
The exponential growth in AI model complexity has driven parameter counts from millions to trillions, requiring unprecedented computational resources that require clusters of GPUs to accommodate. The adoption of mixture-of-experts (MoE) architectures and AI reasoning with test-time scaling increases compute demands even more. To efficiently deploy inference, AI systems have evolved toward large-scale parallelization strategies, including tensor, pipeline, and expert parallelism. This is driving the need for larger domains of GPUs connected by a memory-semantic scale-up compute fabric to operate as a unified pool of compute and memory.
This blog post details how the performance and breadth of NVIDIA NVLink scale-up fabric technologies are made available through NVIDIA NVLink Fusion to address the growing demands of complex AI models.
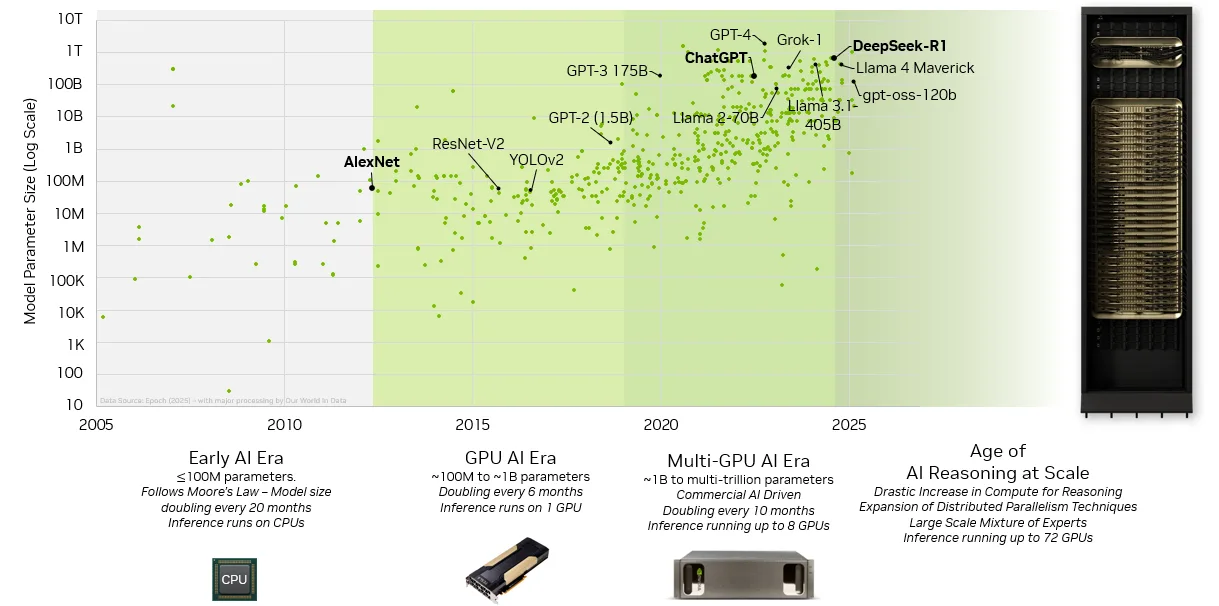
How NVLink continues to evolve and meet scale-up demands
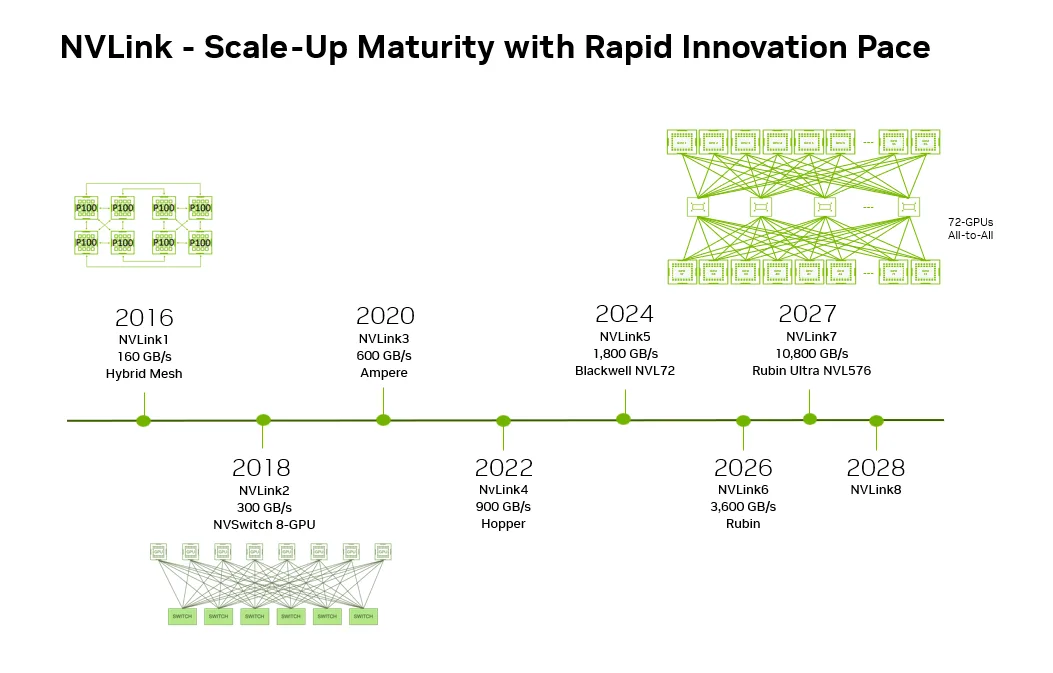
NVIDIA first introduced NVLink in 2016 to overcome the limitations of PCIe in high-performance computing and AI workloads. It enabled faster GPU-to-GPU communication and created a unified memory space.
In 2018, the introduction of NVIDIA NVLink Switch technology achieved 300 GB/s all-to-all bandwidth between every GPU in an 8-GPU topology, paving the way for scale-up compute fabrics in the multi-GPU compute era. NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) technology was introduced with the third-generation NVLink Switch for performance benefits such as optimized bandwidth reductions and collective operation latency reduction.
With the fifth-generation NVLink released in 2024, NVLink Switch enhancements support 72 GPUs all-to-all communication at 1,800 GB/s, giving 130 TB/s of aggregate bandwidth—800x more than the first generation.
Despite being production-deployed at scale for nearly a decade, NVIDIA continues to push the limits, delivering the next three NVLink generations at an annual pace. This approach delivers continuous technological advancement that matches the exponential growth in AI model complexity and computational requirements.
NVLink performance relies on hardware and communication libraries—notably the NVIDIA Collective Communication Library (NCCL).
NCCL was developed as an open-source library to accelerate communication between GPUs in single-node and multi-node topologies, achieving near-theoretical bandwidth for GPU-to-GPU communication. It seamlessly supports scale-up and scale-out and includes automatic topology awareness and optimizations. NCCL is integrated into every major deep learning framework, benefiting from 10 years of development and 10 years of production deployment.

Maximizing AI factory revenue
NVIDIA hardware and library experience with NVLink, along with a large domain size, meet today’s AI reasoning compute needs. The 72-GPU rack architecture plays a crucial role in this alignment by enabling optimal inference performance across use cases. When evaluating LLM inference performance, the frontier Pareto curves show the balance between throughput per watt and latency.
The goal for AI factory productivity and revenue is to maximize the area under the curve. Many variables affect the curve dynamics, including raw compute, memory capacity, and throughput, along with scale-up technology that enables optimizations across tensor, pipeline, expert parallel, etc., with high-speed communication.
When examining performance across various scale-up configurations, we see notable differences. These changes occur even when NVLink speed remains constant.
- For NVLink in a 4-GPU mesh (with no switch), the curve suffers from splitting bandwidth to each GPU.
- An 8-GPU topology with NVLink Switch significantly boosts performance as it achieves full bandwidth for every GPU-to-GPU connection.
- Increasing to a 72-GPU domain with NVLink Switch maximizes revenue and performance.

NVLink Fusion gives custom access to NVLink scale-up technology
NVIDIA introduced NVLink Fusion to give hyperscalers access to all of the NVLink production-proven scale-up technologies. It enables custom silicon (CPUs and XPUs) to integrate with NVIDIA NVLink scale-up fabric technology and rack-scale architecture for semi-custom AI infrastructure deployment.
The NVLink scale-up fabric technology access includes the NVLink SERDES, NVLink chiplets, NVLink Switches, and all aspects of the rack-scale architecture. The high-density rack-scale architecture includes the NLVink spine, copper cable system, mechanical innovations, advanced power and liquid cooling technology, and an ecosystem with supply chain readiness.
NVLink Fusion offers versatile solutions for custom CPU, custom XPU, or combined custom CPU and custom XPU configurations. Being available as a modular Open Compute Project (OCP) MGX rack solution enables NVLink Fusion integration with any NIC, DPU, or scale-out switch, giving customers the flexibility to build what they need.

For custom XPU configurations, the interface to NVLink utilizes integration of Universal Chiplet Interconnect Express (UCIe) IP and interface. NVIDIA provides the bridge chiplet for UCIe to NVLink for the highest performance and ease of integration while still giving adopters with the same level of access to NVLink capabilities as NVIDIA. UCIe is an open standard, and by using this interface for NVLink integration, it gives customers the flexibility to choose other options for their XPU integration needs across their current or future platforms.

Figure 6. NVLink Fusion with XPU access to NVLink through the NVLink chiplet
For custom CPU configurations, integration of NVIDIA NVLink-C2C IP for connectivity to NVIDIA GPUs is recommended for optimal performance. Systems with custom CPUs and NVIDIA GPUs gain access to hundreds of NVIDIA CUDA-X libraries as part of the CUDA platform, for advanced performance in accelerated computing.

Growing customer adoption
Amazon Web Services (AWS) is adopting NVIDIA NVLink Fusion to power the semi-custom rack infrastructure with the new Trainium4 chip. Using NVIDIA NVLink Fusion, AWS will combine NVIDIA NVLink scale-up performance and the NVIDIA MGX rack architecture to accelerate deployment for the Trainium4 AI chips, Graviton CPUs, Elastic Fabric Adapters (EFAs), and the Nitro System virtualization infrastructure for next-generation, cloud-scale AI capabilities. AWS has already deployed MGX racks at scale with NVIDIA GPUs. Adopting NVLink Fusion allows AWS to leverage the MGX rack and supply chain, simplifying deployment and system management across its platforms.
In addition, the RIKEN FugakuNEXT supercomputing system plans to feature FUJITSU-MONAKA-X CPUs, which can be paired with NVIDIA technologies using NVIDIA NVLink Fusion, enabling high-bandwidth connections between Fujitsu CPUs and NVIDIA architecture. By combining MONAKA-X and the latest NVIDIA GPUs, FugakuNEXT will help shape the future of scientific discovery through innovation in HPC, AI, quantum, and their combinations.
Supported by an extensive, production-ready partner ecosystem
NVLink Fusion includes a robust silicon ecosystem, including partners for custom silicon, CPUs, and IP technology. This ensures broad support and rapid design-in capabilities with continuous technological advancement.
For the rack offering, adopters benefit from our system partner network and data center infrastructure component providers that are already building the NVIDIA GB200 NVL72 and NVIDIA GB300 NVL72 systems in production volume. The combined ecosystem and supply chain enable adopters to accelerate their time to market, reducing bring-up time for the only rack-scale, scale-up fabric in production.
Greater performance for AI reasoning
NVLink represents a significant leap forward in addressing compute demand in the age of AI reasoning. By leveraging decade-long expertise in NVLink scale-up technologies, coupled with the open, production-deployed standards of the OCP MGX rack architecture and ecosystem, NVLink Fusion empowers hyperscalers with unparalleled performance and comprehensive customization options.
Learn more about NVLink Fusion.
Updated on Dec. 8 with customer adoption information.








