Data scientists and researchers work toward solving the grand challenges of humanity with AI projects such as developing autonomous cars or nuclear fusion energy research. They depend on powerful, high-performance AI platforms as essential tools to conduct their work. Even enterprise-grade AI implementation efforts—adding intelligent video analytics to existing video camera streams or image classification picture searches or adding conversational AI to call center support—require incredibly accurate AI models across diverse network types that can deliver meaningful results, at high throughput and low latency.
That’s the key. To be useful and productive, the model must not only have high throughput, but it also must make correct predictions at that high throughput. In everyday terms, it’s just not useful to advertise a sports car that has a top speed over 200 mph, if it can only maintain that speed for a few seconds and can never complete a journey from point A to point B.
If you’re driving from Los Angeles to New York, you want a vehicle that can speedily and reliably make the trip from start to finish. Having a fast car that sputters out in the desert or mountains shortly after setting out isn’t the type of platform to depend on. Even if you’re an avid skier who’s brought your skis with you, getting stranded in the wilderness in the Rockies at the height of winter is going to get challenging quickly.
The next time you hear a slick promotion for a sports car that has a scorching top speed, hold onto your wallet for a second and ask yourself, “Will this get me to my destination or leave me stranded in the middle of nowhere?”
The same basic principle applies in training neural networks in AI. As obvious as this may sound, the AI industry continues to pay a lot of attention to just throughput. Every new announcement on the market starts off with a speed claim on ResNet-50, a well-established image classification network. But it’s one thing to briefly run that network at high throughout (images per second in the ResNet-50 case) for a momentary period of time, but is the network converging and making accurate predictions so it can be deployed as an actual product or service? That is, does the network reach its destination?
Here’s what convergence means in a neural network. In implementing AI, you have two essential steps: training and inference. Training a network is the first step, where you teach a network how to make predictions based on your dataset. Inference is the process of deploying a trained network where you use it in production to make predictions. To train a neural network, you feed in vast amounts of data and it starts to look for patterns, like how the human brain operates.
For example, you have an image classification network being trained to classify houses. There can be hundreds or thousands of layers with billions of parameters, each comprising a series of equations that build up to the statistical probability or likelihood of a specific type of prediction. You feed in a dataset of house images and the network scans the images for patterns. This starts to update weights in probability equations that drive predictions.
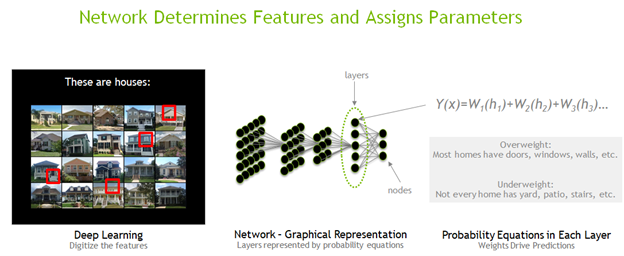
The human brain looks at key features to classify a house, such as a door, windows, roof, and so on. There isn’t a single specification of what a house is, as there are millions of permutations. However, you can make predictions as to what is statistically likely to be a house. By testing a series of values for the weights, the network can start to make predictions of all the key features that define a house. It can then evaluate the accuracy of its predictions by comparing it to the known correct answer or ground truth.
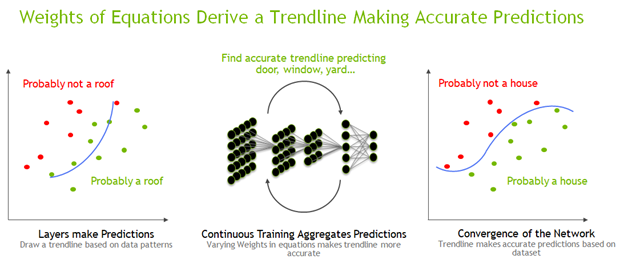
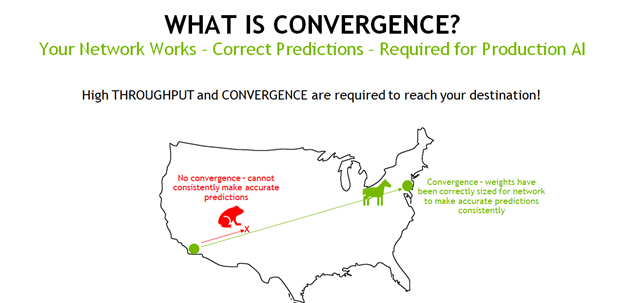
The network can adjust the weights so that it makes more accurate predictions of the key features that classify a house and eventually make accurate predictions of almost every image of a house, At this point, the network is said to have reached convergence, which occurs when the network is consistently making accurate predictions because the weights that define the equations in all of its layers have been correctly selected. This repetitive training process is effective, but also compute-intensive. While throughput is paramount, so is accuracy and convergence.
Meeting an accuracy metric like “79% Top1”, for example, states that the network’s highest probability prediction is 79% accurate. In the case of image classification, “79% Top1” would be considered industry state-of-the-art. Across different types of networks from speech to translation, there are different metrics for evaluating accuracy.
| Task | Models | Industry Accuracy Metrics |
| Computer Vision | ResNet-50 V1.5 | 76% Top1 |
| Computer Vision | ResNext101 | 79.2% Top1 |
| Computer Vision | SE-ResNext101 | 79.9% Top1 |
| Computer Vision | SSD | 0.26 mAP |
| Computer Vision | Mask R-CNN | 0.37 AP BBox, 0.34 AP Segm |
| Natural Language Processing | BERT Large Fine-Tuning | 90.0 F1 |
| Natural Language Processing | TransformerXL Large | 18.1 perplexity |
| Natural Language Processing | GNMT | 23.80 BLEU |
| Recommender Systems | DLRM | 0.8 AUC |
| Recommender Systems | NCF | 95% hit rate at 10 |
| Recommender Systems | Wide and Deep | 0.67 mAP@12 |
| Text To Speech | FastPitch | 0.205 loss (750 epochs) |
| Text To Speech | TacoTron2 | 0.47 loss |
| Text To Speech | WaveGlow | -5.76 loss |
Clearly, it’s not just the throughput that matters, it’s the time-to-solution (TTS). This is also known as time-to-convergence, or time-to-train, where the network has achieved a specified level of accuracy. In fact, in knowing the TTS and required accuracy level, you not only have confidence that the network is making accurate predictions, but you can inherently also calculate the throughput, as a shorter TTS can only be achieved by high throughput. However, high throughput on its own is an insufficient metric unless you know that the network has converged to a required accuracy level.
For this reason, MLPerf, the AI industry’s first benchmark, uses TTS to a specified accuracy level to decide the fastest AI solution. An apples-to-apples comparison with everyone running the same test to the same set of rules guarantees a fair race to decide the winner. It’s the same reason that Usain Bolt’s record-setting Olympic race times are easily comparable across centuries of races. We all know what the race conditions are, rightly earning him the monikers of “Greatest sprinter of all time” or the “Fastest man on earth.” No one can modify the race conditions to generate favorable conditions, such as artificially shortening the length of a meter or sloping the track downhill to goose extra performance. That just wouldn’t stand publicly as a 100-meter track record.
This might seem perfectly obvious. However, in neural networks, taking shortcuts to speed things up is routine, like preprocessing your data or starting with favorable hyperparameters. You could even (gasp!) not train to convergence! While these steps dramatically accelerate your peak throughput, that metric by itself is incomplete. That’s why a benchmark like MLPerf is so useful. It tests everyone to the exact same set of rules that are fairly drawn up for all parties.
However, due to the sheer engineering effort involved, MLPerf publishes results just a few times a year and tests a limited number of networks. What happens if you’re an organization that maintains monthly builds of networks and makes them freely accessible to your users? How do you show that these networks are making accurate predictions so that they can be used by enterprise customers who want to go to production out-of-the-box with AI?
In 2017, NVIDIA launched NGC, a hub for GPU-optimized software for deep learning, machine learning, and high performance computing. This software accelerates deployment to development workflows so that data scientists, developers, and researchers can focus on building solutions, gathering insights, and delivering business value.
In addition to containerized, optimized software for these different domains, NGC also makes available pretrained networks that can be integrated into production workflows with industry-standard accurate results. You can also fine-tune these pretrained networks with your own custom data sets and deploy a converged network for your application more quickly.
In other words, we’ve already guaranteed that the drive to New York will be a pleasant one and that you will reach your destination on time!
For more than a year, we’ve been publishing the throughput data of our NGC models on our NVIDIA Data Center Product Performance page to show full transparency on our performance across a wide variety of GPUs, frameworks, and batch sizes. These networks can all converge to their specified accuracy levels.
Now, in the spirit of adopting MLPerf style accountability and providing information that more closely tracks how you train AI models in the real world, we’re revamping the performance page to include TTS on all these networks, as well as publicly disclosing the state-of-the-art accuracy of the predictions that the network makes.
With NGC, you can instantly evaluate models for performance in your production environments and know that the model will get you to your destination. After all, it’s extraordinarily expensive and time-consuming to rescue yourself when stranded in the mountains. By knowing the prediction accuracy of the model, you know upfront if this model works for your specific application, assuring reliable enterprise deployment. The entire end-to-end stack of NVIDIA hardware, software, and libraries ensures a seamless experience.
Going forward, we’ll continue to publish the time and accuracy convergence numbers to give you full confidence in rapid, high-throughput adoption. We hope that this post has given you an effective overview of why it’s the best benchmark to use when evaluating performance.
