
The evolution of linear programming (LP) solvers has been marked by significant milestones over the past century, from Simplex to the interior point method (IPM). The introduction of primal-dual linear programming (PDLP) has brought another significant advancement.
NVIDIA cuOpt has now implemented PDLP with GPU acceleration. Using cutting-edge algorithms, NVIDIA hardware, dedicated CUDA features, and NVIDIA GPU libraries, the cuOpt LP solver achieves over 5,000x faster performance compared to CPU-based solvers.
This post examines the key components of LP solver algorithms, GPU acceleration in LP, and cuOpt performance on Mittelmann’s benchmark and Min Cost Flow problem instances.
Harnessing cutting-edge innovations for large-scale LP
LP is a method that involves optimizing a linear objective function, subject to a set of linear constraints.
Consider this scenario: A farmer must decide which vegetables to grow and in what quantities to maximize profit, given limitations on land, seeds, and fertilizer. The goal is to determine the optimal revenue while respecting all constraints, as quickly as possible.
NVIDIA developed an LLM agent example that helps model the problem and solve it using an LP solver. LP is an essential tool for optimization and has applications in resource allocation, production planning, supply chain, and, as a backbone for mixed-integer programming (MIP) solvers. Solving mathematical problems with millions of variables and constraints in seconds is challenging, if not impossible, in some cases.
There are three requirements to solve LP problems efficiently on GPUs:
- Efficient and massively parallel algorithms
- NVIDIA GPU libraries and CUDA features
- Cutting-edge NVIDIA GPUs
Efficient and massively parallel algorithms
Simplex, introduced by Dantzig in 1947, remains a core component of most LP and MIP solvers. It works by following the edges of the feasible region to find the optimum.

(Source: Visually Explained – What is Linear Programming (LP)?)
The next major advancement came with the interior point method (IPM), discovered by I. I. Dikin in 1967. IPM, which moves through the interior of the polytope towards the optimum, is now considered state-of-the-art for solving large-scale LPs on CPUs. However, both techniques face limitations in massive parallelization.

(Source: Visually Explained – What is Linear Programming (LP)?)
In 2021, a new groundbreaking technique to solve large LPs was introduced by the Google Research team: PDLP. It is a first-order method (FOM) that uses the derivative of the problem to iteratively optimize the objective and minimize constraint violation.
PDLP enhances primal-dual hybrid gradient (PDHG) algorithm by introducing tools to improve convergence, including a presolver, diagonal preconditioning, adaptive restarting, and dynamic primal-dual step size selection. Presolving and preconditioning make the input problem simpler and improves numerical stability while restarting and dynamic step size computation enables the solver to adapt itself during optimization.
A key advantage of FOM over previous methods is its ease of massive parallelization, making it well-suited for GPU implementation.
PDLP employs two highly parallelizable computational patterns: Map operations and sparse matrix-vector multiplications (SpMV). This approach enables PDLP to efficiently handle millions of variables and constraints in parallel, making it extremely effective on GPUs.
Map is extensively used in PDLP to perform additions, subtractions, and so on for all the variables and constraints that can span millions of elements. It is extremely parallel and efficient on GPUs.
SpMV corresponds to multiplying a sparse matrix (containing many zeros) and a vector. While this matrix size can reach tens of billions, it contains far fewer useful values. For instance, in a vegetable planting problem, a constraint such as, “I can’t plant more than 3.5 kg of potatoes” would contain only one useful value among millions of variables.
SpMV algorithms have been extensively optimized for GPUs, making them orders of magnitude faster than CPU implementations.
NVIDIA GPU libraries and CUDA features
To have the best performance, our GPU PDLP implementation uses cutting-edge CUDA features and the following NVIDIA libraries:
- cuSparse
- Thrust
- RMM
cuSparse is the NVIDIA GPU-accelerated library for sparse linear algebra. It efficiently performs SpMVs, a challenging task on GPUs. cuSparse employs unique algorithms designed to fully leverage the NVIDIA massively parallel architecture.
Thrust is part of the NVIDIA CUDA Core Compute Libraries (CCCL) and provides high-level C++ parallel algorithms. It simplifies the expression of complex algorithms using patterns and iterators for GPU execution. I used Thrust for map operations and the restart process, which entails sorting values by key. This is a task that can be demanding on the GPU but is efficiently optimized by Thrust.
RMM is the fast and flexible NVIDIA memory management system that enables the safe and efficient handling of GPU memory through the use of a memory pool.
Finally, I took advantage of advanced CUDA features. One of the most significant challenges in parallelizing PDLP on GPUs is the restart procedure, which is inherently iterative and not suited for parallel execution. To address this, I used CUDA Cooperative Groups, which enable you to define GPU algorithms at various levels, with the largest being the grid that encompasses all workers. By implementing a cooperative kernel launch and using grid synchronization, you can efficiently and elegantly express the iterative restart procedure on the GPU.
Cutting-edge NVIDIA GPUs
GPUs achieve fast computation by using thousands of threads to solve many problems in parallel. However, before processing, the GPU must first transfer the data from the main memory to its worker threads.
Memory bandwidth refers to the amount of data that can be transferred per second. While CPUs can usually handle hundreds of GB/s, the latest GPU, NVIDIA HGX B100, has a bandwidth of eight TB/s, two orders of magnitude larger.
The performance of this PDLP implementation scales directly with increased memory bandwidth due to its heavy reliance on memory-intensive computational patterns like Map and SpMV. With future NVIDIA GPU bandwidth increases, PDLP will automatically become faster, unlike other CPU-based LP solvers.
cuOpt outperforms state-of-the-art CPU LP solvers on Mittelmann’s benchmark
The industry standard to benchmark the speed of LP solvers is Mittelmann’s benchmark. The objective is to determine the optimal value of the LP function while adhering to the constraints in the shortest time possible. The benchmark problems represent various scenarios and contain between hundreds of thousands to tens of millions of values.
For the comparison, I ran a state-of-the-art CPU LP solver and compared it to this GPU LP solver. I used the same threshold of 10-4 and disabled crossover. For more information, see the Potential for PDLP refinement section later in this post.
Both solvers operated under float64 precision.
- For the CPU LP solver, I used a recommended CPU setup: AMD EPYC 7313P servers with 16 cores and 256 GB of DDR4 memory.
- For the cuOpt LP solver, I used an NVIDIA H100 SXM Tensor Core GPU to benefit from the high bandwidth and ran without presolve.
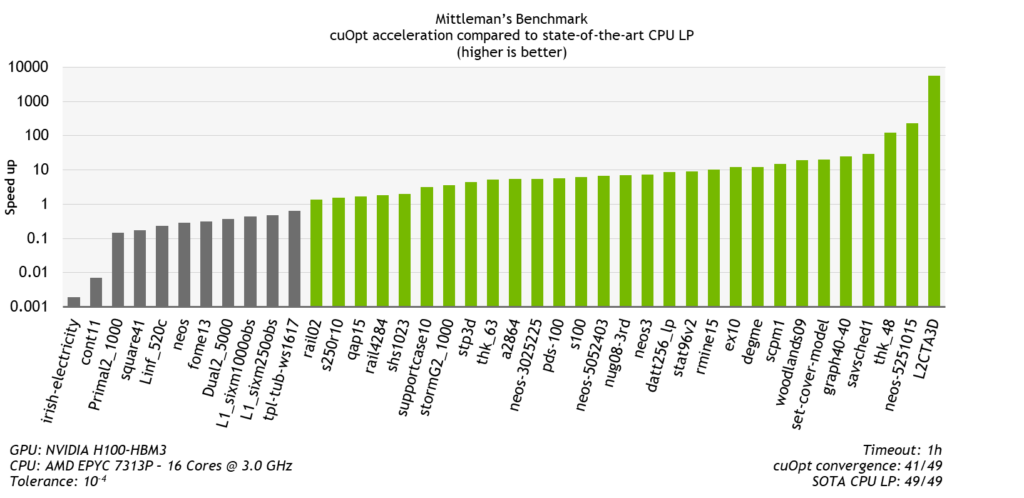
I considered the full solve time without I/O, including scaling for both solvers and presolving for the CPU LP solver. Only instances that have converged for both solvers with a correct objective value are showcased in Figure 4. cuOpt is faster on 60% of the instances and more than 10x faster in 20% of the instances. The biggest speed-up is 5000x on one instance of a large multi-commodity flow optimization problem.
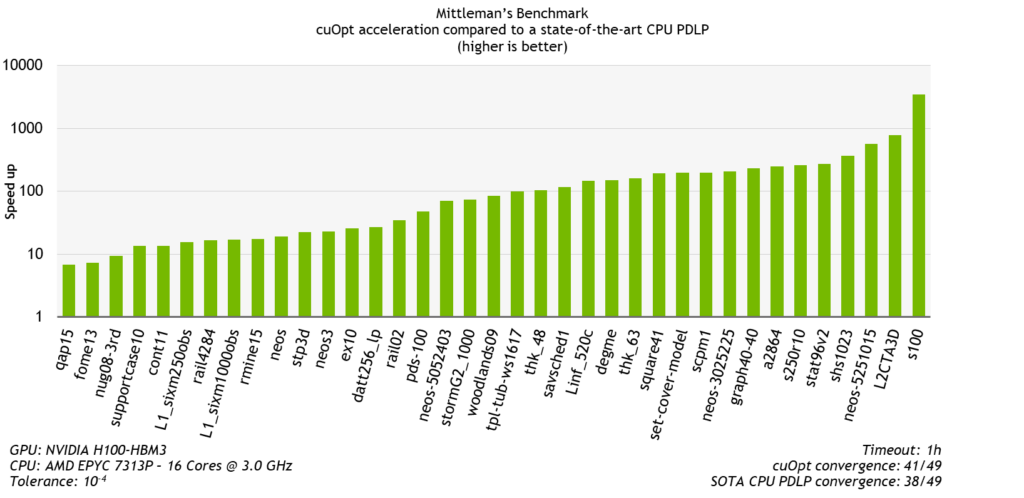
I also compared cuOpt against a state-of-the-art CPU PDLP implementation using the same setup and conditions. cuOpt is consistently faster and between 10x to 3000x faster.
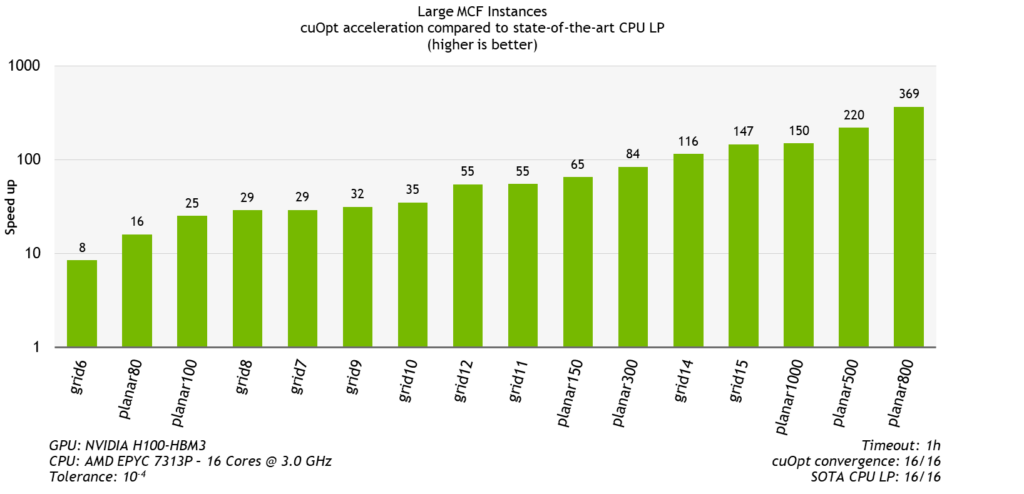
The multi-commodity flow problem (MCF) involves finding the most efficient way to route multiple different types of goods through a network from various starting points to their respective destinations, ensuring that the network’s capacity constraints are not exceeded. One way to solve an MCF problem is to convert it to an LP. On a set of large MCF instances, PDLP is consistently faster, between 10x and 300x.
Potential for PDLP refinement
The NVIDIA cuOpt LP solver delivers incredible performance, but there’s potential for future enhancements:
- Handling higher accuracy
- Requiring high bandwidth
- Convergence issues on some problems
- Limited benefit for small LPs
Handling higher accuracy
To decide whether you’ve solved an LP, you measure two things:
- Optimality gap: Measures how far you are from finding the optimum of the objective function.
- Feasibility: Measures how far you are from respecting the constraints.
An LP is considered solved when both quantities are zero. Reaching an exact value of zero can be challenging and often unnecessary, so LP solvers use a threshold that enables faster convergence while maintaining accuracy. Both quantities are now only required to be below this threshold, which is relative to the magnitude of the values of the problem.
Most LP solvers use a threshold, especially for large problems that are extremely challenging to solve. The industry standard so far was to use 10-8. While PDLP can solve problems using 10-8, it is then usually significantly slower. This can be an issue if you require high accuracy. In practice, many find 10-4 accurate enough and sometimes even lower. This heavily benefits PDLP while not being a big differentiator for other LP-solving algorithms.
Requiring high bandwidth
PDLP’s performance scales linearly with memory bandwidth, making it more efficient on new GPU architectures. It requires a recent server-grade GPU to reproduce the results shown in the performance analysis section.
Convergence issues on some problems
While PDLP can solve most LPs quickly, it sometimes needs a significant number of steps to converge, resulting in higher runtimes. On Mittelmann’s benchmark, cuOpt LP Solver times out after one hour on 8 of the 49 public instances, due to a slow convergence rate.
Limited benefit for small LPs
Small LPs benefit less from the GPU’s high bandwidth, which doesn’t enable PDLP to scale as well compared to CPU solvers. The cuOpt LP solver offers a batch mode for this scenario where you can provide and solve hundreds of small LPs in parallel.
Conclusion
The cuOpt LP solver uses CUDA programming, NVIDIA GPU libraries, and cutting-edge NVIDIA GPUs to solve LPs, potentially orders of magnitude faster than CPU and scaling to over a billion coefficients. As a result, it’s particularly beneficial for tackling large-scale problems, where its advantages become even more prominent.
Some use cases will still work better with traditional Simplex or IPM and I expect the future solvers to be a combination of GPU and CPU techniques.
Sign up to be notified when you can try the cuOpt LP. Try NVIDIA cuOpt Vehicle Routing Problem (VRP) today with NVIDIA-hosted NIM microservices for the latest AI models for free on the NVIDIA API Catalog.
