Deepgram, an NVIDIA Inception startup developing automatic speech recognition (ASR) deep learning models, recently published a new demo that highlights the speed and scalability of its platform on NVIDIA GPUs.
“We’ve reinvented Automatic Speech Recognition (ASR) with a complete, deep learning model that allows companies to get faster, more accurate transcription, resulting in more reliable data sets,” the company says.
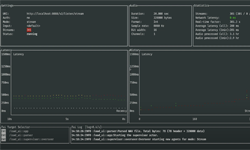
In the new demo, the team uses NVIDIA V100 GPUs on the Amazon Web Services cloud to transcribe hundreds of audio files in seconds.
‘This is all possible because Deepgram is making extremely efficient usage of the massively parallel computing power of the GPU,” said Jacob Visovatti, a solutions engineer at Deepgram.
In total, the team processed over 212 files, around 10 hours of audio, in just 40 seconds.
In the video, Visovatti shows how Deepgram supports the transcription of multiple simultaneous real-time streams on a single GPU. He says that if their model were running on a CPU, only a single stream would be possible at a time.
When tested with 300 simultaneous audio streams, Deepgram can transcribe all the streams at 300 milliseconds, on a single NVIDIA V100 GPU running on the cloud.