
Training AI models is an extremely time-consuming process. Without proper insight into a feasible alternative to time-consuming development and migration of model training to exploit the power of large, distributed clusters, training projects remain considerably long lasting. To address these issues, Samsung SDS developed the Brightics AI Accelerator. The Kubernetes-based, containerized application, is now available on the NVIDIA NGC catalog – a GPU-optimized hub for AI and HPC containers, pre-trained models, industry SDKs, and Helm charts that helps simplify and accelerate AI development and deployment processes.
The Samsung SDS Brightics AI Accelerator application automates machine learning, speeds up model training and improves model accuracy with key features such as automated feature engineering, model selection, and hyper-parameter tuning without requiring infrastructure development and deployment expertise. Brightics AI Accelerator can be used in many industries such as healthcare, manufacturing, retail, automotive and across different use cases spanning computer vision, natural language processing and more.
Key Features and Benefits:
- Is case agnostic and covers training all AI models by applying autoML to tabular, CSV, time-series, image or natural language data to enable analytics; image classification, detection, and segmentation; and NLP use cases.
- Offers model portability between cloud and on-prem data centers and provides a unified interface for orchestrating large, distributed clusters to train deep learning models using Tensorflow, Keras and PyTorch frameworks as well as autoML using SciKit-Learn.
- AutoML software automates and accelerates model training on tabular data by using automated model selection from Scikit-Learn, automated feature synthesis, and hyper-parameter search optimization.
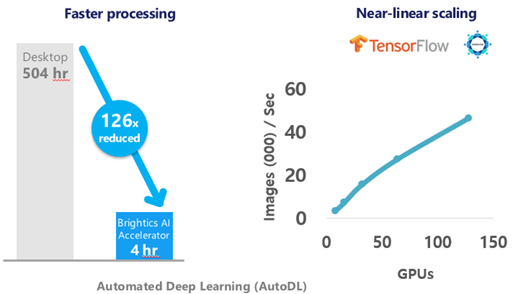
- Automated Deep Learning (AutoDL) software automates and accelerates deep learning model training using data-parallel, distributed synchronous Horovod Ring-All-Reduce Keras, TensorFlow, and PyTorch frameworks with minimal code. AutoDL exploits up to 512 NVIDIA GPUs per training job to produce a model in 1 hour versus 3 weeks using traditional methods.
Get started by pulling Samsung’s Brightics AI Accelerator container from the NGC catalog.
