 The detection of malicious software (malware) is an increasingly important cyber security problem for all of society. Single incidences of malware can cause millions of dollars in damage. The current generation of anti-virus and malware detection products typically use a signature-based approach, where a set of manually crafted rules attempt to identify different groups of known malware types. These rules are generally specific and brittle, and usually unable to recognize new malware even if it uses the same functionality.
The detection of malicious software (malware) is an increasingly important cyber security problem for all of society. Single incidences of malware can cause millions of dollars in damage. The current generation of anti-virus and malware detection products typically use a signature-based approach, where a set of manually crafted rules attempt to identify different groups of known malware types. These rules are generally specific and brittle, and usually unable to recognize new malware even if it uses the same functionality.
This approach is insufficient because most environments have unique binaries that will have never been seen before and millions of new malware samples are found every day. The need to develop techniques that can adapt to the rapidly changing malware ecosystem is seemingly a perfect fit for machine learning. Indeed, a number of startups and established cyber-security companies have started building machine learning based systems. These companies typically spend considerable effort in feature engineering and analysis to build high quality systems. But what if we could build an anti-virus system without any feature engineering? That could allow the same system to detect malware across a variety of operating systems and hardware. We demonstrate a significant step towards this goal in our most recent research paper.
CREDIT: The work and paper described in this blog post was completed in collaboration with Edward Raff, Jared Sylvester, Robert Brandon and Charles Nicholas who collectively represent the Laboratory for Physical Sciences, Booz Allen Hamilton and University of Maryland, Baltimore County, in addition to Bryan Catanzaro who leads the NVIDIA Applied Deep Learning Research Team.
The paper introduces an artificial neural network trained to differentiate between benign and malicious Windows executable files with only the raw byte sequence of the executable as input. This approach has several practical advantages:
- No hand-crafted features or knowledge of the compiler used are required. This means the trained model is generalizable and robust to natural variations in malware.
- The computational complexity is linearly dependent on the sequence length (binary size), which means inference is fast and scalable to very large files.
- Important sub-regions of the binary can be identified for forensic analysis.
- This approach is also adaptable to new file formats, compilers and instruction set architectures—all we need is training data.
We also hope this paper demonstrates that malware detection from raw byte sequences has unique and challenging properties that make it a fruitful research area for the larger machine learning community.
Challenges in Applying Deep Learning to Malware Detection
One reason for the recent success in applying neural networks to computer vision, speech recognition and natural language processing is their ability to learn features from raw data such as pixels or individual text characters. Inspired by these successes, we wanted to see if a neural network could be trained on just the raw bytes of an executable file to determine if the file is malware. If we could achieve this, we may be able to greatly simplify the tools used for malware detection, improve detection accuracy and identify non-obvious but important features exhibited by malware.
However, there exist a number of challenges and differences in the malware domain that have not been encountered in other deep learning tasks. For Microsoft Windows Portable Executable (PE) malware, these challenges include:
- Treating each byte as a unit in an input sequence means we are dealing with a sequence classification problem on the order of two million time steps. To our knowledge, this far exceeds the length of input to any previous neural-network-based sequence classifier.
- The bytes in malware can have multiple modalities of information. Any particular byte taken in context could be encoding human-readable text, binary code, or arbitrary objects such as images and more. Furthermore, some of this content may be encrypted and essentially random to the neural network.
- The contents of a binary at the function level can be arbitrarily re-arranged with little effort, but there is complicated spatial correlation across functions due to function calls and jump commands.
Little work has been done on sequence classification at the scale explored in this paper. Audio is the closest domain in pure sequence length. A state of the art network such as WaveNet uses raw bytes of audio as it’s input and target, but this still only results in a sequence analysis problem with tens of thousands of steps—two orders of magnitude smaller compared to our malware detection problem.
Sequences in the millions of steps present significant practical challenges when used as the input to a neural network with parameter choices in the ranges commonly used in natural language processing and audio processing. Principle among these is the memory footprint of the activations between layers in the network. For example, if the raw bytes of a two-million-step sequence were represented using a 300-dimensional trainable embedding layer in 32-bit floating point that input would immediately require nearly 2.4 GB of memory. If it were then passed into a length-preserving 1D convolution layer with filter size 3 and 128 filters, the activations of that one layer alone would require another 1GB of memory. Remember that this is for a single input sequence to a single layer, not a minibatch as is commonly used in neural network training.
Breaking down the sequence into subsequences processed individually won’t work either as the indicators of malware can be sparse and distributed throughout the file, so there is no way to map global labels for a training file to subsequences without introducing an overwhelming amount of noise. Furthermore, having only one label for all two million time steps of an input sequence with sparse discriminative features makes for an extremely challenging machine learning problem due to a very weak training signal.
Our Solution
We experimented with a large number of different neural network architectures for this problem. The challenges outlined above led us to try to some unusual architectures and parameter choices. The search for better-performing architectures required balancing increasing the number of trainable parameters in the model with keeping the memory footprint of the activations small enough to allow a large enough mini-batch size to be used so that training times were practical and training converged.
When designing the model we aimed for three features:
- the ability to scale efficiently in computation and memory usage with sequence length
- the ability to consider both local and global context while examining the entire file, and
- an explanatory ability to aid analysis of flagged malware.
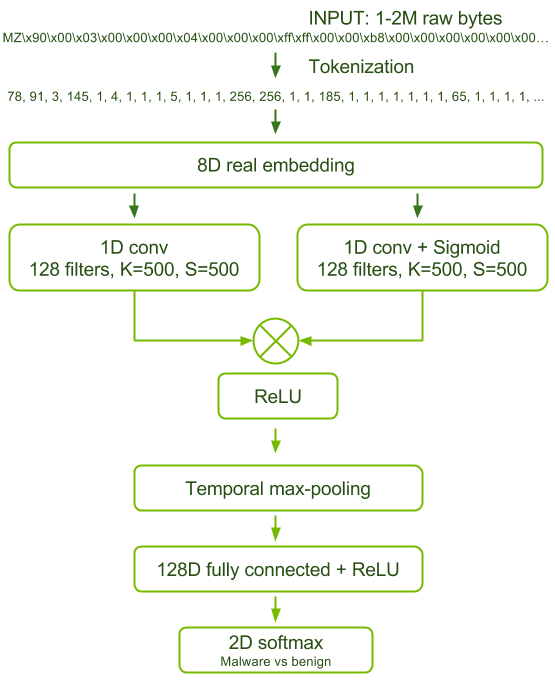
In the end, the best performing model is certainly atypical in its small number of trainable parameters (134,632) and shallow architecture. Figure 1 shows a block diagram of this model.
We were able to achieve 1) while maximizing the network’s number of trainable parameters by using a gated convolution architecture and a trainable embedding vector representation of the input bytes. In the gated architecture, for each convolution layer there is a second parallel convolution layer with sigmoid activation. The elementwise product of the outputs of these two parallel layers is passed to the reLU non-linearity. This enables the sigmoid convolution layer to filter the information allowed out of the reLU convolution layer, which adds additional capacity to the model’s feature representations in an efficient way.
We controlled the memory footprint of the convolution layer activations using aggressive striding and large convolutional filter sizes. Intuitively, it seems like these choices would degrade model accuracy, however we found in our experiments that finer convolutions and smaller striding did not lead to a better performing architecture.
We achieved 2) by following the convolutional layer with global max pooling. One way to interpret the function of this network is that the gated convolutional layer is able to recognize local indicators of malware and the max pooling followed by fully connected layer assesses the relative strength of those indicators throughout the file and recognizes significant global combinations.
A consistent result across tested architectures is a propensity for overfitting. This is not surprising given the large input feature space from which we must learn the benign/malicious classification using a single loss. We found that penalizing the correlation between hidden state activations at the fully connected layer, as described in [Cogswell et al. 2016], to be the most effective form of regularization. Intriguingly, we found that the commonly used batch-normalization actually prevented our models from converging and generalizing. See Section 5.3 of the paper for further discussion on why this might be the case.
Data and Training
We used two datasets to train and validate this network. We collected the first set, Group A, from publicly available sources. The benign data came from a clean installation of Microsoft Windows with some commonly installed applications and the malware came from the VirusShare corpus. Group A contains 43,967 malicious and 21,854 benign files. The second set, Group B, was provided by an industry anti-virus partner with both benign and malicious files representative of files seen on real machines in the wild. Group B contains 400,000 unique files split evenly between benign and malicious classes. Group B also includes a test set of 74,349 files of which 40,000 are malicious and the remainder benign.
We found that training on Group A results in severe overfitting, resulting in models that learn to recognize “from Microsoft” instead of “benign”. A model trained on Group A does not generalize to Group B. However, we found that a model trained on Group B does generalize to Group A. Therefore we performed our experiments by training on Group B and testing on both Group A and the Group B test set. Testing in this manner allows us to better quantify generalizability as the data are from different sources. We consider Group A’s test performance as most interesting because the data has the fewest common biases with Group B, although we want our model to have similar performance on both test sets to indicate the features learned are widely useful.
In addition, late in our experimentation we received a larger training corpus from the same source as Group B containing 2,011,786 unique binaries with 1,011,766 malicious files.
In order to get model convergence in a timely manner it was essential to train the network using a large batch size. Due to the extreme memory usage of the network activations this necessitated the use of data parallel model training. We were able to train this model on the 400,000-sample Group B training set using data parallelism across eight GPUs of a DGX-1 in about 16.75 hours per epoch, for 10 epochs, and using all available GPU memory. Training on the larger two-million-sample set took one month on the same system.
Results
The most pertinent metric in evaluating the performance of our model is AUC. This is due to the need to perform malware triage where a queue of binaries is created for quarantine and manual analysis based on a priority scoring. A high AUC score (close to 1) corresponds to successful ranking of most malware above most benign files. It is critical to achieve this high AUC because manual analysis of a single binary by an expert malware analyst can take in excess of 10 hours. AUC also has the benefit of allowing us to compare performance across our two test datasets with differing numbers of benign and malicious samples.
Table 1 shows the performance of our model compared to the best performing models already in the literature. The first of those models uses raw byte n-grams as the input features to a logistic regression model [Raff et al. 2016]. The second model applies a shallow fully-connected neural network to byte n-grams taken from the file PE-Header only [Raff et al. 2017]. Table 1 shows the best results in bold.
| Train set | Test set | Our model AUC | Byte n-grams AUC | PE-Header Network |
|---|---|---|---|---|
| Group B train (small) | Group A | 98.5 | 98.4 | 97.7 |
| Group B train (small) | Group B test | 95.8 | 97.9 | 91.4 |
| Group B train (large) | Group A | 98.1 | 93.4 | – |
| Group B train (large) | Group B test | 98.2 | 97.0 | – |
Looking at the results, you can see that our model is best for Group A and second best for Group B. However, when we train using the larger corpus of 2 million files we find that our model continues to improve, becoming the best performing model on both test sets, whilst the performance of the byte n-gram model actually degrades. This indicates a brittleness and propensity to overfit in the byte n-gram model.
Practical Applicability
In the paper we additionally report the balanced test accuracy of the models in our experiments, that is their ability to differentiate benign and malware files with equal importance given to each. While our model performs favorably under this metric it is not necessarily indicative of model performance in real-world conditions. There are a variety of use cases for a malware detection system. For high-volume triage of files, throughput is king, meaning that there may be a lower tolerance for false alarms. In other settings false alarms may be acceptable in return for high sensitivity; in other words, true malware is rarely missed.
In either case, the result of a detection will be some form of more detailed analysis of the potential malware, often by an expert malware analyst. We wanted to ensure our network has some ability to explain its classification decisions to help focus the attention and time of an analyst. We did this by taking inspiration from the class activation map (CAM) technique of [Zhou et al. 2016]. For each of the classes benign and malware we produce a map of the relative contribution of each filter at its most active application location in the convolution layer. You can think of this as identifying which regions contribute most to the benign or malware classification. We call our modification sparse-CAM because using global max pooling rather than average pooling leads to a naturally sparse activation map. Figure 2 illustrates sparse-CAM.
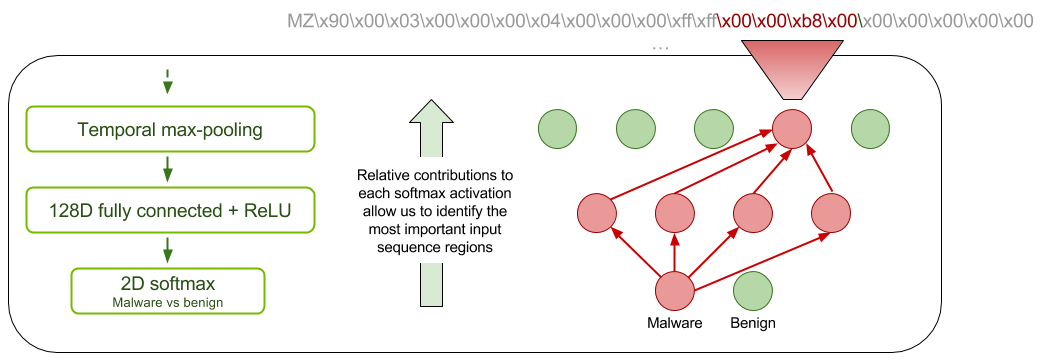
Previous work showed that the byte n-gram model obtained almost all of its discriminative information from the header of the executable file. This means that byte n-gram models do not typically use the actual executable code or data sections of the file as discriminative features. The results in Table 1 show that, in our tests, models that have access to the entire executable file achieve higher classification accuracy than those that are restricted to just the file header.
Analysis of the sparse-CAM for 224 randomly selected binaries by an expert malware analyst revealed that our model had 39-42% of it’s most important features located outside of the file header. In particular we saw indications of both executable code and data containing discriminative features.
| Section | Total | PE-Header | .rsrc | .text | UPX1 | CODE | .data | .rdata | .reloc |
|---|---|---|---|---|---|---|---|---|---|
| Malicious | 26,232 | 15,871 | 3,315 | 2,878 | 697 | 615 | 669 | 383 | 214 |
| Benign | 19,290 | 11,183 | 2,653 | 2,414 | 596 | 505 | 423 | 243 | 77 |
Conclusion
This paper shows that neural networks are capable of learning to discriminate benign and malicious Windows executables without costly and unreliable feature engineering. This avoids a number of issues with commonly used anti-virus and malware detection systems while achieving higher classification AUC.
A byte-level understanding of programs could have many applications beyond malware classification, such as static performance prediction and automated code generation. But progress towards that goal will require critical thinking about ways to reduce the memory intensity of this problem and about what types of neural network architectural designs may allow us to better capture the multiple modes of information represented in a binary.
We hope that this work encourages the broader machine learning community to explore malware detection as a fruitful area for research due to its unique challenges, such as extremely long sequences and sparse training signal. Deep Learning has enjoyed some spectacular success and advancement thanks to applications in image, signal and natural language processing. Expanding to a radically different domain like malware detection has already helped us better understand some of the aspects of our tooling and learning methods that don’t trivially transfer to new data and problem domains, such as batch normalization. It also gives a further glimpse into how widely applicable neural networks can be.
Please download the paper from Arxiv now and come hear us present this work at the AAAI 2018 Artificial Intelligence for Cyber Security workshop.
References
[Cogswell et al. 2016] Reducing Overfitting in Deep Networks by Decorrelating Representations, Cogswell, M.; Ahmed, F.; Girshick, R.; Zitnick, L.; and Batra, D. (ICLR 2016) https://arxiv.org/abs/1511.06068
[Zhou et al. 2016] Learning Deep Features for Discriminative Localization. Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; and Torralba, A. (CVPR 2016) https://arxiv.org/abs/1512.04150
[Raff et al. 2016] An investigation of byte n-gram features for malware classification. Raff, E.; Zak, R.; Cox, R.; Sylvester, J.; Yacci, P.; Ward, R.; Tracy, A.; McLean, M.; and Nicholas, C. Journal of Computer Virology and Hacking Techniques. 2016
[Raff et al. 2017] Learning the PE Header, Malware Detection with Minimal Domain Knowledge, Raff, E.; Sylvester, J.; and Nicholas, C. arXiv:1709.01471, 2017