
Today we are releasing TensorRT 4 with capabilities for accelerating popular inference applications such as neural machine translation, recommender systems and speech. You also get an easy way to import models from popular deep learning frameworks such as Caffe 2, Chainer, MxNet, Microsoft Cognitive Toolkit and PyTorch through the ONNX format.
TensorRT delivers:
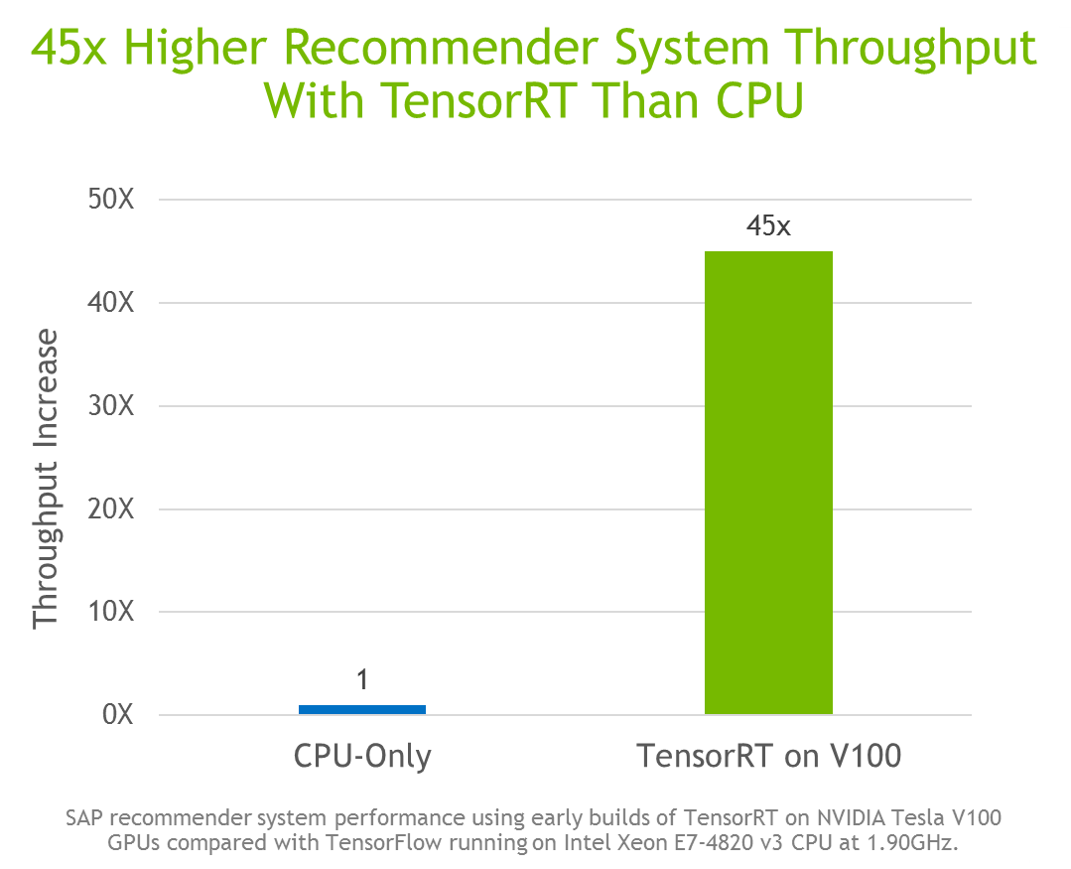
- Up to 45x higher throughput vs. CPU with new layers for Multilayer Perceptrons (MLP) and Recurrent Neural Networks (RNN)
- 50x faster inference performance on V100 vs. CPU-only for ONNX models imported with ONNX parser in TensorRT
- Support for NVIDIA DRIVE Xavier – AI Computer for Autonomous Vehicles
- 3x Inference speedup for FP16 custom layers with APIs for running on Volta Tensor Cores
Download TensorRT 4 today and try out these exciting new features!
Read more>