
Autonomous driving systems use various neural network models that require extremely accurate and efficient computation on GPUs. Zoox is a startup developing robotaxis from the ground up, leveraging the high-performance, energy-efficient compute of NVIDIA DRIVE. Recently, Zoox released a one-hour fully autonomous ride in San Francisco, which showcases their AI stack in detail.

Compared with TensorFlow, NVIDIA TensorRT offers significant speedups (2-6x in fp32, 9-19x in int8 for Zoox networks) enabling asynchronous and concurrent inference capabilities using CUDA streams. Zoox vision/lidar/radar/prediction algorithms rely heavily on deep neural networks, which are all running on NVIDIA GPUs in our vehicles and are mostly deployed with TensorRT.
TensorRT is an SDK for high-performance deep learning inference that delivers low latency and high-throughput for deep learning inference applications.
You can use various conversion pipelines to convert models into TensorRT engines. For example, models trained with Caffe can be converted to TensorRT runtimes easily with the Caffe Parser.
TensorFlow models, however, need to be converted to TensorRT engines using ONNX (Open Neural Network Exchange). The tools introduced in this post are targeted toward TensorFlow, but the principles can be applied to other training frameworks as well.
During the process of deploying and maintaining TensorRT engines for all of these deep neural networks, we found the following pain points:
- ONNX and TensorRT only support a limited set of TensorFlow ops.
- Certain combinations of kernel size and stride may cause side effects in TensorRT.
- Migrating to reduced precision inference or TensorRT upgrades may cause performance regressions.
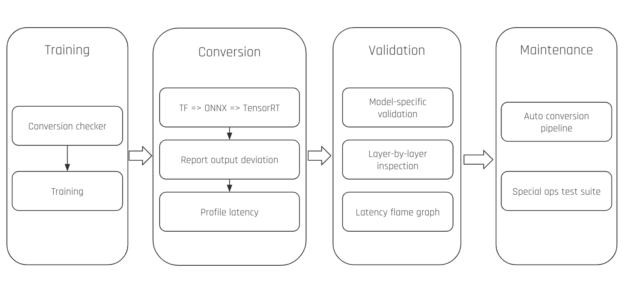
At Zoox, we developed a set of tools to facilitate the deployment, validation, and maintenance of TensorRT engines, shown in Figure 2. In the following sections, we introduce these modules in detail.
TensorRT conversion checker
The goal for the TensorRT Conversion Checker is to help you identify possible conversion failures before training the network. The checker is lightweight and minimal by design (highlighted in the code example later in this post). It triggers a TensorRT conversion process on the constructed network before training. We only start training when the conversion runs without failure.
The following code example shows the TensorRT Conversion Checker. To use the plugin the user only needs to import the package, register input/output nodes during network construction, and then trigger conversion checks before training starts.
import trt_checker
class Lenet5():
def network(self, X):
input = tf.identity(X, name = "input")
# Registers the input in the conversion checker.
trt_checker.register_input(input)
# Network definition.
...
# Output node.
output = tf.identity(logits, name="output")
# Registers the output node in the conversion checker.
trt_checker.register_output(output)
return output
def main():
...
# Checks if the model can be converted to trt.
conversion_result = trt_checker.check_conversion()
# Only train when trt conversion is successful.
if conversion_result:
accuracy = lenet_network.train()
Output deviation inspection
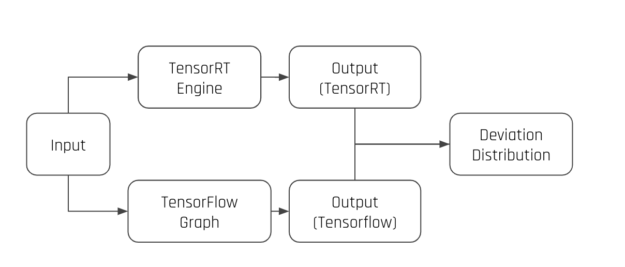
The goal for this plugin is to report potential accuracy regressions of a converted TensorRT engine before running the entire model-specific evaluation. This plugin runs inference on the converted TensorRT engine and the original TensorFlow graph with the exact same input (randomly generated or specified by the user). It then reports the distribution of output deviation, giving the developer an early warning of potential accuracy regression. This module is the building block of the layer-by-layer inspection module.
Layer-by-layer inspection
The following code example shows the layer-by-layer inspection:
def layer_by_layer_analysis(graph, input_layer):
median_error = []
for layer in graph.layers():
errors = convert(graph, input=input_layer, output=layer)
median_error.append(median(errors))
plot(median_error)
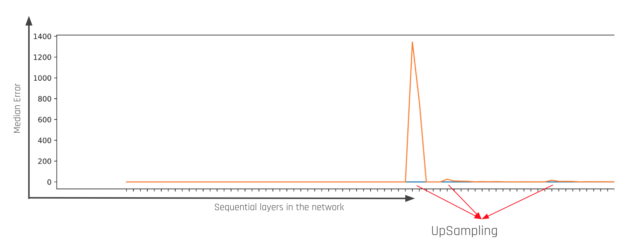
If an accuracy regression is observed, we would like to find out which layer or operation in the TensorRT engine is significantly contributing to the regression. This motivated us to develop the layer-by-layer inspection module. When invoked, the module runs a conversion job for each intermediate op and reports the median/maximum error generated by this specific operation (shown in Figure 4). This module is extremely useful when investigating different behaviors observed in different versions of TensorRT.
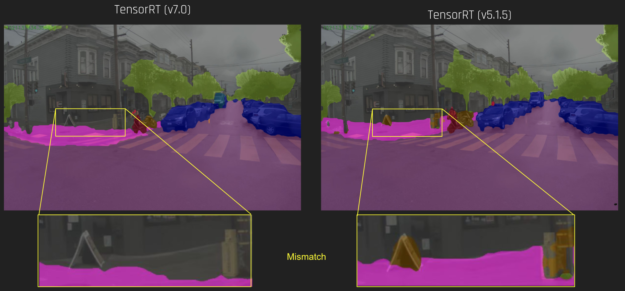
Figure 5 shows one example of such regression, in which we observed slight regression in semantic segmentation output. We ran a layer-by-layer inspection on the TensorRT 5.1 engine and the TensorRT 7.0 engine, then plotted the median error per layer.
Figure 6 shows the generated median error for each layer. We can see that there was potentially a bug in the upsampling layers for this specific network. Based on the information, we were able to reproduce this regression on a smaller network and report this bug to NVIDIA. This bug is now fixed in TensorRT 7.1.
Latency flame graph
To visualize bottlenecks in inference and find out possible operations to optimize, we plot the layer-wise timing information generated by the TensorRT profiler into a flame graph. The timing details are grouped based on name scopes from each layer, shown in Figure 7. This allows us to see which part of the network is taking longer than expected.

Automated conversion pipeline
At Zoox, we maintain an automated conversion pipeline that keeps track of the conversion options used for each model. When triggered, the auto-conversion pipeline converts all recorded models to TensorRT engines and upload them to the cloud for deployment. It also runs validation jobs for the newly converted TensorRT engines to validate the accuracy. This pipeline helps us to upgrade all existing models to newer versions of TensorRT with just one command.
Incompatible graph test suite
Zoox maintains a TensorFlow-to-TensorRT conversion test suite. It tests conversion failure cases from TensorFlow graphs to TensorRT engines, along with the reported NVIDIA bug identifications.
Each test builds a TensorFlow graph, converts it to TensorRT, and compares the output deviation with the TensorFlow graph. Using this test suite, we can not only demonstrate to Zoox engineers which graph structures or operations may not work with TensorRT, but we can also detect which regressions have been fixed when upgrading to newer versions of TensorRT.
Summary
In this post, we introduced several features in the Zoox TensorRT conversion pipeline. TensorRT Conversion Checker is involved in the early stages of neural network training to ensure that incompatible ops are discovered before you waste time and resources on full-scale training. You can invoke inference accuracy validation at each layer to identify operations not friendly to reduced precision computation. Detailed profiling reveals unnecessary computations that are not optimized inside TensorRT, but which can be optimized by simple code changes during graph construction.
The auto-conversion pipeline helps you validate each TensorRT upgrade or model re-conversion. With this pipeline, we successfully provide TensorRT conversion support for neural networks performing various streamlined perception tasks on the Zoox autonomous driving platform.
