
The relentless pace of innovation is most apparent in the AI domain. Researchers and developers discovering new network architectures, algorithms and optimizations, drive these innovations, with much of the work done on leading-edge NVIDIA data center platforms. Tracking this progress requires standardized performance metrics, with MLPerf representing the flagship benchmarking tool for AI.
Backed by Google, Intel, Baidu, NVIDIA and dozens more technology leaders, the MLPerf v0.6 benchmark suite measures a wide range of deep learning workloads, including computer vision, language translation, and reinforcement learning tasks.
NVIDIA recently submitted MLPerf v0.6 benchmark results for all six categories, on the heels of last year’s strong showing in MLPerf 0.5:
| Usage | Network | Dataset |
| Image Classification | ResNet-50 v1.5 | ImageNet |
| Object Detection (Heavy Weight) | Mask R-CNN | COCO |
| Object Detection (Light Weight) | Single-Shot Detector | |
| Translation (Recurrent) | GNMT | WMT English-German |
| Translation (Non-Recurrent) | Transformer | |
| Reinforcement Learning | Mini-Go | Go Games from Iyama Yuta 6 Title Celebration |
In addition to improvements over our previous submissions, NVIDIA also achieved top spots in five chip-to-chip-comparisons for usages involving images, translation and reinforcement learning. And now, a single DGX-2 server can complete a training run of the ResNet-50 network in under an hour (53 minutes).
In just seven months since MLPerf debuted with version 0.5, NVIDIA has advanced per-epoch performance on MLPerf v0.6 workloads by as much as 5.1x overall. Up to 1.75x of that benefit derived from continuous software optimizations. An epoch is one complete run of passing the data set through the neural network. It’s important to consider per-epoch performance improvements, since the number of epochs needed to converge networks and required accuracy levels can change with each successive version of the network. Most importantly, much of the work done on MLPerf is integrated into our framework containers available from NGC, NVIDIA’s GPU-optimized software hub. The AI community can thus realize the benefits of these optimizations in their real-world applications, not just better benchmark scores.
We observed nearly 40% improvement across the six workloads on average. Table 2 breaks out the software improvements we achieved on each test going from MLPerf v0.5 to v0.6:
| Usage | Network | Performance Speedup |
| Image Classification | ResNet-50 | 1.24x |
| Object Detection (lightweight) | SSD | 1.2x |
| Object Detection (heavyweight) | Mask R-CNN | 1.75x |
| Non-Recurrent Translation | Transformer | 1.27x |
| Recurrent Translation | GNMT | 1.44x |
We made all our MLPerf v0.6 submissions in the Closed category, in which all systems execute the same computational work, yielding the most direct comparisons between submitted systems. MLPerf also has an Open category, where submitters are permitted to implement novel algorithmic optimizations that still achieve the required level of accuracy.
Let’s walk through the software improvements NVIDIA engineers implemented on a per-test basis:
Image Classification / ResNet-50 (1.24x improvement). Implemented new fused convolution + batchnorm kernels through cuDNN 7.6. This optimization drastically reduces the cost of batch normalization (a bandwidth-limited operation and does not benefit from Tensor Cores) by performing the normalization in adjacent convolution layers, as outlined in figure 1.
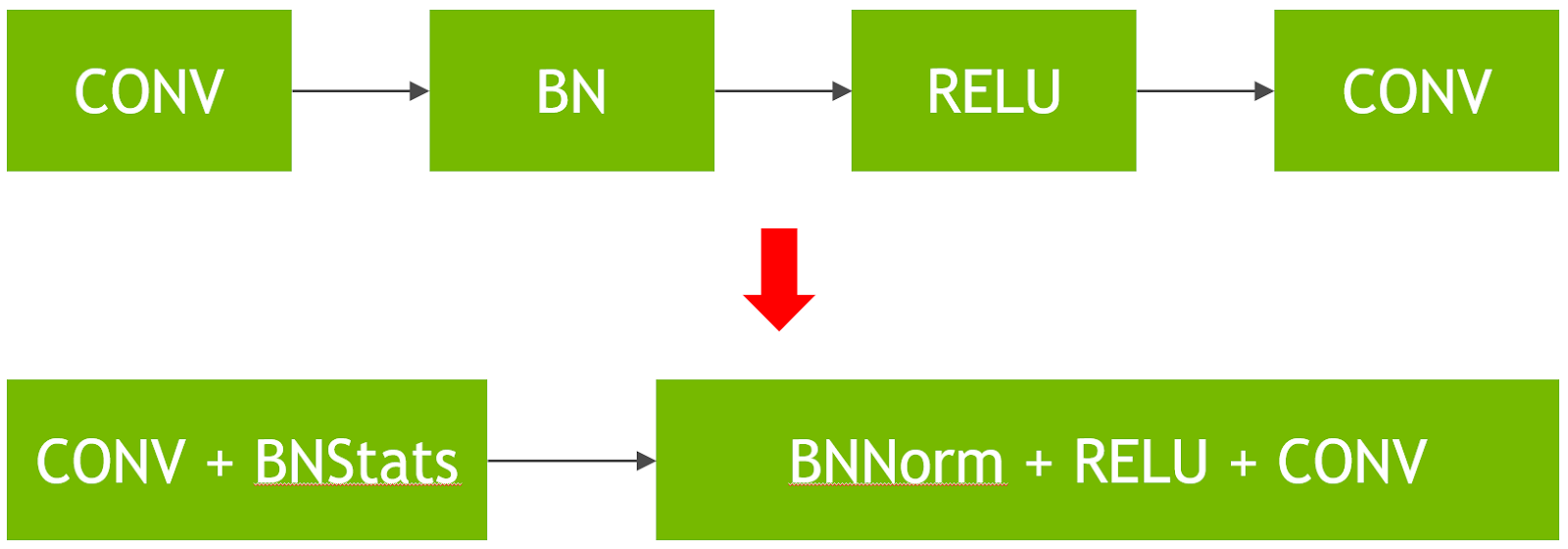
A variety of DALI-related improvements accelerated the data input pipeline, enabling it to keep up with high-speed neural network processing. These include using NVJPEG and ROI JPEG decode to limit the JPEG decode work to the region of the raw image actually used. We also used Horovod for data parallel execution, allowing us to hide the exchange of gradients between GPUs behind other back-propagation work happening on the GPU. The net result weighted in as a 5.1x improvement at scale versus our submission for MLPerf v0.5, completing this v0.6 version training run in just 80 seconds on the DGX SuperPOD. Meanwhile, a single DGX-2H server completed the training run in under an hour (53 minutes) on MLPerf v0.6.
–Lightweight Object Detection / SSD (1.2x improvement).Made use of Tensor Core native NHWC tensor layout in all segments of the network rather than only in the ResNet-34 backbone. Tensor Core accelerated convolution kernels expect NHWC (or “channels-last) layout, so using a different layout like NCHW (“channels-first”) required performing additional tensor transposes, which is limited by memory bandwidth and hurts performance. Figure 2 shows this layout simplification.

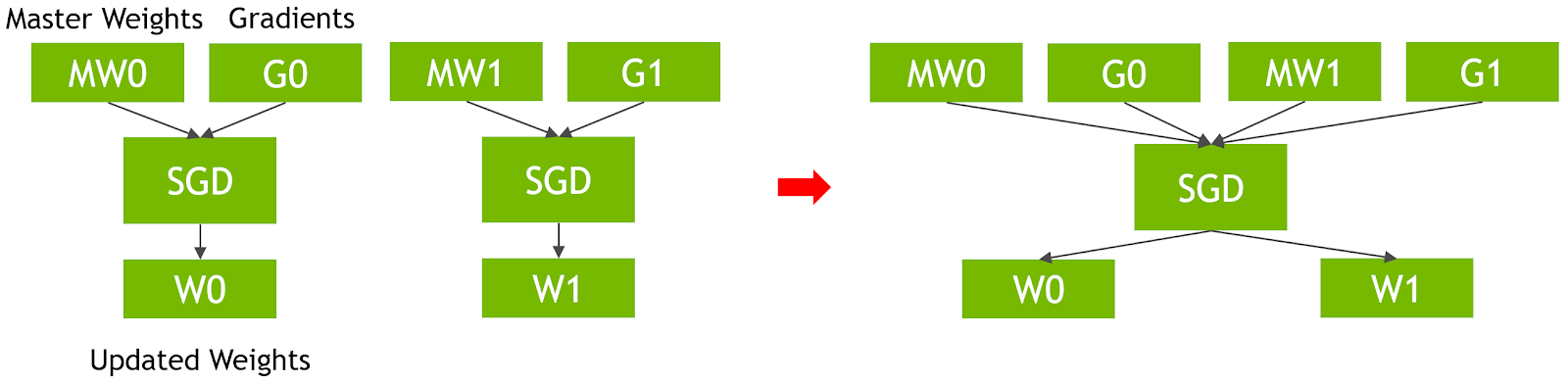
We also optimized our implementations of SSD’s loss function, fusing the SGD optimizer to use a single kernel to process all of SSD’s weights and weight gradients in a single update kernel, saving bandwidth and kernel launch costs, as shown in figure 3.
Heavyweight Object Detection / Mask R-CNN (1.75x improvement). Mask R-CNN also makes use of the Tensor Core native NHWC tensor layout in the ResNet-50 backbone network, resulting in the fastest time-to-solution of all submissions. The team also optimized the NMS implementation to run entirely on the GPU using CUDA and enhanced it to process all image/feature map pairs in a single kernel. (Previous implementation ran partially on the CPU). We also used the PyTorch JIT fuser to perform vertical fusion across non-convolution layers like the frozen batch normalization – residual add – ReLU layer sequences in the backbone network. Finally, we optimized the implementation of the SGD optimizer as well as dynamic loss scaling, similar to what was done for SSD.
Non-Recurrent Translation / Transformer (1.27x improvement). Improved the input data batching scheme to achieve greater batching efficiencies, reducing the number of padding tokens required in each batch, and implemented vertical fusion of many of the non Tensor Core accelerated layers like dropout, ReLU, residual addition, or bias. The team also optimized the softmax cross entropy loss layer by using a faster CUDA implementation that fuses the label smoothing operation. This reduced memory bandwidth usage and reduced overall memory footprint to afford larger batch sizes, which run at higher efficiency. Finally we built a custom data parallelism implementation to help hide communication latency by performing gradient exchanges while backpropagation is executing on the GPU.
Recurrent Translation / GNMT (1.44x improvement). Fused the Bahdanau attention model, which substantially reduces memory bandwidth requirements as well as memory capacity footprint by eliminating several large intermediate tensors. We fused softmax cross-entropy and label smoothing similar to what was done in Transformer and refined the Adam optimizer implementation to execute in a single kernel akin the SGD optimizations described earlier. The team also optimized PyTorch’s heuristics to decide between persistent and non-persistent implementation for LSTM layers. These persistent LSTMs help achieve significantly higher Tensor Core utilization with small batch sizes and use Apex DDP to hide data parallel communication latency behind backpropagation.
Reinforcement Learning. NVIDIA achieved another top-spot finish on this workload where we completed the training run at scale in under 14 minutes. The 0.5 implementation of this workload had significant performance bottlenecks that gated the benefit of acceleration. For this reason, NVIDIA did not submit results for this test for version 0.5. However, the MLPerf consortium members incorporated significant optimizations between versions v0.5 and v0.6 to take better advantage of acceleration, resulting in a top-spot finish.
You can find all of these optimizations in our 19.05 containers. We also make these available in our MLPerf submission code, which is an MLPerf requirement, and can be found on the MLPerf web site. Be aware that several of them are not automatic, so you may have to change your code to use some of the new customizations we’ve introduced here.
Going Big
The NVIDIA DGX SuperPOD is revolutionizing supercomputing, delivering an infrastructure solution any enterprise can use to access massive computing power to propel business innovation. SuperPOD builds on NVIDIA’s DGX-2 as its compute foundation in combination with Mellanox networking and follows the same design principles employed in DGX POD. The DGX SuperPOD provides a systemized, modular, and cost-effective approach for AI at scale. We used different numbers of server nodes for different tests for MLPerf v0.6, which mostly ran on DGX SuperPOD, shown in table 3:
| Usage | Network | Number/Type of Servers | Number of GPUs |
| Image Classification | ResNet-50 v1.5 | 96 DGX-2H Servers | 1,536 |
| Object Detection (Heavy Weight) | Mask R-CNN | 30 DGX-2H Servers | 240 |
| Object Detection (Light Weight) | Single-Shot Detector | 12 DGX-2H Servers | 192 |
| Translation (recurrent) | GNMT | 24 DGX-2H Servers | 384 |
| Translation (non-recurrent) | Transformer | 30 DGX-2H Servers | 480 |
| Reinforcement Learning | Mini-Go | 3 DGX-1 Servers | 24 |
AI training benefits from multi-node scaling. NVIDIA delivered the highest performance on three tests in this category: Object Detection (Mask R-CNN), Recurrent Translation (GNMT), and Reinforcement Learning (Mini-Go). Two of these three top-place submissions ran on our new DGX SuperPOD. All of our DGX SuperPOD submissions illustrate how this modular system can either be focused on a single mega-task or portions of it can be focused on different simultaneous tasks.
Improved Performance on the Same Hardware
MLPerf v0.6 underscores the rapid innovation happening in the AI domain. It’s also an affirmation of NVIDIA’s platform approach, where high-performance hardware is just the beginning. A complete AI platform requires a deep understanding of today’s network architectures, programmability to foster novel network architectures, strong ecosystem support, and readily-available software to realize the hardware’s full potential.
NVIDIA’s platform approach has three major tenets:
High Performance and Continuous Optimization. The NVIDIA platform with CUDA-X AI libraries and Tensor Core architecture provides the programmability to accelerate the full diversity of modern AI ensuring highest data center throughput.
Broad Ecosystem Support. The NVIDIA open platform supports the end-to-end development and deployment workflows on all frameworks and models, from training to inference, and has over a million developers. NVIDIA continues to make significant contributions to open-source AI framework software, continuously improving containerized and optimized versions of our deep learning software freely available on NGC. Much of the work that went into achieving these record levels of MLPerf 0.6 performance is included in our version 19.05 TensorFlow, MXNet and PyTorch containers.
Everywhere Availability. NVIDIA platform is available everywhere today, from desktops to servers from all server makers and all cloud services, down to embedded platforms with NVIDIA DRIVE AGX..
NVIDIA constantly improves our AI platform and makes those improvements freely available to the AI community via NGC, which you can download now. The MLPerf consortium is now hard at work on its inference workloads, to be published later this year. NVIDIA continues to work closely with the consortium to evolve the MLPerf benchmark, both for training and inference, emphasizing workload diversity in terms of usages and network architectures that reflect evolving real-world AI applications.
Appendix: MLPerf v0.6 Submission Information
Per Accelerator MLPerf Results
Per accelerator comparison using reported performance for MLPerf v0.6 NVIDIA DGX-2H (16 Tesla V100s) compared to other submissions at same scale except for MiniGo where NVIDIA DGX-1 (8 Tesla V100s) submission was used. See mlperf.org for more information.
At-Scale MLPerf Results
MLPerf ID Max Scale: Mask R-CNN: 0.6-23, GNMT: 0.6-26, MiniGo: 0.6-11 | MLPerf ID Per Accelerator: Mask R-CNN, SSD, GNMT, Transformer: all use 0.6-20, MiniGo: 0.6-10. See mlperf.org for more information.