As AI data centers rapidly evolve into AI factories, traditional network monitoring methods are no longer sufficient. Workloads continue to grow in complexity and infrastructures scale rapidly, making real-time, high-frequency insights critical. The need for effective system monitoring has never been greater.
This post explores how high-frequency sampling and advanced telemetry techniques can address these challenges and optimize AI workloads. The approach improves AI workload performance in NVIDIA Spectrum-X Ethernet fabric and provides users with proactive incident management capability.
What is AI fabric telemetry?
In the context of an AI factory, telemetry is the collection, transmission, and analysis of data related to system performance, resource usage, and other operational metrics. This real-time data is critical for managing and optimizing AI workloads.
Telemetry plays a critical role in understanding the performance and health of AI infrastructure. AI models, especially LLMs training at scale, depend heavily on high-performance computing resources. In turn, these resources rely on seamless data transfer between components such as GPUs, CPUs, and storage systems.
Why does streaming network telemetry matter for AI?
Traditional network monitoring relies on polling-based techniques, querying devices at fixed intervals (every few seconds or minutes, for example). This approach often misses short-lived anomalies or transient network issues, which can severely impact the performance of AI workloads.
As a result, traditional monitoring systems come with significantly reduced granularity and visibility. Because these transient issues occur within milliseconds and disappear just as quickly, they often go undetected. As a result, they can disrupt AI workloads, LLM operations, and inference traffic without leaving any trace—wasting valuable GPU cycles, increasing processing time, and reducing overall system efficiency.
In contrast, modern telemetry streams data continuously at high frequencies, providing granular, real-time visibility into network performance. This enables proactive incident management rather than reactive troubleshooting, and scales to handle data generated by hundreds or even thousands of nodes and GPUs.
This is particularly critical in AI workloads, where milliseconds matter and synchronization across GPUs is key to performance.
Moreover, approaching issues from a network perspective alone might not indicate such anomalies. An AI-focused, holistic monitoring approach yields the best results in these intricate environments.
Providing visibility into RDMA networks
One of the most crucial needs for AI system telemetry is visibility into Remote Direct Memory Access (RDMA) networks. RDMA technology accelerates data transfers by allowing direct memory access between systems without involving the CPU. This greatly improves throughput and reduces latency, enabling AI workloads to run faster and better utilize fabric capacity.
In order for RDMA to perform at its best, it relies on the network being truly lossless. However, AI workloads are sensitive to network issues, and even small inefficiencies can have a cascading effect on overall performance. According to recent research, RDMA is particularly sensitive to network issues and impacts GPU training efficiency. For more details, see RDMA over Ethernet for Distributed AI Training at Meta Scale and RoCE Networks for Distributed AI Training at Scale.
AI workloads—especially those using the NVIDIA Collective Communications Library (NCCL)—rely on low-latency, high-throughput, and lossless communication between nodes. Issues like jitter, congestion, or packet loss can significantly degrade model training or inference performance.
High-frequency telemetry is essential because it enables operators to:
- Detect issues such as packet loss or hardware faults in real time
- Maintain SLA guarantees through proactive troubleshooting
- Optimize network utilization, resource allocation, and load balancing
- Ensure scalability across large clusters with data-driven decision-making
Without proper telemetry, detecting these hidden RDMA-related problems—such as congestion, microsecond-level latency spikes, and packet loss—is not possible. Telemetry systems, therefore, are essential for identifying and diagnosing these issues in real time, ensuring that AI models can be trained and deployed without unnecessary slowdowns or bottlenecks.
In addition, performance profiling of AI workloads can be done with unprecedented granularity, enabling analysis of patterns, performance in production, and more.
NVIDIA Spectrum-X Ethernet AI fabric with built-in telemetry
NVIDIA Spectrum-X Ethernet is an Ethernet-based AI fabric solution, purpose-built for high-performance AI workloads. Spectrum-X Ethernet brings data center fabric together with complex AI workloads running over large-scale AI factories, enabling them to work together.
Spectrum-X Ethernet tightly integrates:
- NVIDIA Spectrum SN5000 Series Ethernet switches
- NVIDIA BlueField-3 SuperNICs and NVIDIA ConnectX-8 SuperNICs
- NVIDIA Hopper, Blackwell, and Rubin GPUs
- NVIDIA NetQ telemetry and analytics platform
- Cumulus Linux network operating system

Each component contributes its own telemetry data, collectively providing a holistic view of the fabric’s health and performance. To provide a few examples:
- DTS SuperNIC telemetry may show the number of packets marked for adaptive routing.
- The switch telemetry may show the actual routing decisions made.
- NetQ collects, correlates, and visualizes this data through a single-pane-of-glass interface, presenting the data to the user based on NVIDIA AI expertise. It basically converts raw telemetry data from various sources into AI insights.
With this insight-oriented telemetry system, identifying and resolving network issues becomes intuitive and accessible.
Open standards for extensibility
To be effective, a telemetry system must be open and vendor-neutral. Spectrum-X Ethernet supports:
- OpenTelemetry interface
- gRPC Network Management Interface (gNMI)
This enables:
- Interoperability with a variety of third-party tools
- Extensibility across heterogeneous environments
- Comprehensive metric coverage for deep root cause analysis
Example 1: Troubleshooting an LLM workload
To refine Spectrum-X Ethernet telemetry, NVIDIA engineers continuously run stress tests, using real AI workloads, on the NVIDIA Israel-1 supercomputer.
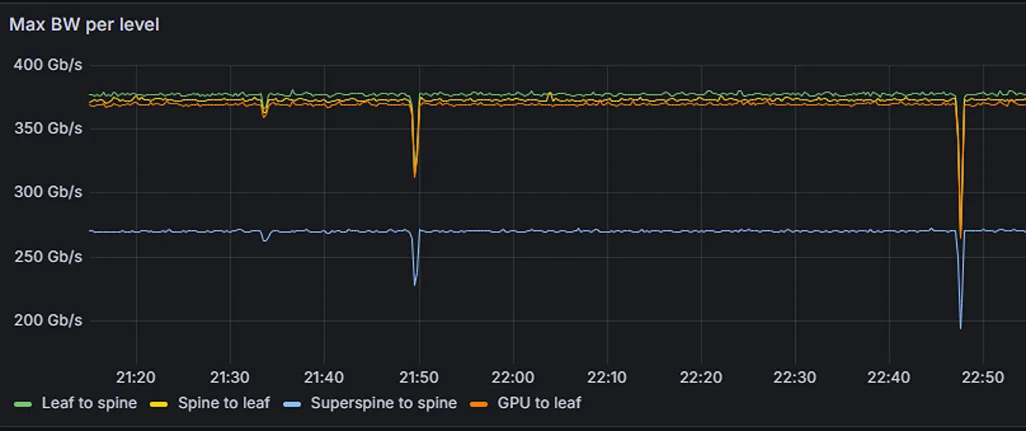
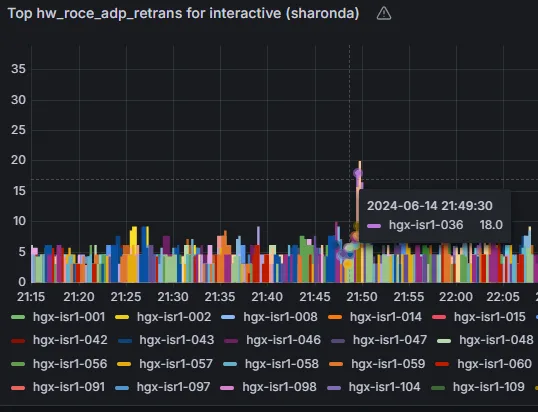
Figures 2-5 show a Grafana dashboard that uses PromQL as a data source. Grafana connects to NetQ and queries time-series databases using PromQL queries. NetQ collects real-time OTLP telemetry metrics from Spectrum Ethernet switches, GPUs, NICs, hosts (through DTS) and SLURM AI workloads. Finally, Grafana acts as a visualization layer, connecting to NetQ PromQL API to create dashboards and graphs that display these metrics.
A long-running LLM workload was expected to utilize maximum bandwidth. However, telemetry showed sharp, irregular drops in effective bandwidth (Figure 2).
On further inspection, BlueField-3 DTS (through NetQ) showed high roce_adp_retrans counters, indicating RoCE packet retransmissions (Figure 3).
Switch telemetry pinpointed symbol errors on a specific port (swp11s1) on a spine switch (Figure 4).
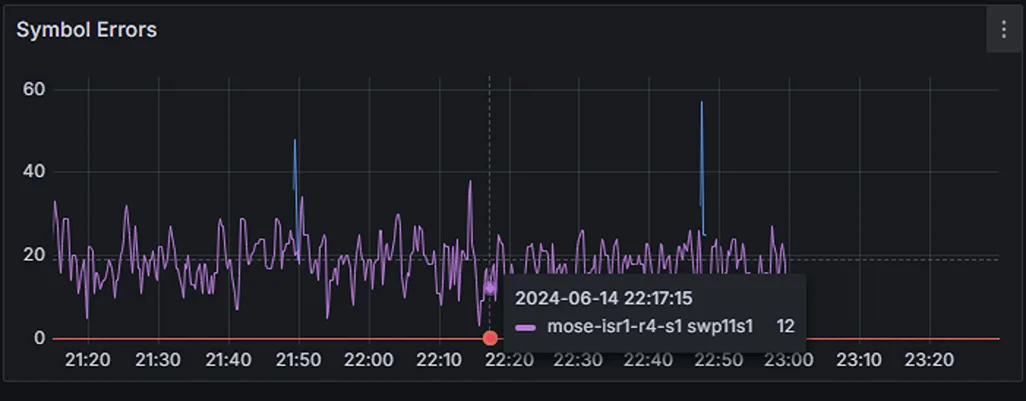
After disabling the faulty port, bandwidth usage fully recovered, confirming the root cause (Figure 5).
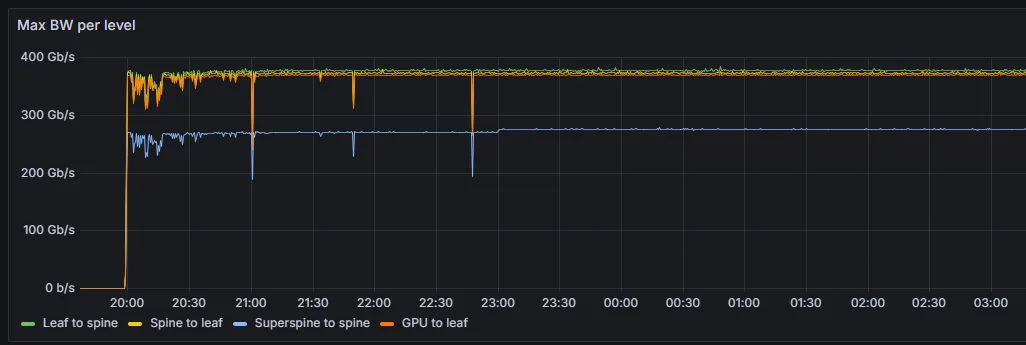
As this example shows, the Spectrum-X telemetry solution collects raw telemetry data from the AI fabric through multiple sources and transforms it into actionable insights.
Example 2: Detecting misconfigurations in the fabric
Another use case for Spectrum-X Ethernet telemetry solution is constant granular monitoring of fabric traffic could indicate misconfigurations in the fabric. In a healthy Spectrum-X Ethernet fabric, RoCE traffic is perfectly balanced across spine/leaf links. This can be observed in a granular way from NetQ, thanks to Spectrum-X Ethernet real-time telemetry. In the case, this perfect distribution is not seen on the fabric, we are able to conclude that there are configuration differences between leaf switches as this would be the only reason for such imbalance.
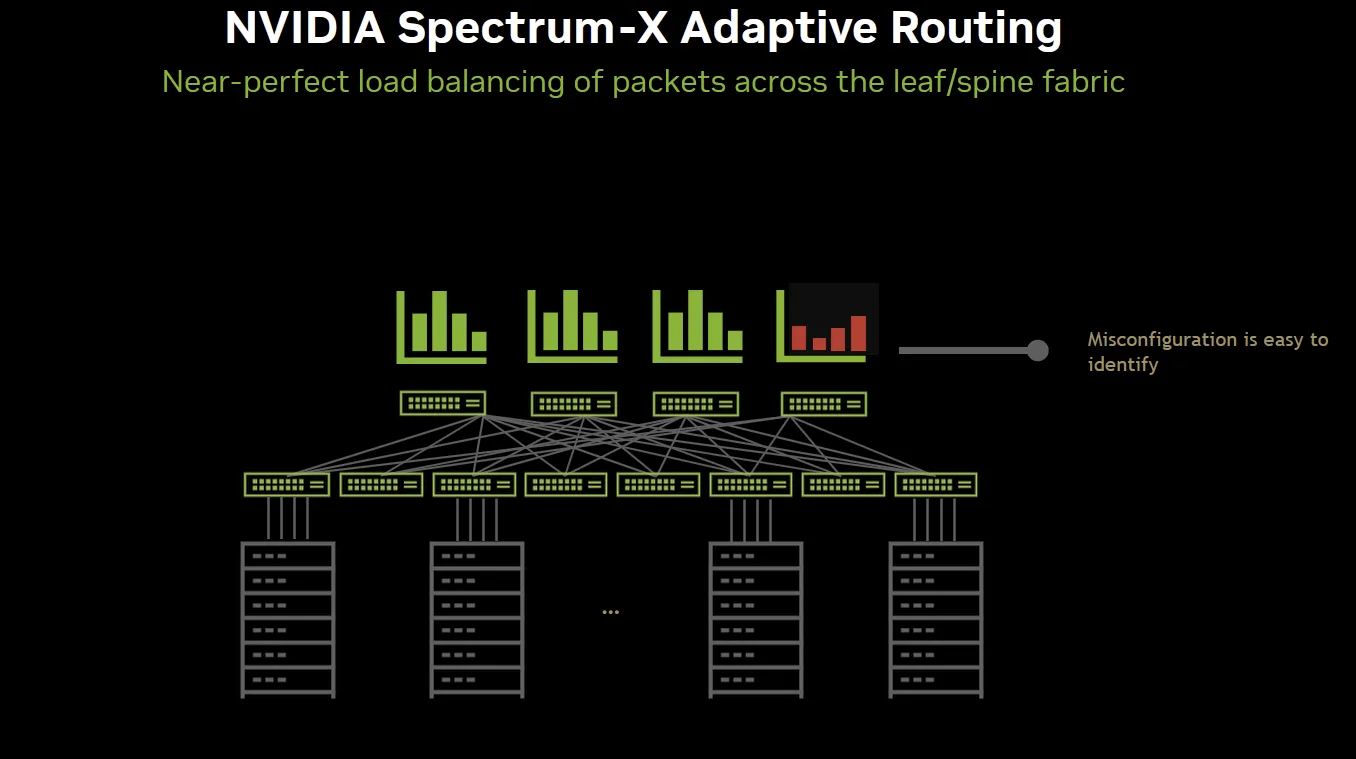
Get started with NVIDIA Spectrum-X Ethernet
AI workloads demand extremely high performance, minimal latency, and maximum reliability. Only a holistic telemetry approach spanning across the application, GPUs, SuperNICs, and switch fabric can provide the real-time insights needed to meet those demands.
With Spectrum-X Ethernet, NVIDIA delivers an integrated solution that ensures AI infrastructure is efficient, predictable, and resilient. Learn more about the NVIDIA Spectrum-X Ethernet networking platform.