
A team of researchers from MIT just built a robot and developed a deep learning-based system that can play Jenga, a game in which players take turns removing blocks and placing them on the top of the structure to make it taller and more unstable.
The robot uses a soft gripper and a computer vision system to strategically pull and place the blocks.
Details of the Jenga-playing system were recently published in the Science Robotics journal.
What makes the work unique is that Jenga is a complex game that requires physical interaction for effective gameplay. The system developed by the team can infer block behavior patterns and states as it plays the game. The approach has the potential to help robots assemble electronic devices such as smartphones and other small parts in a manufacturing line.
“Unlike in more purely cognitive tasks or games such as chess or Go, playing the game of Jenga also requires mastery of physical skills such as probing, pushing, pulling, placing, and aligning pieces. It requires interactive perception and manipulation, where you have to go and touch the tower to learn how and when to move blocks,” said Alberto Rodriguez, Assistant Professor in the Department of Mechanical Engineering at MIT. “This is very difficult to simulate, so the robot has to learn in the real world, by interacting with the real Jenga tower. The key challenge is to learn from a relatively small number of experiments by exploiting common sense about objects and physics.”
Using a standard robotic arm, an RGB camera, and two NVIDIA TITAN X GPUs with the cuDNN-accelerated PyTorch deep learning framework, the team set up a Jenga tower within the robot’s reach and taught it to play the game.
“Rather than carry out tens of thousands of such attempts (which would involve reconstructing the tower almost as many times), the robot trained on just about 300, with attempts of similar measurements and outcomes grouped in clusters representing certain block behaviors,” the MIT team wrote in a blog post.
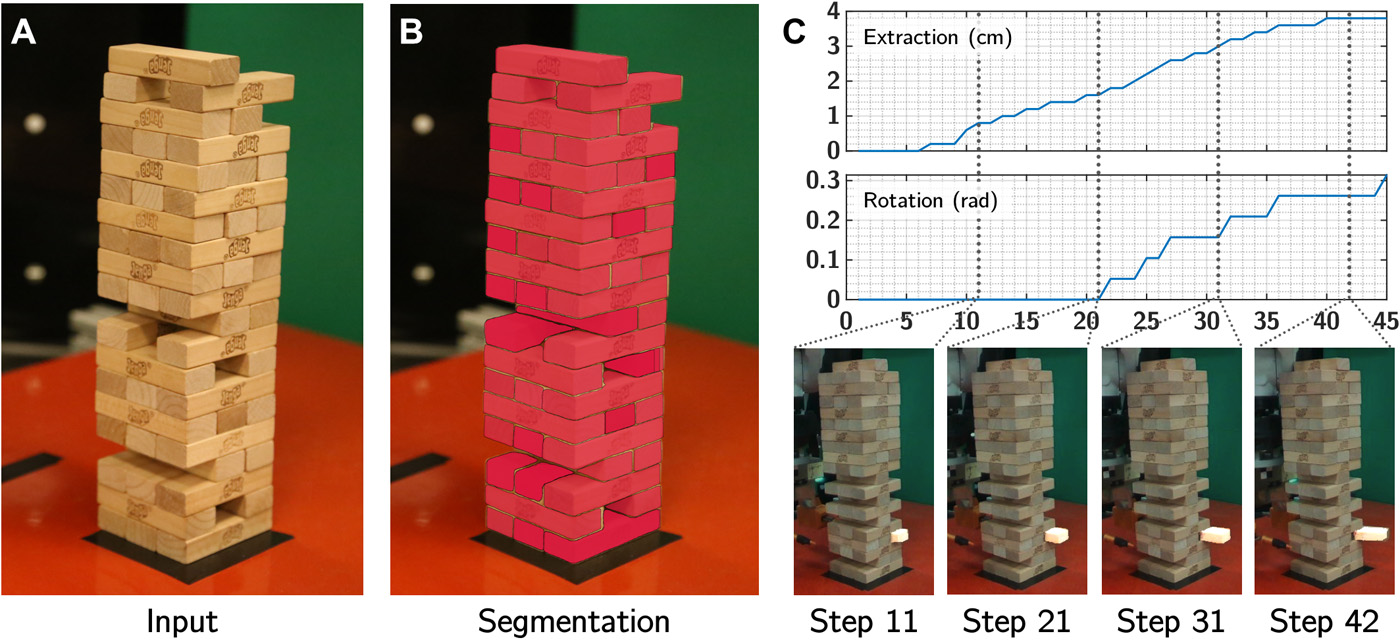
For the visual perception system, the team used the Mark-R-CNN system pretrained on Res-Net-50.
For future projects, the researchers are interested in transferring the robot’s newly learned skills to other applications.
“There are many tasks that we do with our hands where the feeling of doing it ‘the right way’ comes in the language of forces and tactile cues,” Rodriguez says. “For tasks like these, a similar approach to ours could figure it out.”
Read more>
AI-Generated Summary
- A team of researchers from MIT developed a robot that can play Jenga using a deep learning-based system, which can infer block behavior patterns and states as it plays.
- The robot uses a soft gripper and a computer vision system, powered by two NVIDIA TITAN X GPUs, to strategically pull and place blocks, and it learned to play the game by interacting with the real Jenga tower.
- The researchers trained the robot on just 300 attempts, grouping similar measurements and outcomes into clusters representing certain block behaviors, and they plan to transfer the robot's skills to other applications in the future.
AI-generated content may summarize information incompletely. Verify important information. Learn more
About the Authors
Leave a Reply
You must be logged in to post a comment.