
AI, machine learning (ML), and deep learning (DL) are effective tools for solving diverse computing problems such as product recommendations, customer interactions, financial risk assessment, manufacturing defect detection, and more. Using an AI model in production, called inference serving, is the most complex part of incorporating AI in applications. Triton Inference Server takes care of all the plumbing for serving inference so that you can focus on application development.
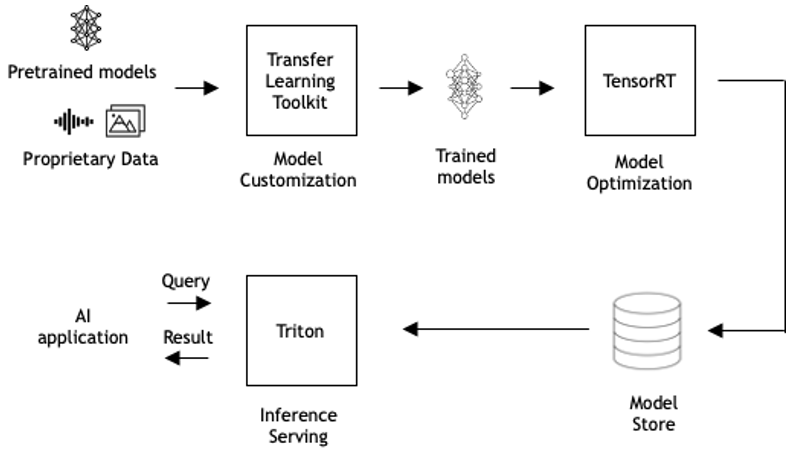
Efficient inference serving
Every AI-powered application needs inference serving. However, inference serving is complex, for the following reasons:
- A single application can use multiple models from different AI frameworks with various pre– and post-processing steps. Inference serving must support multiple framework backends.
- There are several types of queries:
- Real-time (online) —Inference serving is latency-constrained.
- Batch (offline) —Inference serving provides high throughput.
- Streaming—Inference serving must preserve the query sequence.
- Models can run on GPU and CPU infrastructure on the public cloud, in datacenters, or at the enterprise edge.
- Models must be optimally scaled to meet application demand.
- Model status must be monitored and issues resolved to prevent downtime.
- Multiple KPIs must be optimized: hardware utilization, model rollout time, and TCO.
There are inference serving solutions that handle a few of these complexities but lack many optimizations for efficient inference serving.
Triton Inference Server
Triton is an efficient inference serving software enabling you to focus on application development. It is open-source software that serves inferences using all major framework backends: TensorFlow, PyTorch, TensorRT, ONNX Runtime, and even custom backends in C++ and Python. It optimizes serving across three dimensions.
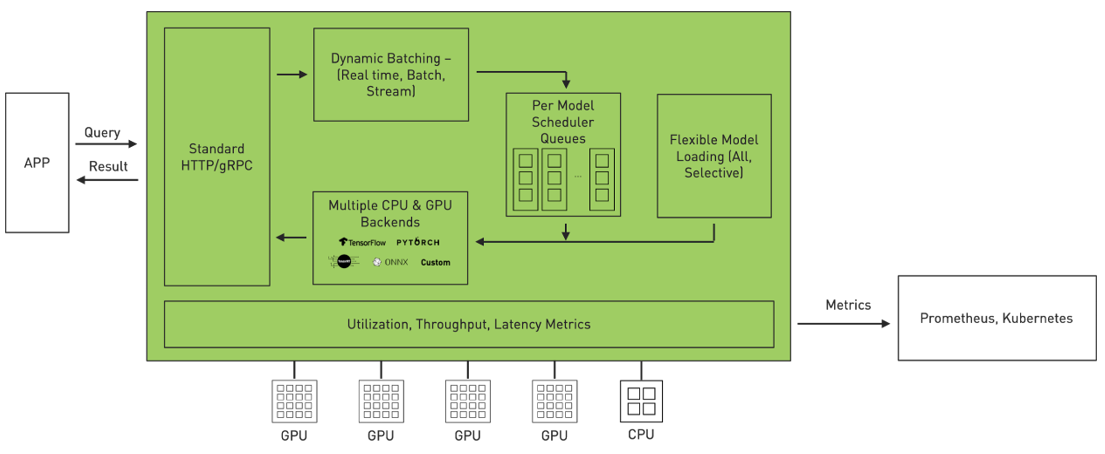
- Utilization: Triton can be used to deploy models either on GPU or CPU. It maximizes GPU/CPU utilization with features such as dynamic batching and concurrent model execution.
- Scalability: Triton provides datacenter– and cloud-scale through microservices based inference. It can be deployed as a container microservice to serve pre– or post-processing and DL models on GPU and CPU. Each Triton instance can be scaled independently in a Kubernetes-like environment for optimal performance. A single Helm command from NGC deploys Triton in Kubernetes.
- Application experience: Triton has standard HTTP/REST and gRPC endpoints that applications use to communicate. Triton supports real-time, batch, and streaming inference queries for the best application experience. Models can be updated in Triton in live production without disruption to the application. Triton delivers high throughput inference while meeting tight latency budgets using dynamic batching and concurrent model execution.
Announcing Triton 2.3
We are pleased to announce Triton Inference Server version 2.3. This version introduces significant features that further simplify scaled inference serving:
- Kubernetes serverless inferencing
- Support for the latest versions of framework backends: TensorRT 7.1, TensorFlow 2.2, PyTorch 1.6, and ONNX Runtime 1.4
- Python custom backend
- Support for NVIDIA A100 and MIG
- Decoupled inference serving
- Triton Model Analyzer
- Microsoft Azure Machine Learning integration
- NVIDIA DeepStream integration
Kubernetes serverless inferencing
Triton is the first inference serving software to adopt KFServing’s new community standard gRPC and HTTP/REST data plane v2 protocols. KFServing is a standards-based serverless inferencing on Kubernetes.
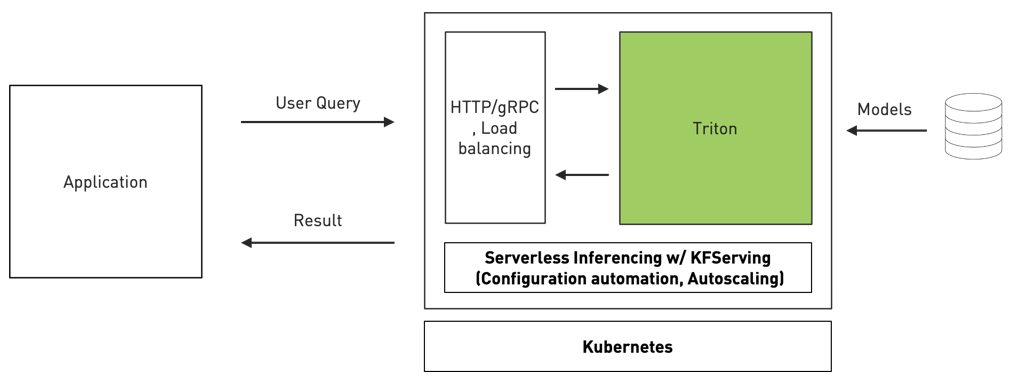
It simplifies inference serving deployment in Kubernetes through configuration automation and automatic scaling. It handles load spikes transparently so your service would continue to work smoothly even if the number of requests rises significantly. With this new integration, organizations can now easily deploy high performance inference with Triton in Kubernetes environment.
The following code example shows the deployment of the BERT model using Triton. InferenceService is the custom resource introduced by KFServing where you specify the predictor of type triton. As you can see, just ~30 lines implement scalable inference serving in Kubernetes with KFServing and Triton.
apiVersion: "serving.kubeflow.org/v1alpha2"
kind: "InferenceService"
metadata:
name: "bert-large"
spec:
default:
transformer:
custom:
container:
name: kfserving-container
image: gcr.io/kubeflow-ci/kfserving/bert-transformer:latest
resources:
limits:
cpu: "1"
memory: 1Gi
command:
- "python"
- "-m"
- "bert_transformer"
env:
- name: STORAGE_URI
value: "gs://kfserving-samples/models/triton/bert-transformer"
predictor:
triton:
resources:
limits:
cpu: "1"
memory: 16Gi
nvidia.com/gpu: 1
storageUri: "gs://nv-enterprise/trtis_models/"
With KFServing, preprocessing steps like tokenization and postprocessing can be easily included in the deployment through the definition of a transformer. For more information, see the samples/triton/bert example in GitHub.
Python custom backend
In addition to the existing custom backend environment that supports C and C++ applications, a new Python custom backend has been added to Triton. The Python custom backend is powerful as it allows any arbitrary Python code to be executed inside Triton. Common scenarios for using Python code are in pre– and post-processing the neural network to modify tensor structures, such as rotating or cropping images or feature engineering for a recommender workload. Using the existing model ensembling functionality in Triton allows Python code to be executed before and after neural network inference happens in a DL framework backend.
Support for A100 and MIG
NVIDIA A100 brings breakthrough technologies like third-generation Tensor Cores that accelerate every precision for diverse workloads and Multi-Instance GPU (MIG) that partitions single A100 into up to seven GPU instances to optimize GPU utilization and expand access to more users. Inference with Triton on A100 provides higher performance than V100 (Figure 4). The A100 with Triton delivered nearly a 3x speedup on both throughput and latency using a ResNet50 PyTorch model when compared to V100.

You can also use Triton to serve inferences on individual MIG instances with performance and fault isolation.
Decoupled inference serving
This feature is demanded by emerging use cases like speech recognition and speech synthesis where inference results are not dependent on the completion of full inference requests. Models operating in this decoupled mode can decide, on a request-by-request basis, how many responses to produce for the request. For example, in speech recognition, a client may send audio samples to the inference server at varying rates, with varying numbers of samples at any given time. The decoupled mode enables Triton to engage the model when sufficient but not all inputs are received. In the 2.3 release, this functionality is available only for the C/C++ custom backends.
The Riva Conversational AI platform makes use of the decoupled inference serving feature and will be available for public beta by the end of the year. For more information and early access, sign up at NVIDIA Riva.
Triton Model Analyzer
A key feature in version 2.3 is the Triton Model Analyzer, which is used to characterize model performance and memory footprint for efficient serving. It consists of two tools:
- The Triton
perf_clienttool, which is being renamed toperf_analyzer. It helps characterize the throughput and latency of a model for various batch sizes and request concurrency values. - A new memory analyzer functionality, which helps characterize the memory footprint of a model for various batch sizes and request concurrency values.
Here is an example of output for perf_analyzer that helps determine the optimal batch and concurrency values for a given model showing batch size, percentiles for latency, throughput, and concurrency details.
$ perf_client -m resnet50_netdef --concurrency-range 1:4*** Measurement Settings *** Batch size: 1 Measurement window: 5000 msec Latency limit: 0 msec Concurrency limit: 4 concurrent requests Stabilizing using average latency Request concurrency: 1 Client: Request count: 804 Throughput: 160.8 infer/sec Avg latency: 6207 usec (standard deviation 267 usec) p50 latency: 6212 usec ... Request concurrency: 4 Client: Request count: 1042 Throughput: 208.4 infer/sec Avg latency: 19185 usec (standard deviation 105 usec) p50 latency: 19168 usec p90 latency: 19218 usec p95 latency: 19265 usec p99 latency: 19583 usec Avg HTTP time: 19156 usec (send/recv 79 usec + response wait 19077 usec) Server: Request count: 1250 Avg request latency: 18099 usec (overhead 9 usec + queue 13314 usec + compute 4776 usec) Inferences/Second vs. Client Average Batch Latency Concurrency: 1, 160.8 infer/sec, latency 6207 usec Concurrency: 2, 209.2 infer/sec, latency 9548 usec Concurrency: 3, 207.8 infer/sec, latency 14423 usec Concurrency: 4, 208.4 infer/sec, latency 19185 usec
The Triton memory analyzer provides many benefits such as optimal allocation of models to a GPU to avoid out of memory errors in production, optimizing the model’s memory use for better performance and determining the right GPU for the model. Figure 6 shows an example output from the memory analyzer that helps determine the number of model instances to be loaded into a GPU memory for inference serving.

Microsoft Azure Machine Learning integration
Using Triton on Microsoft Azure Machine Learning, customers can get high-performance inferencing and more cost effective utilization of GPUs during inference. Triton provides benefits like dynamic batching, concurrent execution on GPU, support for CPU, and multiple framework backends including ONNX Runtime. Azure Machine Learning provides a central registry and MLOps capabilities to automatically provide version tracking and audit trail for the deployed models and other ML assets. Read documentation to learn how to use Triton in Azure Machine Learning.
NVIDIA DeepStream integration
NVIDIA DeepStream SDK is a complete streaming analytics toolkit for AI-based multi-sensor processing, video, and image understanding. With native integration to Triton in DeepStream 5.0, you can deploy models from multiple DL frameworks beyond TensorRT for rapid prototyping, for both NVIDIA T4 and Jetson platforms. For more information, see Building Intelligent Video Analytics Apps Using NVIDIA DeepStream 5.0.
Customer use cases
Here’s how customers are using Triton.
Microsoft
Microsoft is using AI to provide grammar suggestions to Microsoft Word online users. They wanted to deploy compute-complex DL-based models cost effectively with state-of-the-art accuracy and speed. The real-time grammar suggestions required tight latency budgets of 200ms or less.
They are using real-time inference serving on Azure Machine Learning and NVIDIA V100 GPUs with Triton and ONNX Runtime. Triton can provide high throughput (450 inferences/s on one V100) and low latency (200 ms) using dynamic batching, concurrent execution, and ONNX Runtime integration. They can achieve one-third lower costs on Azure Machine Learning Compute V100 GPUs. For more information, see NVIDIA AI on Microsoft Azure Machine Learning to Power Grammar Suggestions in Microsoft Editor for Word.
American Express
American Express services have 144M cards that create over 8B annual transactions. They wanted to build and deploy a real-time (sub-2ms) fraud detection system, using both ML and DL to increase accuracy.
They used Triton to deploy a TensorRT-optimized gated recurrent unit model to analyze tens of millions of daily transactions using T4-equipped servers. This enhanced, real-time fraud detection system operates within 2 ms latency budget, a 50x improvement compared to CPUs that could not meet the latency requirement.
Naver
Naver is the top search engine and internet services company in South Korea. They use DL for real-time image classification, search recommendations, and other uses. The use of multiple frameworks (TensorFlow, PyTorch, Caffe, and TensorRT) slowed down the timely introduction of new AI models. Plus, it was costly to manage.
They adopted Triton because it supported multiple frameworks and real, batch, and streaming inferencing on both GPU and CPU. Triton offered them a single inference platform that allowed for faster rollout of new DL models from multiple frameworks and lowered Naver’s operational costs.
SPIL
SPIL is the largest outsourced semiconductor assembly and test company in the world. They inspect around 30,000 wafer images per day for defects in a single production line as part of their wafer bumping service. Their current auto-optical inspection (AOI) platform produced 70% false positives, which then required a second screening.
SPIL used DL models (U-Net, DenseNet, and Autoencoder) for second-level screening using NVIDIA T4 GPUs, TensorRT, and Triton. They can now detect 100% of defects with less than 10% false positives for all assembly line wafers. Triton’s dynamic model loading and unloading helped them scale to 100 different models without changes to their serving infrastructure.
Tracxpoint
Tracxpoint is a retail technology company that created a DL–powered physical shopping cart called AiC. With AiC, shoppers place products in their carts and then receive personalized product offers in realtime, navigate the supermarket with ease, and pay digitally.
Tracxpoint used TensorFlow– and TensorRT-optimized models on NVIDIA T4 Tensor Core GPUs using Triton for real-time inferencing. AiC can recognize 100,000 products in under a second. Models are retrained daily and Tracxpoint can update them seamlessly in Triton with no disruptions to users.
Conclusion
Triton simplifies the deployment of AI and DL models at scale in production. It supports all major frameworks, runs multiple models concurrently to increase throughput and utilization, supports both GPUs and CPUs, and integrates with Kubernetes for a scaled inference.
Download Triton Inference Server version 2.3 from NGC and access the source code from the triton-inference-server/server GitHub repo.
