
When writing compute shaders, it’s often necessary to communicate values between threads. This is typically done through shared memory. Kepler GPUs introduced shuffle intrinsics, which enable threads of a warp to directly read each other’s registers, avoiding memory access and synchronization. Shared memory is relatively fast but instructions that operate without using memory of any kind are significantly faster still.
This post discusses those warp shuffle and warp vote intrinsics and how you can take advantage of them in your DirectX, OpenGL, and Vulkan applications, in addition to CUDA. We also provide the ShuffleIntrinsicsVk sample, which illustrates basic use cases of those intrinsics.
The intrinsics can be further divided into the following categories:
- Warp vote: Cross-warp predicates
- ballot, all, any
- Warp shuffle: Cross-warp data exchange
- Indexed (any-to-any) shuffle, shuffle up, shuffle down, butterfly (xor) shuffle
- Fragment quadswizzle: Fragment quad data exchange and arithmetic
- quadshuffle
The vote and shuffle intrinsics (but not fragment quadswizzle) are available not just in compute shaders but to all graphics shaders!
How does shuffle help?
There are advantages to using warp shuffle and warp vote intrinsics instead of shared memory:
- Shuffle/vote replaces a multi-instruction shared memory sequence with a single instruction that avoids using memory, increasing effective bandwidth and decreasing latency.
- Shuffle/vote does not use any shared memory that is not available in graphics shaders
- Synchronization is within a warp and is implicit in the instruction, so there is no need to synchronize the whole thread block with
GroupMemoryBarrierWithGroupSyncorgroupMemoryBarrier.
Where can shuffle help?
“During the port of the EGO engine to the next-gen console, we discovered that warp/wave-level operations enabled substantial optimizations to our light culling system. We were excited to learn that NVIDIA offered production-quality, ready-to-use HLSL extensions to access the same functionality on GeForce GPUs. We were able to exploit the same warp vote and lane access functionality as we had done on the console, yielding wins of up to 1ms at 1080p on an NVIDIA GTX 980. We continue to find new optimizations to exploit these intrinsics,” said Tom Hammersley, principal graphics programmer at Codemasters Birmingham.
There are quite a few algorithms (or building blocks) that use shared memory and could benefit from using shuffle intrinsics:
- Reductions
- Computing min/max/sum across a range of data, like render targets for bloom, depth-of-field, or motion blur.
- Partial reductions can be done per warp using shuffle and then combined with the results from the other warps. This still might involve shared or global memory but at a reduced rate.
- List building
- Light culling, for example, might involve shared memory atomics. Their usage can be reduced when computing slots per warp or skipped completely if all threads in a warp vote that they don’t need to add any light to the list.
- Sorting
- Shuffle can also be used to implement a faster bitonic sort, especially for data that fits within a warp.
As always, it’s advisable to profile and measure as you are optimizing your shaders!
Threads, warps, and streaming multiprocessors
NVIDIA GPUS, such as those from the NVIDIA Pascal generation, are composed of different configurations of graphics processing clusters (GPCs), streaming multiprocessors (SMs), and memory controllers. Threads from compute and graphics shaders are organized in groups called warps that execute in lock-step.
On current hardware, a warp has a width of 32 threads. In case of future changes, it’s a good idea to use the following intrinsics to determine the number of threads within a warp as well as the thread index (or lane) within the current warp:
HLSL: NV_WARP_SIZE NvGetLaneId() GLSL: gl_WarpSizeNV [or gl_SubGroupSizeARB] gl_ThreadInWarpNV [or gl_SubGroupInvocationARB]
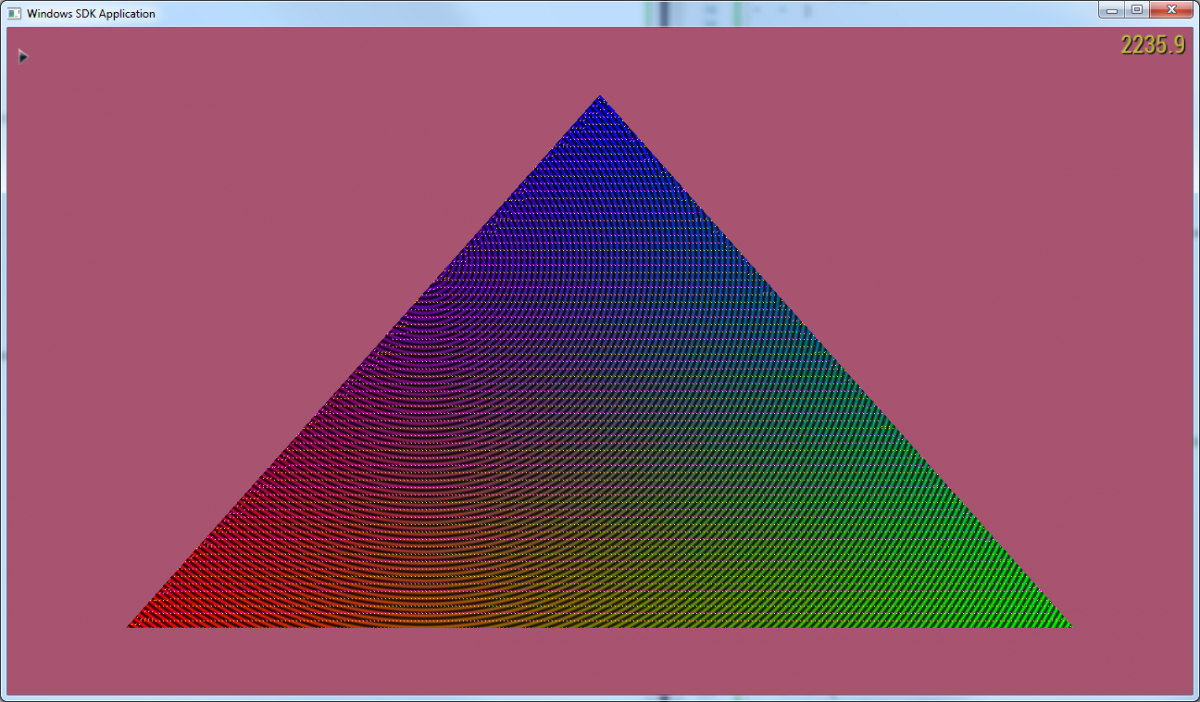
The ShuffleIntrinsicsVk sample contains a rendermode that maps the lane ID within a warp to a color (Figure 1).
Warp vote: Cross-warp predicates
The warp vote functions enable a shader to evaluate a predicate for each thread and then broadcast the result to all threads within a warp. The all/any variants combine the results of all threads into a single Boolean value that then gets broadcast to all threads within a thread group. The ballot variant provides the individual predicates of each thread to all threads within the warp in the form of a 32-bit mask, where each bit corresponds to the predicate of the respective thread.
HLSL: uint NvAny(int predicate) uint NvAll(int predicate) uint NvBallot(int predicate) GLSL: bool anyThreadNV(bool predicate) [or bool anyInvocationARB(bool predicate)] bool allThreadsNV(bool predicate) [or bool allInvocationsARB(bool predicate)] bool allThreadsEqualNV(bool predicate) [or bool allInvocationsEqualARB(bool predicate)] uint ballotThreadNV(bool predicate) [or uint64_t ballotARB(bool predicate)]
The ShuffleIntrinsicsVk code sample demonstrates how the ballot intrinsic can be used to color code the first and last thread of a warp:
uint activeThreads = ballotThreadNV(true);
uint firstLaneId = findLSB(activeThreads);
uint lastLaneId = findMSB(activeThreads);
if (firstLaneId == gl_ThreadInWarpNV)
{
oFrag = vec4(1, 1, 0, 0);
}
else if (lastLaneId == gl_ThreadInWarpNV)
{
oFrag = vec4(1, 0, 1, 0);
}
else
{
oFrag = color;
}
Warp shuffle: Cross-warp data exchange
Warp shuffle functions enable active threads within a thread group to exchange data using four different modes (indexed, up, down, xor).
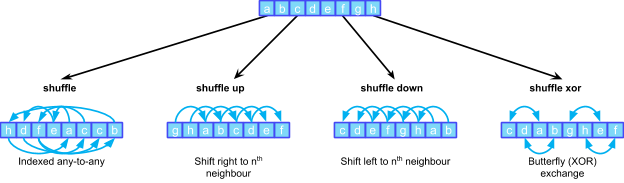
They all load a value from the current thread, which can be different per thread. They return a value read from another thread, whose index can be specified using various methods, depending on the flavor of the shuffle.
The subsequent discussion of the individual shuffle functions makes use of the following terms:
dataparameter: The 32-bit value to be exchanged across the warp.threadIdValidargument (GLSL only): (Optional) It holds the value of the predicate that specifies if the source thread from which the current thread reads the data is in range.widthargument: Used for segmenting the thread group in multiple segments, which can be used for example to exchange data between four groups of eight lanes in a SIMD manner.- If
widthis less than the warp width, then each subsection of the warp behaves as a separate entity with a starting logical lane ID of 0. A thread may only exchange data with others in its own subsection.widthmust have a value that is a power of 2 so that the warp can be subdivided equally. Results are undefined ifwidthis not a power of 2, or is a number greater than the warp width.
- If
When a shuffle function attempts to access a value from an out-of-range thread, it returns the value of the current thread and sets threadIdValid to false (if provided as an argument). This is typically not a problem, for example when computing a min/max reduction across the warp but it might need special consideration when computing a sum across the warp.
Indexed any-to-any shuffle
This intrinsic enables a thread to read the value from any thread within the thread group.
HLSL: int NvShfl(int data, uint index, int width = NV_WARP_SIZE) GLSL: int shuffleNV(int data, uint index, uint width, [out bool threadIdValid])
Here, index directly specifies the source thread or lane and must be in the range of 0 to 31.
Shuffle up and shuffle down
The shuffle up and shuffle down intrinsics differ from the indexed shuffle, as they determine the index of the source thread by adding or subtracting an offset to the current thread index within the warp.
HLSL: int NvShflUp(int data, uint delta, int width = NV_WARP_SIZE) int NvShflDown(int data, uint delta, int width = NV_WARP_SIZE) GLSL: int shuffleUpNV(int data, uint delta, uint width, [out bool threadIdValid]) int shuffleDownNV(int data, uint delta, uint width, [out bool threadIdValid])
Here, the delta argument is the offset that gets subtracted (shuffleUp) or added (shuffleDown) to the current thread ID to get the source thread ID. This has the effect of shifting the segment up or down by delta threads.
Butterfly or XOR shuffle
The butterfly (or XOR) shuffle does a bitwise xor between the lane mask and the current thread ID to get the source thread ID.
HLSL: int NvShflXor(int data, uint laneMask, int width = NV_WARP_SIZE) GLSL: int shuffleXorNV(int data, uint laneMask, uint width, [out bool threadIdValid])
The laneMask parameter specifies a value that gets “xor”-ed with the current thread ID to get the source thread ID.
This can be used to perform a reduction across the warp as shown in the ShuffleIntrinsicsVK sample which computes the maximum of a color value across the warp.
vec4 warpMax = color; warpMax = max(warpMax, shuffleXorNV(warpMax, 16,32)); warpMax = max(warpMax, shuffleXorNV(warpMax, 8, 32)); warpMax = max(warpMax, shuffleXorNV(warpMax, 4, 32)); warpMax = max(warpMax, shuffleXorNV(warpMax, 2, 32)); warpMax = max(warpMax, shuffleXorNV(warpMax, 1, 32)); oFrag = warpMax;
Fragment QuadSwizzle: Data exchange and arithmetic
There are a few commands in the HLSL and GLSL standard libraries that rely on data from neighboring fragments, for example, computing screen space derivatives or computing the LOD for texture lookups. For those, the hardware groups fragment shader invocations into 2×2 grids (quads) and then use specialized variants of cross-warp data exchange as building blocks for the standard library functions.
The quadSwizzle intrinsics (currently GLSL only) expose those building blocks to application developers. Six of those functions enable fragments within a quad to exchange data.
Replicate the value of a single thread across the quad:
float quadSwizzle0NV(float swizzledValue, [float unswizzledValue]) float quadSwizzle1NV(float swizzledValue, [float unswizzledValue]) float quadSwizzle2NV(float swizzledValue, [float unswizzledValue]) float quadSwizzle3NV(float swizzledValue, [float unswizzledValue])
Data exchange across threads corresponding to pixel neighbors:
float quadSwizzleXNV(float swizzledValue, [float unswizzledValue]) float quadSwizzleYNV(float swizzledValue, [float unswizzledValue])
All those functions read a floating point operand swizzledValue, which can come from any fragment in the quad. Another optional floating point operand unswizzledValue, which comes from the current fragment, can be added to swizzledValue. The only difference between all these quadSwizzle functions is the location where they get the swizzledValue operand within the 2×2 pixel quad.
If any thread in a 2×2 pixel quad is inactive (that is, gl_HelperThreadNV or gl_HelperInvocation are false), then the quad is divergent. In this case, quadSwizzle*NV returns 0 for all fragments in the quad.
Hardware and API support
All intrinsics discussed in this post are available on the NVIDIA Kepler, NVIDIA Maxwell, and NVIDIA Pascal GPUs, across NVIDIA Quadro and NVIDIA GeForce graphics cards as well as on NVIDIA Tegra K1 and NVIDIA Tegra X1 mobile GPUs.
HLSL for DirectX 11 and DirectX 12
NVIDIA provides a mechanism for using the intrinsics from HLSL in DirectX 11 and DirectX 12. For more information about how to access the intrinsics using the NVIDIA NVAPI library, see Unlocking GPU Intrinsics in HLSL.
GLSL for OpenGL and Vulkan
NVIDIA drivers expose the warp shuffle and warp vote intrinsics as a series of OpenGL GLSL extensions:
GL_NV_gpu_shader5GL_NV_shader_thread_groupGL_NV_shader_thread_shuffle
This is in addition to the cross-vendor Khronos OpenGL ARB extensions:
GL_ARB_shader_group_voteGL_ARB_shader_ballot
Most differences between those are minor (subgroup instead of warp, invocation instead of thread). What is notable, however, is that the ARB extensions support implementations with maximum warp widths of 64, whereas the NVIDIA extensions assume a maximum warp width of 32 threads. This is mostly transparent to a shader developer, except that ballotARB returns the bit mask as a 64-bit integer, unlike ballotThreadNV, which returns the bitmask as a 32-bit integer.
For reference, here is how to roughly implement the cross-vendor intrinsics in terms of the native hardware functionality:
uint64_t ballotARB(bool value)
{
return uint64_t(ballotThreadNV(value));
}
float readInvocationARB(float data, uint index)
{
return shuffleNV(data, index, 32);
}
float readFirstInvocationARB(data)
{
// Do ballotThreadNV(true) to get bitmask for active threads
// Then find lowest set bit indicating first active thread
// Use then as index for shuffleNV
return shuffleNV(data, findLSB(ballotThreadNV(true)), 32);
}
The GLSL extensions discussed above are already supported by NVIDIA Vulkan drivers through VK_NV_glsl_shader, which makes them available for experimentation today!
In parallel, we are also working with the respective Khronos working groups to find the best way to bring cross-vendor shader intrinsics already standardized in OpenGL over to Vulkan and SPIR-V. We are working on Vulkan and SPIR-V extensions to expose our native intrinsics, but we prioritized the cross-vendor functionality higher, especially since there is a notable overlap in functionality.
Intrinsics cheat sheet
GLSL provides additional overloads for the shuffle functions that operate on scalar and vector flavors of float, int, unsigned int, and bool. In HLSL, those can be implemented easily using asuint and asfloat and multiple calls to the shuffle functions.
| Description | HLSL | GLSL |
|---|---|---|
| indexed shuffle | NvShfl | shuffleNVreadInvocationARBreadFirstInvocationARB |
| shuffle up | NvShflUp | shuffleUpNV |
| shuffle down | NvShflDown | shuffleDownNV |
| butterfly shuffle | NvShflXor | shuffleXorNV |
| Description | HLSL | GLSL |
| predicate true for all threads | NvAll | anyThreadNVanyInvocationARB |
| predicates equal for all threads | allThreadsEqualNVallInvocationsEqualARB | |
| broadcast predicates to thread group | NvBallot | ballotThreadNVballotARB |
| Description | HLSL | GLSL |
| horizontal | quadSwizzleXNV | |
| vertical | quadSwizzleYNV | |
| arbitrary | quadSwizzle0NVquadSwizzle1NVquadSwizzle2NVquadSwizzle3NV | |
| helper thread (fragment shader) | gl_HelperThreadNVgl_HelperInvocation |
| Description | HLSL | GLSL |
| warp size | NV_WARP_SIZE | gl_WarpSizeNVgl_SubGroupSizeARB |
| thread index (lane ID) | NvGetLaneId | gl_ThreadInWarpNVgl_SubGroupInvocationARB |
| Bit masks derived from lane ID | gl_Thread[OP]EqMaskNVgl_SubGroup[OP]MaskARBWhere OP = {Eq, Ge, Gt, Le, Lt } |
| Description | HLSL | GLSL |
| Index of current warp | gl_WarpIDNV | |
| Number of warps per SM | gl_WarpsPerSMNV | |
| Index of current SM | gl_SMIDNV | |
| Number of SMs | gl_SMCountNV |
Sample code and references
The ShuffleIntrinsicsVK sample is available in the /NVIDIAGameWorks/GraphicsSamples GitHub repo. It renders a triangle and uses various intrinsics in the fragment shader to show various use cases. For more information, see Sample Setup Guide.
- Pass through color
- Lane ID
- Tag first lane
- Tag first and last lane
- Ratio of active lanes
- Maximum across warp
- Minimum across warp
gl_WarpIDNVgl_SMIDNV
For more information, see the following resources:
- Unlocking GPU Intrinsics in HLSL
- Faster Parallel Reductions on Kepler
- CUDA Pro Tip: Do The Kepler Shuffle
- CUDA Pro Tip: Optimized Filtering with Warp-Aggregated Atomics
- Shuffle: Tips and Tricks (GTC session)
- OpenGL Blueprint Rendering (GTC session (Uses shuffle in the vertex shader to compute the length of line segments)
- DesignWorks Occlusion Culling sample (Uses shuffle for prefix sum in a compute shader)
- GL_NV_shader_thread_group
- GL_NV_shader_thread_shuffle
- GL_ARB_shader_group_vote
- GL_ARB_shader_ballot
- VK_NV_glsl_shader
- nvHLSLExtns.h File Reference
- CUDA Warp Shuffle functions
- CUDA Warp Vote functions
