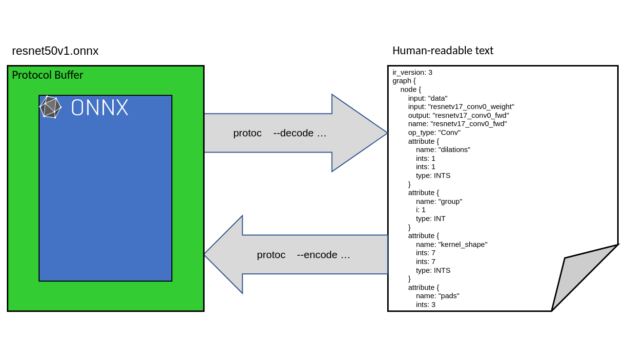
The protoc tool can be used to convert ONNX data into a human-readable text form resembling JSON. This is referred to as decoding and is done using the –decode option, specifying the message that the incoming data should be interpreted as. In this case, the message that envelopes an entire ONNX model is onnx.ModelProto. As shown in the following code example, the incoming data is piped in because protoc reads from stdin and writes into stdout.
protoc --decode=onnx.ModelProto -I path/to/onnx/dot/proto onnx.proto < MyModel.onnx > MyModel.txt
The protoc command decodes an .onnx file MyModel.onnx into a human-readable text form (named MyModel.txt in this example). The -I option is mandatory and must specify an absolute search directory where onnx.proto can be found.
After making any textual edits to the model, protoc can similarly be used to convert the human-readable representation back into protocol buffer form, as shown in the following code example:
protoc --encode=onnx.ModelProto -I path/to/onnx/dot/proto onnx.proto < MyModel.txt > MyModel.onnx
The protoc command that encodes MyModel.txt back into an .onnx file.
Getting protoc
- The latest binaries for protoc can be found at https://github.com/protocolbuffers/protobuf/releases.
- To compile from source, clone the GitHub repo for protoc, and follow the build instructions for Windows or Unix.
Anatomy of an ONNX net
This section runs through some of the key data structures (protocol buffer messages) contained within onnx.ModelProto and how together they form the computational graph of the neural network. The first and structure contained within onnx.ModelProto is onnx.GraphProto.
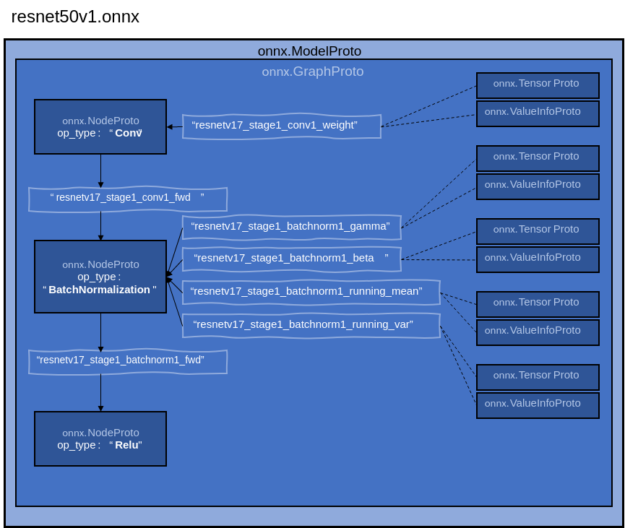
A GraphProto message fully specifies the neural net’s computational graph, which includes all of its computational operators as well as its data. To outline these important ONNX data structures, I use some of the nodes of the resnet50v1.onnx model as an example.
Here are the most important data segments to consider when editing graphs:
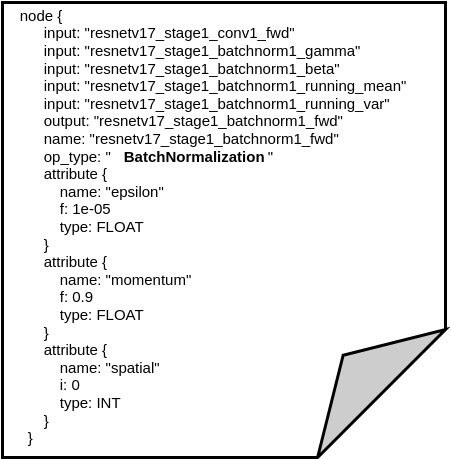
- NodeProto: These represent the computational operators Figure 6 shows the decoded representation of a “Conv” operator, and Figure 7 shows the decoded representation of a “BatchNormalization” operator. The NodeProto data structure must specify at least one input and output. As shown in Figure 6 and Figure 7, the inputs and output fields reference strings. The association between the nodes (and therefore the flow of data) becomes defined when other nodes reference the exact same strings in their input and output.
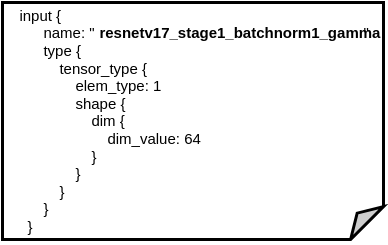
For example, the convolution operation decoded in Figure 6 has an output field of “resnetv17_stage1_conv1_fwd”. This same string is given as an input field in the batch normalization operator shown in Figure 7. As a result, this indicates that the batch normalization operation has to immediately follow the aforementioned convolution operation, as shown in Figure 5. - TensorProto and ValueInfoProto: These data segments contain trained data required by the computation nodes, like weights for a convolution node. TensorProto holds the actual data, while ValueInfoProto defines the type and dimensions of the data. Figure 8 shows the TensorProto storing the values of the weights for a convolution, while Figure 9 is its respective ValueInfoProto. Just as data flow between nodes is defined by matching string references, these data nodes are also referenced by computational nodes with strings.
For example, the convolution operation decoded in Figure 6 has an input field “resnetv17_stage1_conv1_weight”. This same string is referenced under the name field of a TensorProto data segment decoded in Figure 8. As a result, those will be the weights used for that convolution operation.


For more information, see the following resources:
- ONNX home page
- GitHub page
- ONNX Model Zoo: Some popular models converted to ONNX.
ONNX optimization
The previous section described how you would go about manually modifying ONNX model data. When it comes to modifying ONNX data for the purposes of optimizing inference performance, the ONNX ecosystem provides an infrastructure for programmatically processing an ONNX model and modifying it. This is known as the ONNX Optimizer. Individual optimizations are known as optimization passes. For more information about prepackaged optimization passes, see the onnx/onnx/optimizer/passes folder.
Applying ONNX optimizations onto models
The ONNX Optimizer page describes the underlying C++ API that can be used to apply optimizations. However, there are other available ways of applying optimizations without having to write C++ code:
- Using the ONNX Optimizer from Python
- Using onx2tensorrt
Using the ONNX Optimizer from Python
Python bindings exist for applying these optimizations in a straightforward manner. The following code example shows how to apply an optimization that fuses a BatchNormalization operation with a Conv operation (fuse_bn_into_conv):
import onnx
from onnx import optimizer
## Load an ONNX model from a file.
original_model = onnx.load('path/to/the/model.onnx')
## Pick the 'fuse_bn_into_conv' pass.
passes = ['fuse_bn_into_conv']
## Apply the optimization on the original model.
optimized_model = optimizer.optimize(original_model, passes)
## Save the optimized ONNX model.
onnx.save(optimized_model, 'path/to/the/optimized_model.onnx')
A model is loaded from path/to/the/model.onnx, optimized with the fuse_bn_into_convpass, and then saved to path/to/the/optimized_model.onnx.
For more information, see Optimizing an ONNX Model.
Using onnx2tensorrt
The onnx2tensorrt tool is primarily used to convert ONNX data into a TensorRT engine, but it can also be used to only apply ONNX optimization passes. The following code example shows a command line to apply the fuse_bn_into_conv pass to an ONNX file at my_model.onnx, then to save the result to a new ONNX file at my_model_optimized.onnx.
onnx2trt my_model.onnx -O "fulse_bn_into_conv" -m my_model_optimized.onnx
This functionality is currently only available in the master branch of the onnx-tensorrt GitHub repo.
ONNX, Windows ML, and Tensor Cores
Tensor Cores are specialized hardware units on NVIDIA Volta and Turing GPUs that accelerate matrix operations tremendously . This hardware acceleration is accessible under Windows ML on ONNX models.
For more information about how the TensorCore hardware works, see Accelerating WinML and NVIDIA Tensor Cores.
ONNX model requirements for Tensor Core usage
For Windows ML to invoke GPU code that makes use of TensorCores, the ONNX model must meet a number of requirements. Some of them are automatically addressed by Windows ML when the model is loaded, while others need to be explicitly set up ahead of time by the user.
- Implicit requirements (automatically applied)
- NHWC layout: Tensor Cores require data having a NHWC layout for spatial locality between channels. For more information, see Accelerating WinML and NVIDIA Tensor Cores. ONNX does not support NHWC layouts. However, Windows ML reshapes the tensor layouts from NCHW to NHWC when loading the model.
- Channel counts must be multiples of 8: (They will be padded to 8 if necessary).
- Explicit requirements (must be explicitly applied)
- FP16 or INT8 data types: All tensor data must be in either FP16 or INT8 as Tensor Core units only operate on these data types. This includes constant data like convolution weights, as well as inputs and outputs to nodes. INT8 Tensor Cores are only supported by the NVIDIA GPUs with the Turing architecture.
- Packed strides: Tensors must have packed strides (that is, no consecutive elements can be skipped). This means that the stride cannot exceed the filter size.
- GEMM operators must have dimensions that are multiples of 8: GEMMs usually account for a small portion of the entire inference pipeline so this requirement typically won’t have a large performance impact.
If an ONNX model meets the aforementioned explicit requirements, then Windows ML can take on a Tensor Core-optimized driver path when running inference on the model.
The most important of the explicit requirements are FP16/IN8 data types and packed strides, because they apply to convolution operations, which typically make up the majority of operations in a deep neural net.
Converting ONNX models to FP16
ONNX models can be converted to FP16 data types using Python and the onnxmltools module:
"""Parse test command list file.
Usage:
parse_commands.py INPUT
parse_commands.py [--output OUTPUT] INPUT
parse_commands.py (-h | --help)
Options:
-o, --output OUTPUT Desired output file name.
-o, --help Print help
"""
import docopt
import onnxmltools
from onnxmltools.utils.float16_converter import convert_float_to_float16
args = docopt.docopt(__doc__)
input_onnx_model = args.get('INPUT')
output_onnx_model = args.get('--output') if args.get('--output') else input_onnx_model + '.fp16.onnx'
## Load the model
onnx_model = onnxmltools.utils.load_model(input_onnx_model)
## Convert tensor float type from the ONNX model to FP16.
onnx_model = convert_float_to_float16(onnx_model)
## Save as the converted model.
onnxmltools.utils.save_model(onnx_model, output_onnx_model)
This code example loads a specified .onnx file, converts its datatypes to FP16, and then saves it to a new file.
Conclusion
By combining a straightforward, robust, and efficient machine learning inferencing framework, as well as a comprehensive and richly supported neural net model data format like ONNX, Windows ML allows you to integrate state-of-the-art AI models developed by research scientists, directly into real-world applications.
