NVIDIA® GPU Boost™ is a feature available on NVIDIA® GeForce® and Tesla® GPUs that boosts application performance by increasing GPU core and memory clock rates when sufficient power and thermal headroom are available (See the earlier Parallel Forall post about GPU Boost by Mark Harris). In the case of Tesla GPUs, GPU Boost is customized for compute-intensive workloads running on clusters. In this post I describe GPU Boost in more detail and show you how you can take advantage of it in your applications. I also introduce Tesla K80 autoboost and demonstrate that it can automatically match the performance of explicitly controlled application clocks.
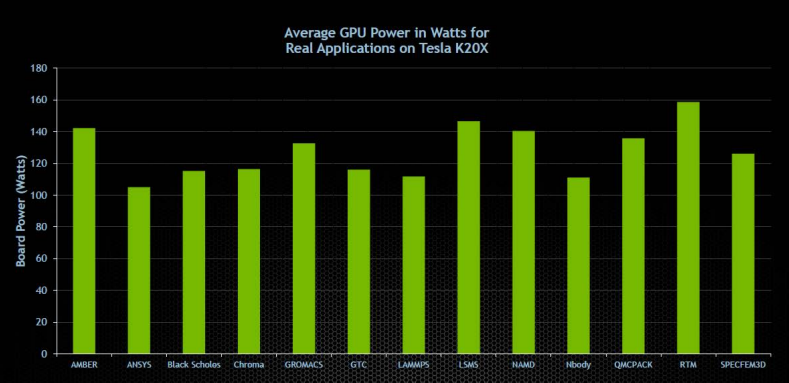
Tesla GPUs target a specific power budget, for example Tesla K40 has a TDP (Thermal Design Power) of 235W and Tesla K80 has a TDP of 300W. These TDP ratings are upper limits, and the graph in Figure 1 shows that many HPC workloads do not come close to this power limit. NVIDIA GPU Boost for Tesla allows users to increase application performance by using available power headroom to select higher graphics clock rates.
NVIDIA GPU Boost is exposed for Tesla accelerators via application clock settings and on the new Tesla K80 accelerator it can also be enabled via the new autoboost feature, which is enabled by default. A user or system administrator can disable autoboost and manually set the right clocks for an application, by either:
- running the command line tool nvidia-smi locally on the node, or
- programmatically using the NVIDIA Management Library (NVML).
Controlling GPU Boost with the NVIDIA System Management Interface
You can use nvidia-smi to control application clocks without any changes to the application.
You can display the current application clock setting by passing the query option (-q) to nvidia-smi. With the -i and the display options (-d) you can filter this view to only show the clock information for a specific GPU.
$ nvidia-smi -q -i 0 -d CLOCK
==============NVSMI LOG==============
[...]
Applications Clocks
Graphics : 745 MHz
Memory : 3004 MHz
Default Applications Clocks
Graphics : 745 MHz
Memory : 3004 MHz
[...]
Before you can change the application clocks you need to put the GPU in Persistence Mode and query the available application clock rates. Persistence mode ensures that the driver stays loaded even when no CUDA or X applications are running on the GPU. This maintains current state, including requested applications clocks.Persistence Mode is necessary to make application clock changes persistent until the application runs. Enable Persistence Mode with the following command line (for GPU 0).
$ sudo nvidia-smi -pm ENABLED -i 0 Enabled persistence mode for GPU 0000:04:00.0. All done.
You can then query the supported application clocks with the display option (-d SUPPORTED_CLOCKS).
$ nvidia-smi -q -i 0 -d SUPPORTED_CLOCKS
==============NVSMI LOG==============
Timestamp : Wed Oct 29 08:31:22 2014
Driver Version : 340.32
Attached GPUs : 6
GPU 0000:04:00.0
Supported Clocks
Memory : 3004 MHz
Graphics : 875 MHz
Graphics : 810 MHz
Graphics : 745 MHz
Graphics : 666 MHz
Memory : 324 MHz
Graphics : 324 MHz
Please note that the supported graphics clock rates are tied to a specific memory clock rate so when setting application clocks you must set both the memory clock and the graphics clock. Do this using the -ac command line option.
$ sudo nvidia-smi -ac 3004,875 -i 0 Applications clocks set to "(MEM 3004, SM 875)" for GPU 0000:04:00.0 All done.
Resetting the default is possible with the -rac (“reset application clocks) option.
$ sudo nvidia-smi -rac -i 0 All done.
To avoid trouble in multi-user environments, changing application clocks requires administrative privileges. However, a system administrator can relax this requirement to allow non-admin users to change application clocks by setting the application clock permissions to UNRESTRICTED using the -acp (“application clock permissions”) option to nvidia-smi.
sudo nvidia-smi -acp UNRESTRICTED -i 0 Applications clocks commands have been set to UNRESTRICTED for GPU 0000:04:00.0 All done.
Please be aware that the application clocks setting is a recommendation. If the GPU cannot safely run at the selected clocks, for example due to thermal or power reasons, it will dynamically lower the clocks. You can query whether this has happened with nvidia-smi -q -i 0 -d PERFORMANCE. This behavior ensures that you always get correct results even if the application clocks are set too high.
Controlling GPU Boost with the NVIDIA Management Library
The NVIDIA Management Library (NVML) is a C-based API for monitoring and managing various states of NVIDIA GPU devices. NVML is primarily used by cluster management tools to manage NVIDIA® Tesla® GPUs, but it can be also used directly from GPU-accelerated applications. This is interesting because end users of GPU-accelerated applications may not be aware of GPU Boost™ and they may not know the optimal settings for execution of applications. With NVML a GPU-accelerated application can set application clocks to the optimal value without requiring the user run nvidia-smi to set them before starting the application. The NVML runtime ships with the CUDA driver and you can download the NVML SDK as part of the NVIDIA GPU Deployment Kit (GDK).
An application can use the full NVML API to interact with the installed GPUs. Let’s step through an example program that uses NVML to control application clocks.
Compiling and Linking
To use the NVML API the application needs to include the NVML header (#include <nvml.h>) and link to the NVML runtime library (nvidia-ml on Linux and nvml on Windows).
nvcc -I$(GPU_DEPLOYMENT_KIT_ROOT_DIR)/include/nvidia/gdk -lnvidia-ml ...
Initializing NVML
Before making any NVML calls need to initialize it using nvmlInit().
nvmlReturn_t nvmlError = nvmlInit();
if (NVML_SUCCESS != nvmlError )
fprintf (stderr, "NVML_ERROR: %s (%d) \n",
nvmlErrorString( nvmlError ), nvmlError);
You should always check error codes, but for simplicity we omit error checking code in the remainder of this post. NVML is thread-safe and initialization is reference counted so it’s safe to call nvmlInit and nvmlShutdown multiple times as long as there is a nvmlShutdown() call for each call to nvmlInit().
Obtaining a NVML device handle from PCI-E identifiers
Before we can make queries or change any GPU state we need an NVML device handle. Since the numbering of NVML devices can be different than the numbering of CUDA devices (for example due to a non-default CUDA_VISIBLE_DEVICES environment variable), we need to search for the NVML devices matching the the PCIe information for the active CUDA device.
//0. Get active CUDA device
int activeCUDAdevice = 0;
cudaGetDevice ( &activeCUDAdevice );
//1. Get device properties of active CUDA device
cudaDeviceProp activeCUDAdeviceProp;
cudaGetDeviceProperties ( &activeCUDAdeviceProp, activeCUDAdevice );
//2. Get number of NVML devices
unsigned int nvmlDeviceCount = 0;
nvmlDeviceGetCount ( &nvmlDeviceCount );
nvmlDevice_t nvmlDeviceId;
//3. Loop over all NVML devices
for ( unsigned int nvmlDeviceIdx = 0;
nvmlDeviceIdx < nvmlDeviceCount;
++nvmlDeviceIdx )
{
//4. Obtain NVML device Id
nvmlDeviceGetHandleByIndex ( nvmlDeviceIdx, nvmlDeviceId );
//5. Query PCIe Info of the NVML device
nvmlPciInfo_t nvmPCIInfo;
nvmlDeviceGetPciInfo ( *nvmlDeviceId, &nvmPCIInfo );
//6. Compare NVML device PCI-E info with CUDA device properties
if ( static_cast<unsigned int>(activeCUDAdeviceProp.pciBusID)
== nvmPCIInfo.bus &&
static_cast<unsigned int>(activeCUDAdeviceProp.pciDeviceID)
== nvmPCIInfo.device &&
static_cast<unsigned int>(activeCUDAdeviceProp.pciDomainID)
== nvmPCIInfo.domain )
break;
}
Controlling Application Clocks with NVML
Now that we have a nvmlDeviceId we can query the GPU status.
//Query current application clock setting
unsigned int appSMclock = 0;
unsigned int appMemclock = 0;
nvmlDeviceGetApplicationsClock ( nvmlDeviceId,
NVML_CLOCK_SM,
&appSMclock );
nvmlDeviceGetApplicationsClock ( nvmlDeviceId,
NVML_CLOCK_MEM,
&appMemclock );
//Query maximum application clock setting
unsigned int maxSMclock = 0;
unsigned int maxMemclock = 0;
nvmlDeviceGetMaxClockInfo ( nvmlDeviceId,
NVML_CLOCK_SM,
&maxSMclock );
nvmlDeviceGetMaxClockInfo ( nvmlDeviceId,
NVML_CLOCK_MEM,
&maxMemclock );
Before attempting to change the application clocks we should check the application clock permissions.
nvmlEnableState_t isRestricted;
nvmlDeviceGetAPIRestriction ( nvmlDeviceId,
NVML_RESTRICTED_API_SET_APPLICATION_CLOCKS,
&isRestricted );
If the application clock permissions allow non-admin users (or applications) to change the application clocks, then we can go ahead and change them.
if ( NVML_FEATURE_DISABLED == isRestricted )
{
nvmlDeviceSetApplicationsClocks ( nvmlDeviceId,
maxMemclock ,
maxSMclock );
}
This example only covers how to query the maximum supported application clocks. With nvmlDeviceGetSupportedGraphicsClocks and nvmlDeviceGetSupportedMemoryClocks you can query all supported application clock rates, which gives you finer-grain control. The example given below actually uses nvmlDeviceGetSupportedGraphicsClocks. Also please remember that the application clocks setting is a recommendation. You can query if the GPU could not run with the specified application clocks by calling nvmlDeviceGetCurrentClocksThrottleReasons.
Shutting down NVML
Its always nice to clean up after yourself so reset the application clocks (if they have been changed) before shutting down NVML.
nvmlDeviceResetApplicationsClocks ( nvmlDeviceId ); nvmlShutdown();
NVML Example Performance Results
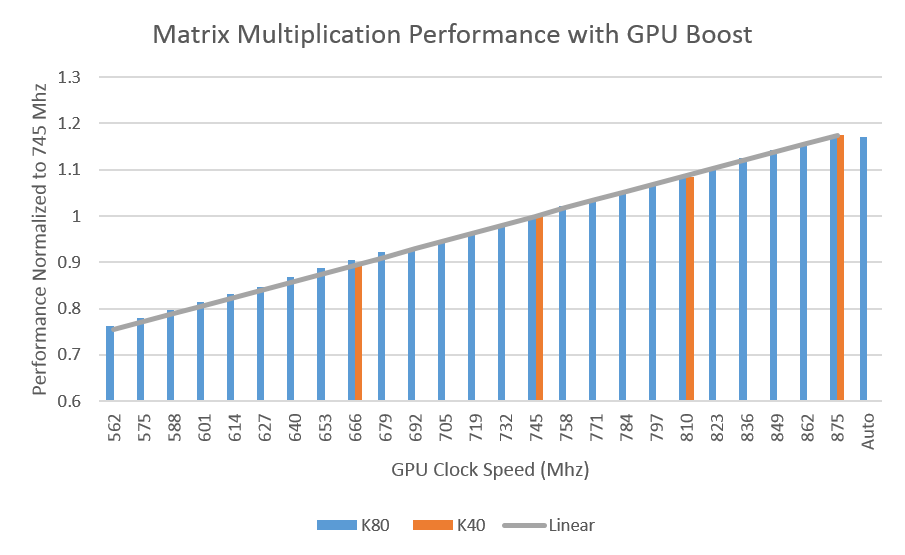
I started with the Matrix Multiplication example from the CUDA Code Samples and used NVML to execute the Matrix Multiplication with different application clocks. Complete source code for this modified example can be found in the Parallel Forall Github repository. Besides this the GDK also contains an example which can be found at usr/src/gdk/nvml/examples within your GDK installation. Figure 1 plots the performance of the example on Tesla K40 and Tesla K80, normalized to the performance of each GPU at the Tesla K40 base clock rate of 745 Mhz. For both GPUs increasing the clocks leads to a linear performance increase for this kernel.
Tesla K80 and Autoboost
As shown in Figure 2 above the Tesla K80 significantly extends the available set of application clocks from 4 levels to 25 levels. This gives more flexibility in choosing the best clocks for a given application. K80 also introduces autoboost, which automatically selects the highest possible clock rate allowed by the thermal and power budget as visualized in Figure 3 below. With autoboost for the matrix multiplication example the highest performance can be achieved as shown in In Figure 2 above. Figure 2 shows that Tesla K80 autoboost is able to achieve the highest performance for our matrix multiplication example (the same as K80’s maximum application clock setting).
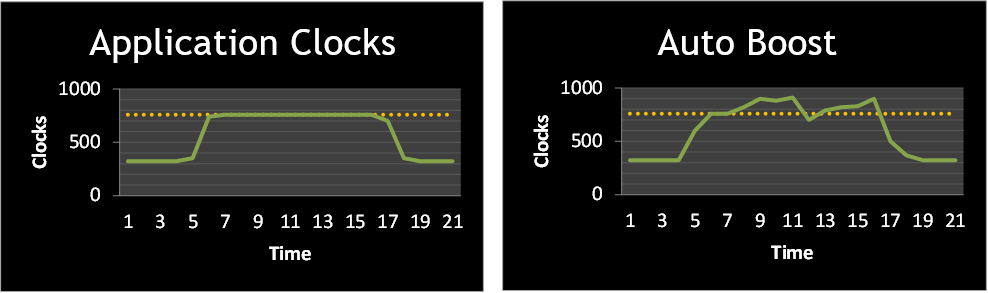
Figure 4 plots the performance across varying GPU clocks of the Molecular Dynamics package GROMACS v5.0.2 for a water box with 96k atoms using PME electrostatics on Telsa K40 and Tesla K80. Performance of K80 with autoboost enabled is shown on the far right of the plots. As you can see Auto Boost delivers the best performance for Tesla K80 and with a Tesla K80 the simulation runs up to 1.9x faster than with a Tesla K40 running at default clocks and up to 1.5x faster when compared to the Tesla K40 running at 875 Mhz ([1]). To demonstrate the impact of GPU Boost in isolation these benchmarks have been run with the latest release of GROMACS which does not have any special tuning for Tesla K80. Tesla K80 specific optimization making use of the larger register file will be available with the next GROMACS release.
![GROMACS Performance with GPU Boost for Tesla K40 and Tesla K80 ([1])](https://developer.nvidia.com/blog/parallelforall/wp-content/uploads/2014/10/GROMACS_vs_app_clocks.png)
Since the autoboost feature of the Tesla K80 allows the GPU to automatically control its clocks one might think that this renders application clocks unnecessary. However, application clocks are still necessary to avoid load balancing issues in large cluster installations running multi-node, multi-GPU applications.
The autoboost feature is enabled by default. In case it has been disabled it can be enabled with nvidia-smi by changing the default setting.
sudo nvidia-smi --auto-boost-default=ENABLED -i 0
As with application clocks, this setting requires administrative priveleges, and the GPU should have Persistence Mode enabled. Autoboost permissions can be relaxed similarly to application clock permissions.
sudo nvidia-smi --auto-boost-permission=UNRESTRICTED -i 0
Independent of the global default setting the autoboost behavior can be overridden by setting the environment variable CUDA_AUTO_BOOST to 0 (to disable) or 1 (to enable) or via NVML for the calling process with nvmlDeviceSetAutoBoostedClocksEnabled.
Conclusion
NVIDIA GPU Boost and especially the Automatic Boost feature introduced with the new Tesla K80 accelerator is an easy path to enable more performance. Using NVML your CUDA application can choose the best GPU Boost setting without any user intervention. Even when the applications clocks permission setting prevents your app from changing the application clocks, NVML can help you inform application users about this so they can consult with their system administrator to enable GPU Boost. To achieve exactly this the popular GPU-accelerated Molecular Dynamic application GROMACS will use NVML in its next release to control GPUBoost on NVIDIA® Tesla® accelerators.
Try out GPU Boost and the NVIDIA Management Library (NVML) in your application today!
[1] GROMACS 5.0.2 was built with GCC 4.8.2, CUDA 6.5. The benchmarks have been executed on a Dual Socket Intel® Xeon® E5-2690 v2 @ 3.00GHz (HT on) running the CUDA Driver version 340.34.