
Antibodies have become the most prevalent class of therapeutics, primarily due to their ability to target specific antigens, enabling them to treat a wide range of diseases, from cancer to autoimmune disorders. Their specificity reduces the likelihood of off-target effects, making them safer and often more effective than small-molecule drugs for complex conditions.
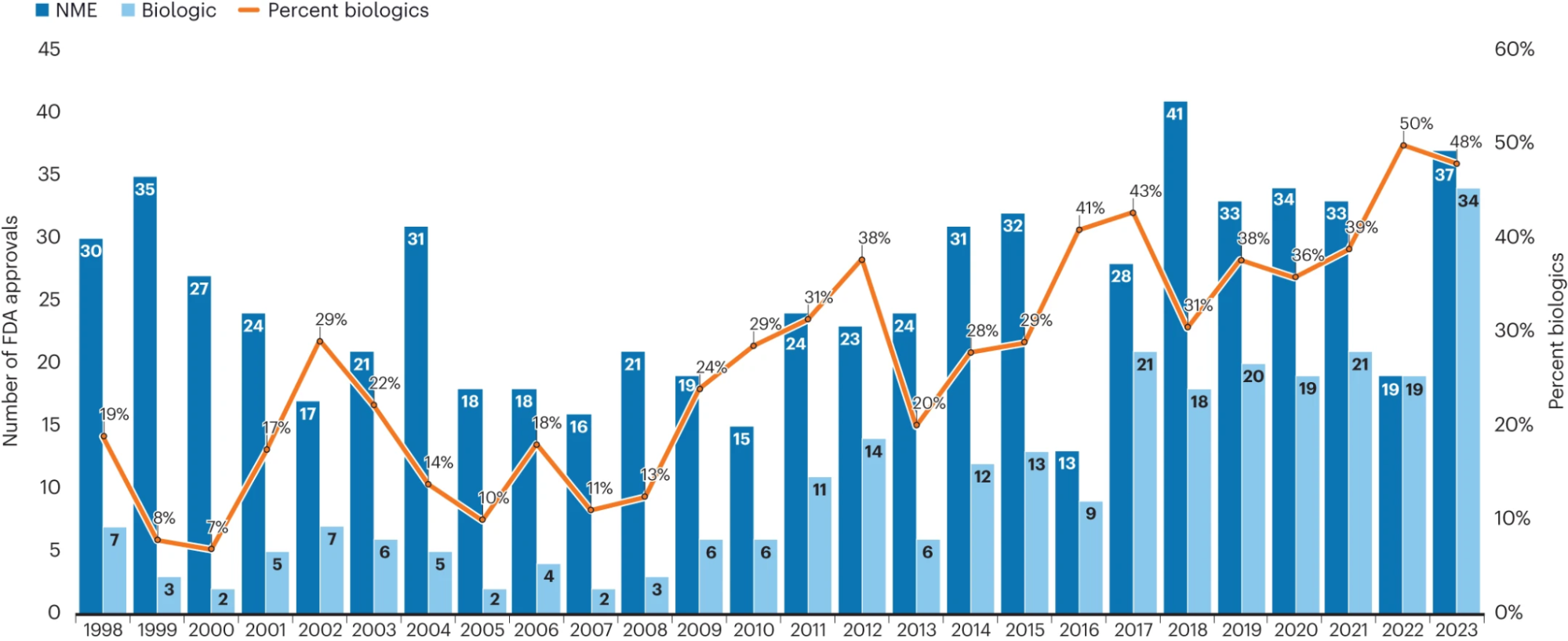
As a result, monoclonal antibodies (mAbs) are frequently at the forefront of biologic drug approvals. Data from the U.S. Food and Drug Administration (FDA) highlights this trend. Between 2018 and 2023, the agency approved nearly 30 mAbs annually, with antibody-based therapies representing about half of all new biologic drug approvals (Figure 1).This increase reflects a broader shift within the biopharma industry towards biologics.
Challenges with modeling antibodies
Despite their prevalence, antibodies are difficult to model using protein structure prediction models. Unlike most proteins, antibodies are built to recognize and bind to a wide range of targets through highly variable regions, known as complementarity-determining regions (CDRs). These CDRs allow antibodies to respond to countless pathogens, but their structural diversity makes them difficult to predict accurately using current models.
Models like AlphaFold, though groundbreaking for general protein folding, are optimized for proteins with relatively stable and conserved structures. Antibodies, on the other hand, are highly flexible, with CDRs that shift in shape and binding orientation depending on the specific target. This flexibility is essential for their function but makes structural predictions more complex.
Research shows that antibody models must capture a range of possible conformations to reflect their biological behavior accurately, not just a single structure.
How A-Alpha Bio is solving it
A-Alpha Bio, a biotechnology company based in Seattle, recently published a study in collaboration with the NVIDIA solutions team: AlphaBind, a Domain-Specific Model to Predict and Optimize Antibody-Antigen Binding Affinity. The study describes the development of AlphaBind—a domain-specific, deep-learning model that achieves high-performance prediction and optimization of antibody-antigen binding affinity.
Data generation and model training
AlphaBind combines high-throughput experimental data and machine-learning techniques for its model training. Large-scale affinity datasets were generated using yeast display libraries and next-generation sequencing, using A-Alpha’s AlphaSeq platform. This process provided quantitative measurements of antibody-antigen binding strengths, which were necessary for model training.
The AlphaBind model architecture is built around ESM-2nv embeddings of antibody and target sequences as inputs. These inputs are then processed by a transformer network consisting of four attention heads and seven layers to predict binding affinity.
Before fine-tuning, AlphaBind was pretrained on approximately 5M rows of AlphaSeq data from unrelated antibody-antigen systems, enabling the model to use transfer learning. The model was then fine-tuned on specific datasets tailored to the parental antibodies being optimized.

Sequence optimization and candidate selection
AlphaBind employs a stochastic greedy optimization approach to improve antibody binding affinity. A total of 60K optimization trajectories were run over 100 generations, proposing mutations and retaining those that resulted in improved predicted affinity.
The optimized sequences were then grouped based on their edit distance from the parental antibody, with 2 to 11 mutations per group.
To ensure feasibility in development down the line, the top candidates were screened using Therapeutic Antibody Profiler (TAP), which filters out sequences with potential developability issues. From this pool, 7.5K candidates were selected for experimental validation, with five top candidates chosen for further testing using biolayer interferometry (BLI).
Experimental validation
The 7.5K selected candidates underwent high-throughput affinity measurements using the AlphaSeq assay, providing a preliminary validation of the predicted binding affinities. The top five candidates, along with parental controls, were then expressed and tested using BLI to confirm any affinity improvements.
AlphaBind, powered by NVIDIA and AWS technology
AlphaBind integrates technologies from NVIDIA and AWS to optimize its performance.
From NVIDIA, it uses ESM-2nv embeddings through the BioNeMo framework and performs training and inference on NVIDIA H100 GPUs.
On Amazon EC2, it employs p5.48xlarge instances with eight H100 GPUs for model training and optimization. NVIDIA GPU-optimized AI models on the BioNeMo framework, combined with AWS’s scalable cloud infrastructure, enable the rapid training and deployment of AlphaBind.
AlphaBind is also made available on AWS HealthOmics, a managed AWS service that enables scalable orchestration of complicated workflows. AWS has published a comprehensive list of protein design examples on Drug Discovery Workflows that can be easily accessed and reused by other biologics discovery researchers.
Results
AlphaBind demonstrated impressive performance across the following diverse antibody optimization campaigns:
- Generated thousands of high-affinity candidates for each parental antibody.
- 100% of BLI-validated candidates showed improved binding compared to parental antibodies.
- Maintained high sequence diversity among optimized candidates, enabling downstream selection based on other properties.
The model’s effectiveness was consistent across different types of antibodies and even when using alternative fine-tuning data sources.
Towards creating a foundation model for antibodies
Although pretraining improves AlphaBind’s ability to fine-tune on specific datasets, it still doesn’t fully adapt to all types of binding interactions. To create a truly generalized model that can predict antibody sequences without needing local fine-tuning, much larger and more diverse datasets are needed.
These datasets should cover a broader range of antibody-antigen structures, and further pretraining will be required. In the future, advancements in data collection, federation, and deep learning will be key to achieving zero-shot antibody engineering.
This approach would enable therapeutic antibodies to be designed entirely through computer-aided methods, reducing the need for cumbersome experimental work. It could also make biologics development faster, more affordable, and more accessible.
By using NVIDIA’s continually advancing AI models and GPUs and AWS’ evolving cloud capabilities, models like AlphaBind will continue to be optimized for biologics discovery.
For more information, see the following resources: