NVIDIA cuOpt is a GPU-accelerated optimization engine designed to deliver fast, high-quality solutions for large, complex decision-making problems. Mixed integer programming (MIP) is a technique for solving problems. It can be modeled by a set of linear constraints, with some of the variables able to assume only integer values. The types of problems that can be modeled as MIP are numerous and include areas such as production planning, supply chain, transportation, scheduling, and finance.
NVIDIA cuOpt is a GPU-accelerated solver built to deliver low-latency, high-quality optimization for large, constraint-heavy problems. At its core, cuOpt uses mixed-integer programming (MIP), which formulates decisions as linear constraints with both continuous and integer variables. This makes it well-suited for domains like supply-chain network optimization, routing and dispatch, workforce and task scheduling, production planning, and quantitative finance.
Accelerated primal heuristics for MIP solvers are algorithms that deliver high-quality, feasible solutions without exhaustively searching the entire solution space. They’re needed for two reasons. First, many real-world MIP problems are too large or time-sensitive for traditional solvers to find answers in time. Second, they enable pruning the search space of a Branch and Bound algorithm. Accelerated heuristics reduce solve times by utilizing parallelism and smarter search strategies, enabling businesses to respond to disruptions and make low-latency decisions.
This post explains how NVIDIA cuOpt uses GPU acceleration to deliver high-quality solutions to MIP problems through primal heuristics, enabling the discovery of new solutions for four open instances from the MIPLIB benchmark set: liu.mps, neos-3355120-tarago.mps, polygonpack4-7.mps, and bts4-cta.mps. The demonstrated results showcase substantial improvements in solution quality and the number of feasible solutions compared to leading open-source CPU solvers.
Why fast, high-quality solutions matter for large-scale MIPs
A MIP is part of a class of NP-hard problems, meaning that no known algorithm can solve all such problems quickly in the worst case. However, despite their NP-hardness, commercial MIP solvers routinely deliver optimal solutions for many large instances.
But certain problems remain intractable or require prolonged computation times. Given that MIP models real-world problems and often maps directly to operational costs, it has been a longstanding goal—dating back to the mid-20th century—to develop algorithms capable of efficiently solving increasingly large and complex instances. Significant theoretical and computational breakthroughs have been made since then, including the branch and bound algorithm, cutting planes, primal heuristics like the feasibility pump, and, more recently, parallel processing.
Real-world problems are typically dynamic, with inputs that change over time. This requires solvers to use iterative and incremental approaches, making speed essential at every step. Time-critical MIPs include flexible job-shop scheduling and variants, lot sizing, and airline or railway crew scheduling. Consequently, in cuOpt, significant effort has been dedicated to developing primal heuristics for the discovery of high-quality solutions within a brief timeframe— often faster than any other open-source solver.
How to get high-quality feasible solutions for MIPs
One of the most successful primal heuristics to date is the feasibility pump (FP), with new papers based on the idea emerging every year. The main idea is relatively simple: iterate between projections onto the feasible region and rounding variables that remain fractional using domain propagation.
We started by improving the existing algorithms to maximize GPU performance and address two main bottlenecks of the FP algorithm:
- The projection is modeled as a Linear Programming problem.
- Domain Propagation after the projection
We observed that the precision of the projection in the FP algorithm isn’t that important, as we obtained similar results even with lower precision. This gave us the idea that a first-order method could be used instead of the simplex algorithm, and fortunately, the PDLP(Primal-Dual hybrid gradient) was already implemented in the cuOpt framework.
We warm-start the PDLP algorithm with the primal and dual solutions of the previous projection. Using PDLP in the FP, as well as at the root node, enabled us to iterate much faster and solve larger problems more effectively. To tackle the second bottleneck, we implemented a GPU version of the domain propagation algorithm with significant improvements, such as bulk rounding and dynamic variable ranking. After removing these bottlenecks, our focus shifted to removing cycling within FP.
Cycling is the problem of repeating steps, and is usually solved by introducing randomness to explore different regions of the search space. Instead, we opted for using the Local-MIP algorithm to break the cycle and, at the same time, improve the objective. To do it efficiently, Local-MIP was implemented on the GPU, outperforming the standard CPU version.
We also added the objective cutoff at every iteration and found a new best-feasible solution. We’ve published a paper detailing this.
These improvements led to an advanced primal heuristic for finding feasible solutions. The following table shows a comparison of our method with a recent FP variant and the Local-MIP in terms of the number of feasible solutions (average over 3 runs) and the objective gap (normalized difference between the optimal solution and the one found by our heuristics):
| Method | Avg. # Feasible | Primal gap |
| Fix and propagate portfolio default | 193.8 | 0.66 |
| Local-MIP | 188.67 | 0.46 |
| GPU Local-MIP | 205 | 0.41 |
| GPU Extended FP with nearest rounding | 220 | 0.23 |
| GPU Extended FP with Fix and Propagate | 220.67 | 0.22 |
In addition to these enhancements, we introduced three novel evolutionary algorithms to further refine the model. The evolutionary algorithms, applied upon detection of stagnation, effect an additional 3% reduction in the primal gap. The incorporation of a straightforward Branch and Bound approach (excluding cutting planes) with diving threads and a subMIP-based Evolutionary Algorithm provided an even greater degree of improvement. We now proceed to compare this method with the widely used open-source solvers:
MIP solvers benchmarks
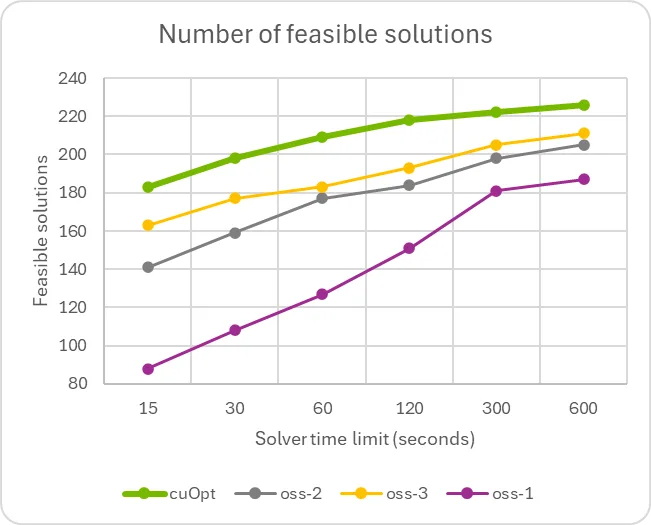
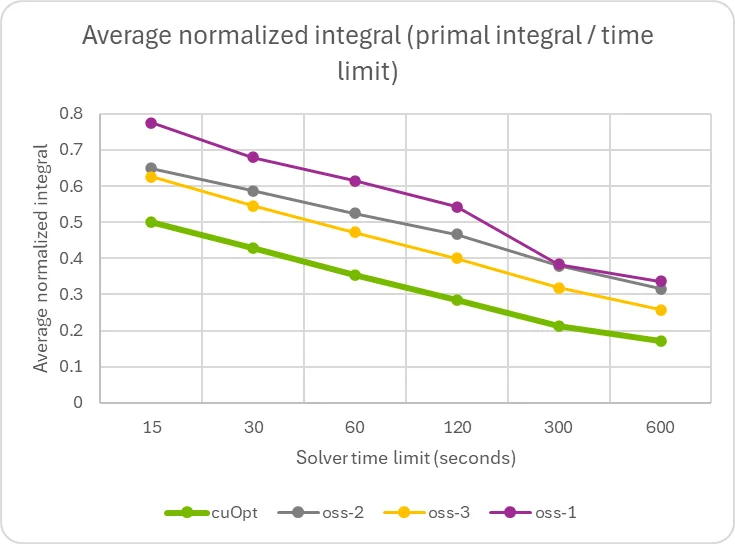
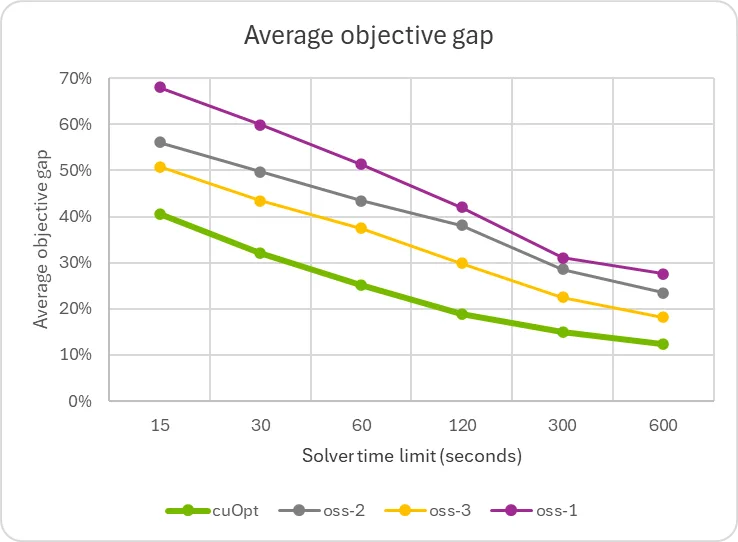
The graphs show a substantial speedup compared to solvers that incorporate sophisticated cutting plane algorithms and problem-specific methodologies. This indicates potential for further improvement, as well as the possibility of augmenting any existing solver with the GPU-accelerated primal heuristics detailed previously.
How GPUs make MIP solving practical
Fast, feasible MIP solving plays a critical role in decision intelligence pipelines. When integrated with systems such as Palantir Ontology and NVIDIA Nemotron reasoning agents, it enables scenario generation and evaluation across many operational models in parallel. The open source GPU-accelerated MIP solver in cuOpt computes feasible solutions within seconds, enabling downstream agents to simulate alternatives and re-optimize plans as conditions change. This capability turns static optimization into a continuous feedback process for supporting adaptive decision making at scale.
Get started with the MIP heuristics solver
MIP heuristics offer fast and feasible solutions without exhaustively exploring the problem space. This enables organizations to quickly test alternatives and respond to real-world disruptions, such as port delays, equipment failures, or sudden demand spikes. NVIDIA cuOpt uses GPU acceleration to make these heuristics practical at scale, producing faster solutions, reducing objective gaps, and enabling continuous, adaptive decision-making pipelines. Explore the NVIDIA cuOpt GitHub to experiment and try out examples of MIP use cases for your optimization problems.