
Instance segmentation is a core visual recognition problem for detecting and segmenting objects. In the past several years, this area has been one of the holy grails in the computer vision community with wide applications ranging from autonomous vehicles (AV), robotics, video analysis, smart home, digital human, and healthcare.
Annotation, the process of classifying every object in an image or video, is a challenging component of instance segmentation. Training a conventional instance segmentation method, such as Mask R-CNN, requires class labels, bounding boxes, and segmentation masks of objects simultaneously.
However, obtaining segmentation masks is costly and time-consuming. The COCO dataset for example required about 70,000 hours of time to annotate 200k images, with 55,000 hours spent gathering object masks.
Introducing Discobox
Working to expedite the annotation process, NVIDIA researchers developed the DiscoBox framework. The solution uses a weakly supervised learning algorithm that can output high-quality instance segmentation without mask annotations during training.
The framework generates instance segmentation directly from bounding box supervisions, rather than using mask annotations to directly supervise the task. Bounding boxes were introduced as a fundamental form of annotation for training modern object detectors and use labeled rectangles to tightly enclose objects. Each rectangle encodes the localization, size, and category information of an object.
Bounding box annotation is the sweet spot of industrial computer vision applications. It contains rich localization information and is very easy to draw, making it more affordable and scalable when annotating large amounts of data. However, by itself, it does not provide pixel-level information, and cannot be directly used for training instance segmentation.
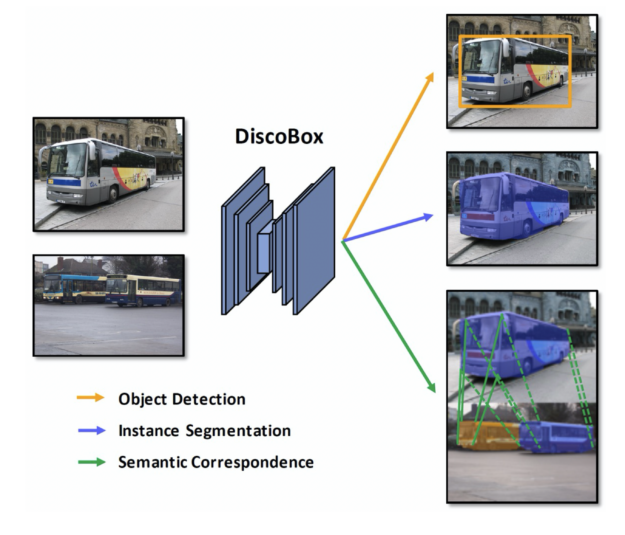
Innovative features of DiscoBox
DiscoBox is the first weakly supervised instance segmentation algorithm that gives comparable performance to fully-supervised methods while reducing labeling time and costs. The method, for example, is faster and more accurate than the legendary Mask R-CNN, without requiring mask annotations during training. This raises the question of whether mask annotations are truly needed in future instance segmentation applications as less labeling is required.
DiscoBox is also the first weakly supervised algorithm that unifies both instance segmentation and multi-object semantic correspondence under box supervision. These two tasks are useful in many computer vision applications such as 3D reconstruction and are shown to mutually help each other. For example, predicted object masks from instance segmentation can help semantic correspondence to focus on foreground object pixels, whereas semantic correspondence can refine mask prediction. DiscoBox unifies both tasks under box supervision, making their model training easy and scalable.
At the center of DiscoBox is a teacher-student design. The design features the use of self-consistency as a self-supervision to replace the mask supervision missing in DiscoBox training. The design is effective in promoting high-quality mask prediction, even though mask annotations are absent in training.
DiscoBox applications
There are many applications of DiscoBox beyond its use as an auto-labeling toolkit for AI applications at NVIDIA. By automating costly mask annotations the tool could help product teams in intelligent video analytics or AV save a significant amount on annotation budgets.




Another potential application is 3D reconstruction, an area where both object masks and semantic correspondence are important information for a reconstruction task. DiscoBox is capable of giving these two outputs with only bounding box supervision, helping generate large-scale 3D reconstruction in an open-world scenario. This could benefit many applications for building virtual worlds, such as content creation, virtual reality, and digital humans.
DiscoBox was recently highlighted at NVIDIA GTC 2022. Watch the on-demand presentation of DiscoBox: Pushing the Boundaries of Weakly Supervised Instance Segmentation with Box Supervision.
For more information on the model or to use the code, visit DiscoBox on GitHub.
To learn more about the research NVIDIA is conducting, visit NVIDIA Research.
