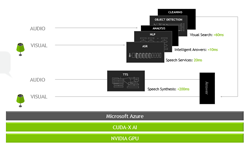
Delivering speech-driven recommendations in real time with NVIDIA GPU Inference
When you ask your phone a question, you don’t just want the right answer. You want the right answer, right now. The answer to this seemingly simple question requires an AI-powered service that involves multiple neural networks that have to perform a variety of predictions and get an answer back to you in under one second so it feels instantaneous. These include:
- Object Detection: Detecting objects within a picture, grouping into categories and returning a bounding box around that object with shopping suggestions. Object Detection neural networks like SSD (Single Shot Detection) and RetinaNet usually have common classification networks as backbones like ResNet-50.
- Question-and-Answer: often deployed as attention-based recurrent or sequence-based neural networks, this workload stage seeks to provide a high-quality and accurate answer to the question being asked. An example model that has recently gained attention across multiple NLP tasks, including question and answer, is BERT or Bidirectional Encoders for representations of transformers.
- Text-to-Speech (TTS): takes answers from the Q&A stage and converts it into natural-sounding speech that plays back on your phone. TTS typically uses vocoder parallel networks like WaveNet and Tacotron2.
All of these AI networks independently and therefore alltogether must compute a response within a small latency window. As Microsoft began building this service on its Bing platform using CPU-only servers, they quickly realized these platforms couldn’t perform the computational work within the required latency budget very millisecond counts to deliver a delightful end user experience. The team then switched over to NVIDIA GPUs, and quickly saw massive speedups in the visual search, the question-answer and text-to-speech pipeline stages that reduced the end-to-end latency by 5x to just 500ms.
Speedups along the way included more than double the number of documents scanned with higher accuracy in the question-answer stage of the workflow. And for text-to-speech, Tesla V100 simultaneously delivers 20 real-time speech responses, while CPU-only servers simply couldn’t execute anywhere near the necessary latency budget. GPU acceleration improved Azure’s conversational AI, and give more human-like and clearer intonation of words. As neural speech synthesizers achieve human accuracy, the complexity of networks require serious computation. An average speech response is about 4 seconds and previously it took 5 seconds to generate 1 second of speech (or 20 seconds!). Now Microsoft text-to-speech can generate 1 second of speech in 50 ms with V100, a 100x improvement!
To try this experience yourself you can visit the Bing web site.
![]()
![]() By Dave Salvator, Senior Manager, Product Marketing
By Dave Salvator, Senior Manager, Product Marketing