
Reinforcement learning from human feedback (RLHF) is essential for developing AI systems that are aligned with human values and preferences. RLHF enables the most capable LLMs, including ChatGPT, Claude, and Nemotron families, to generate exceptional responses.
By integrating human feedback into the training process, RLHF enables models to learn more nuanced behaviors and make decisions that better reflect user expectations. This approach enhances the quality of AI-generated responses and fosters trust and reliability in AI applications.
To help the AI community easily adopt RLHF to build and customize models, NVIDIA released Llama 3.1-Nemotron-70B-Reward, a state-of-the-art reward model that scores the responses generated by LLMs. Such scores can be used to improve LLM response quality, making a more positive and impactful interaction between humans and AI.
NVIDIA researchers leveraged the reward model to train Llama 3.1-Nemotron-70B-Instruct model, which is among the top models on Arena Hard leaderboard.
#1 reward model
The Llama 3.1-Nemotron-70B-Reward model currently is in first place on the Hugging Face RewardBench leaderboard for evaluating the capabilities, safety, and pitfalls of reward models.
The model scored 94.1% on Overall RewardBench, meaning that it can identify responses that align with human preferences 94% of the time.
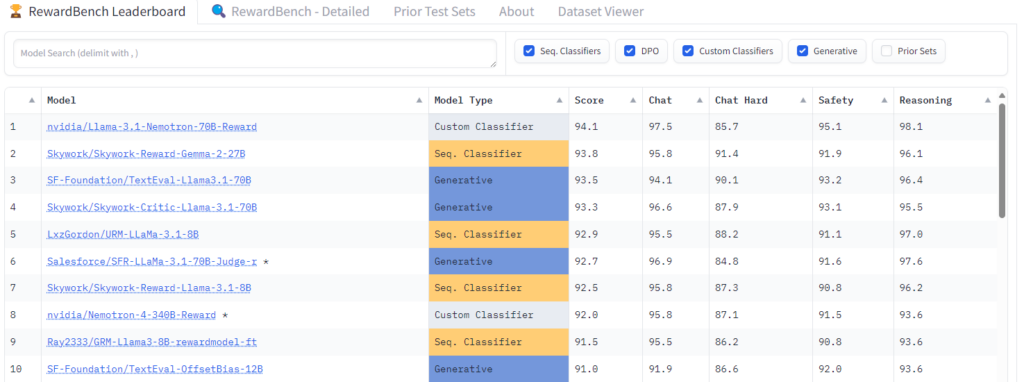
The model scores well across all four categories: Chat, Chat-Hard, Safety, and Reasoning. It has an impressive performance for Safety and Reasoning, achieving 95.1% and 98.1% accuracy, respectively. This means that the model can safely reject potential unsafe responses and support RLHF in domains like math and code.
With just a fifth the size of Nemotron-4 340B Reward, this model delivers high compute efficiency coupled with superior accuracy. This model is also trained only on CC-BY-4.0-licensed HelpSteer2 data, which makes it feasible for enterprise use cases.
Implementation
To train this model, we combined two popular approaches to make the best of both worlds:
We trained with both approaches using data that we released in HelpSteer2. An important contributor to the model performance is high data quality, which we meticulously curated and then released to advance AI for all.
Leading large language model
Using the trained Reward Model and HelpSteer2-Preference Prompts for RLHF training (specifically with the REINFORCE algorithm) produces a model that scores 85 on Arena Hard, a popular automatic evaluation tool for instruction-tuned LLMs. This makes this the best leading models on the Arena Hard Leaderboard, among models that do not require additional test-time compute.
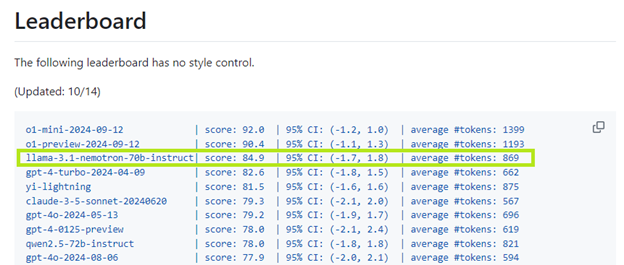
The Llama-3.1-Nemotron-70B-Instruct model comes with Llama-3.1 License, making it easy for research and enterprises to customize and integrate this model in their applications.
Easy deployment with NVIDIA NIM
The Nemotron Reward model is packaged as an NVIDIA NIM inference microservice to streamline and accelerate the deployment of generative AI models across NVIDIA-accelerated infrastructure anywhere, including cloud, data center, and workstations.
NIM uses inference optimization engines, industry-standard APIs, and prebuilt containers to provide high-throughput AI inference that scales with demand.
Getting started
Experience the Llama 3.1-Nemotron-70B-Reward model from a browser today or test it at scale and build a proof of concept (PoC) with the NVIDIA-hosted API endpoint running on a fully accelerated stack. The Llama 3.1-Nemotron-70B-Instruct model can also be accessed here.
Get started at ai.nvidia.com with free NVIDIA cloud credits or download the model from Hugging Face.
For more information about how the model was trained and can be used for RLHF, see HelpSteer2-Preference: Complementing Ratings with Preferences.
This blog was updated on 10/21/2024.
