Fast Fourier Transforms (FFTs) are widely used across scientific computing, from molecular dynamics and signal processing to computational fluid dynamics (CFD), wireless multimedia, and machine-learning applications. As computational problem sizes scale to increasingly large domains, researchers require the capability to distribute FFT computations across hundreds or thousands of GPUs spanning multiple nodes.
NVIDIA cuFFTMp is a multi-GPU, multi-node (MGMN) extension to cuFFT that enables scientists and engineers to solve challenging problems on exascale platforms. Building on the success of NVIDIA cuFFTMp’s scaling on Volta and Ampere supercomputers, as detailed in a previous blog, we continue to demonstrate the library’s robust scaling capabilities across the latest NVIDIA GPU architectures.
This blog will present new performance results for MGMN FFTs across cutting-edge cluster configurations. It showcases cuFFTMp’s ability to leverage the full potential of modern MGMN supercomputers.
How cuFFTMp performs and scales on NVIDIA Hopper Platforms
We benchmarked cuFFTMp on the NVIDIA Eos supercomputer and compared results against the Selene supercomputer from our previous blog. Eos is built with NVIDIA DGX H100 systems, where each node contains two Intel Xeon Platinum 8480C 56-core CPUs and eight H100s connected by an NVLink 4 Switch (900 GB/s, bidirectional). All nodes are interconnected by NVIDIA Quantum-2 InfiniBand (400 Gb/s/node, bidirectional).
In comparison to the networking hardware in Selene, Eos has 1.5x faster NVLink and 2x faster InfiniBand in terms of bandwidth. This comparison is particularly valuable as both systems represent state-of-the-art configurations from consecutive GPU generations, allowing us to quantify the real-world performance improvements that researchers can expect when upgrading their infrastructure from Ampere to Hopper platforms.
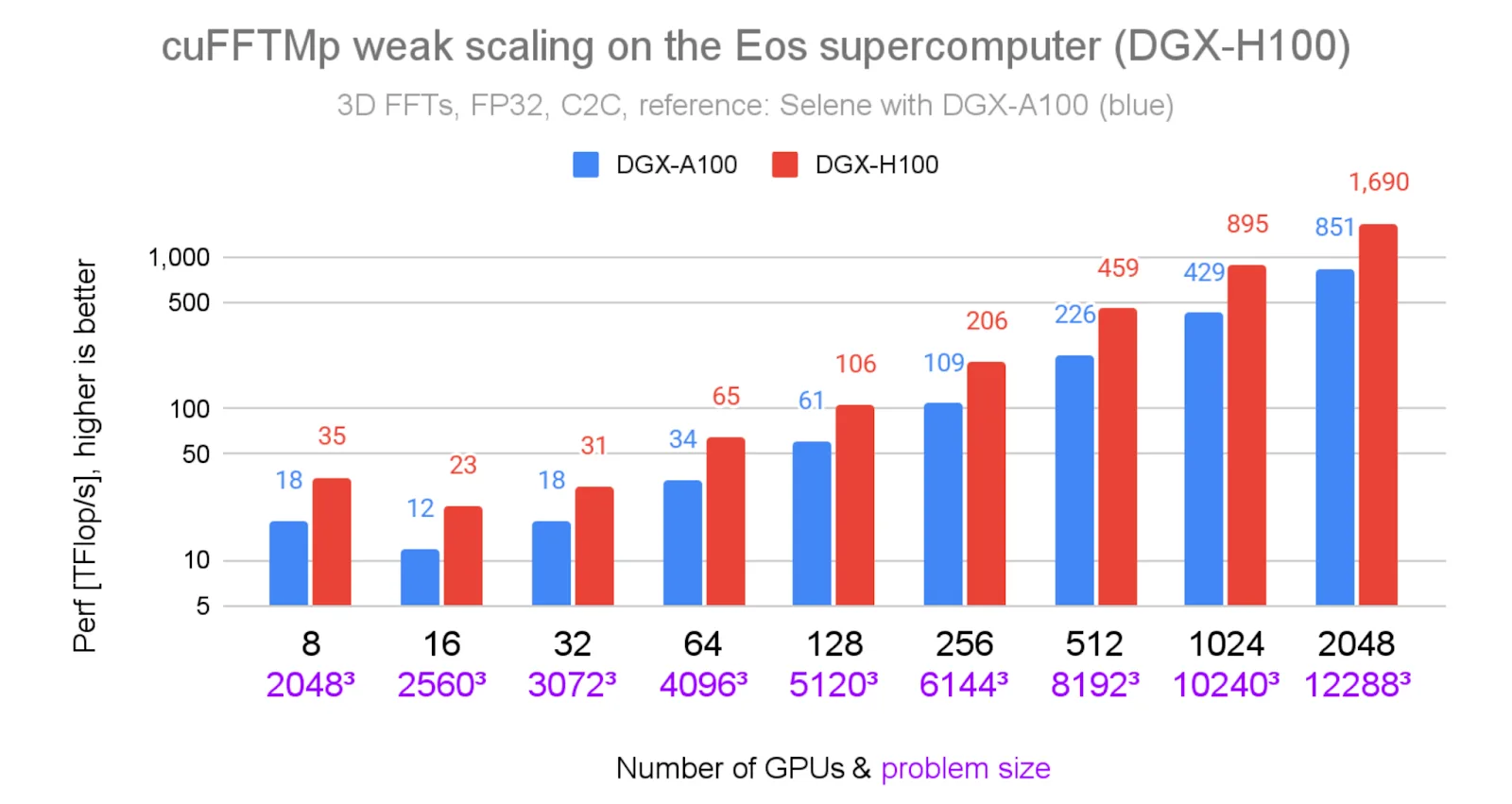
Figure 1 above demonstrates cuFFTMp’s robust weak scaling across different problem sizes on the NVIDIA Eos supercomputer. And Figure 2 below shows the relative speedup of results of Eos over those on Selene. At every GPU count, cuFFTMp consistently achieves approximately 2x speedup (up to 2.09x) and reaches 1.69 PFlop/s at 2048 GPUs.
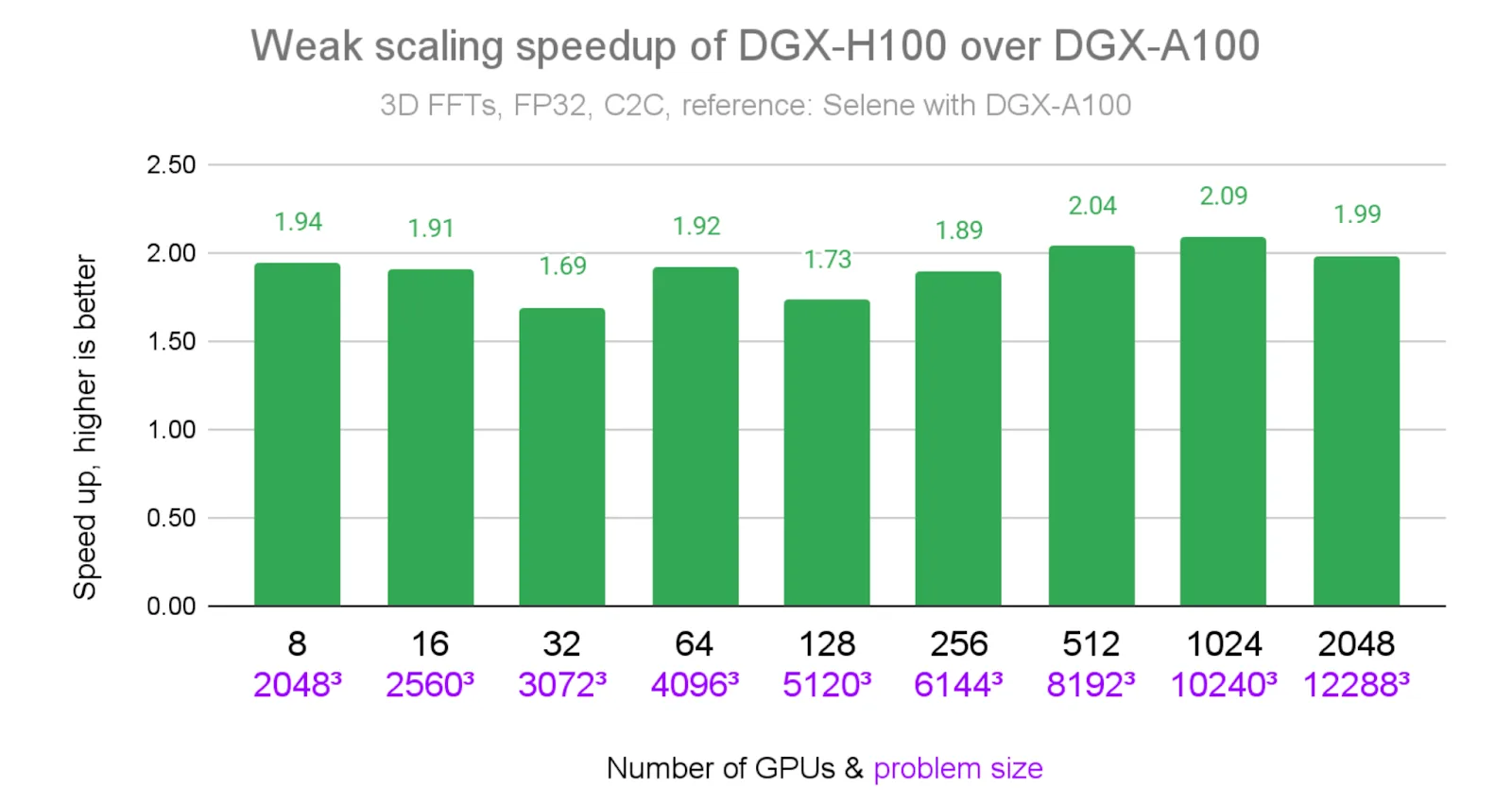
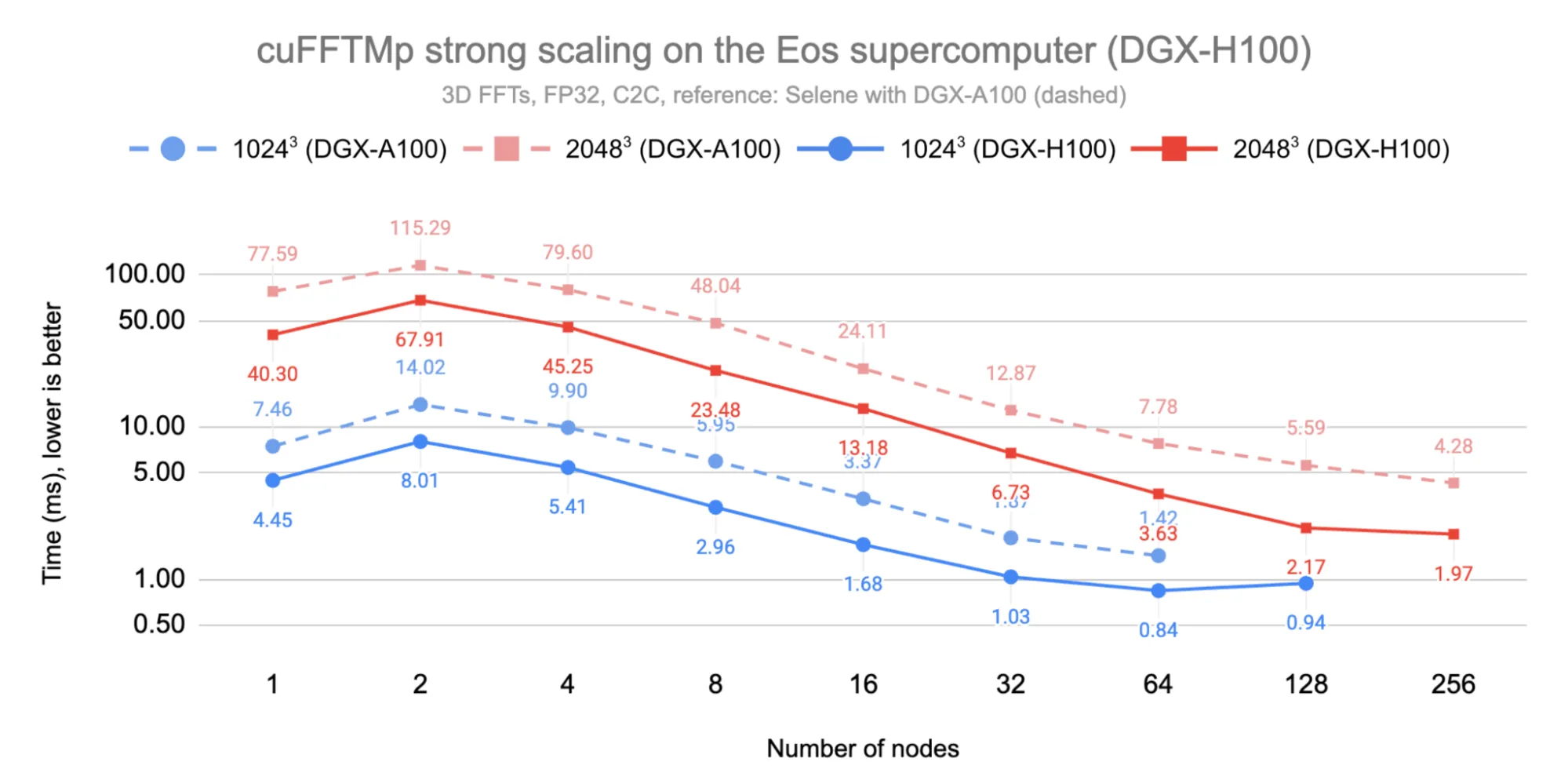
Figure 3 below shows strong scaling of cuFFTMp for two problem sizes, 1,024³ and 2,048³. We observed a performance transition from a single node (eight GPUs) to two nodes (16 GPUs) due to the reduced peak bandwidth of InfiniBand when compared to NVLink. This is then followed by linear scaling up to 256 nodes (2,048 GPUs). The performance begins to plateau beyond 64 nodes and 128 nodes, respectively.
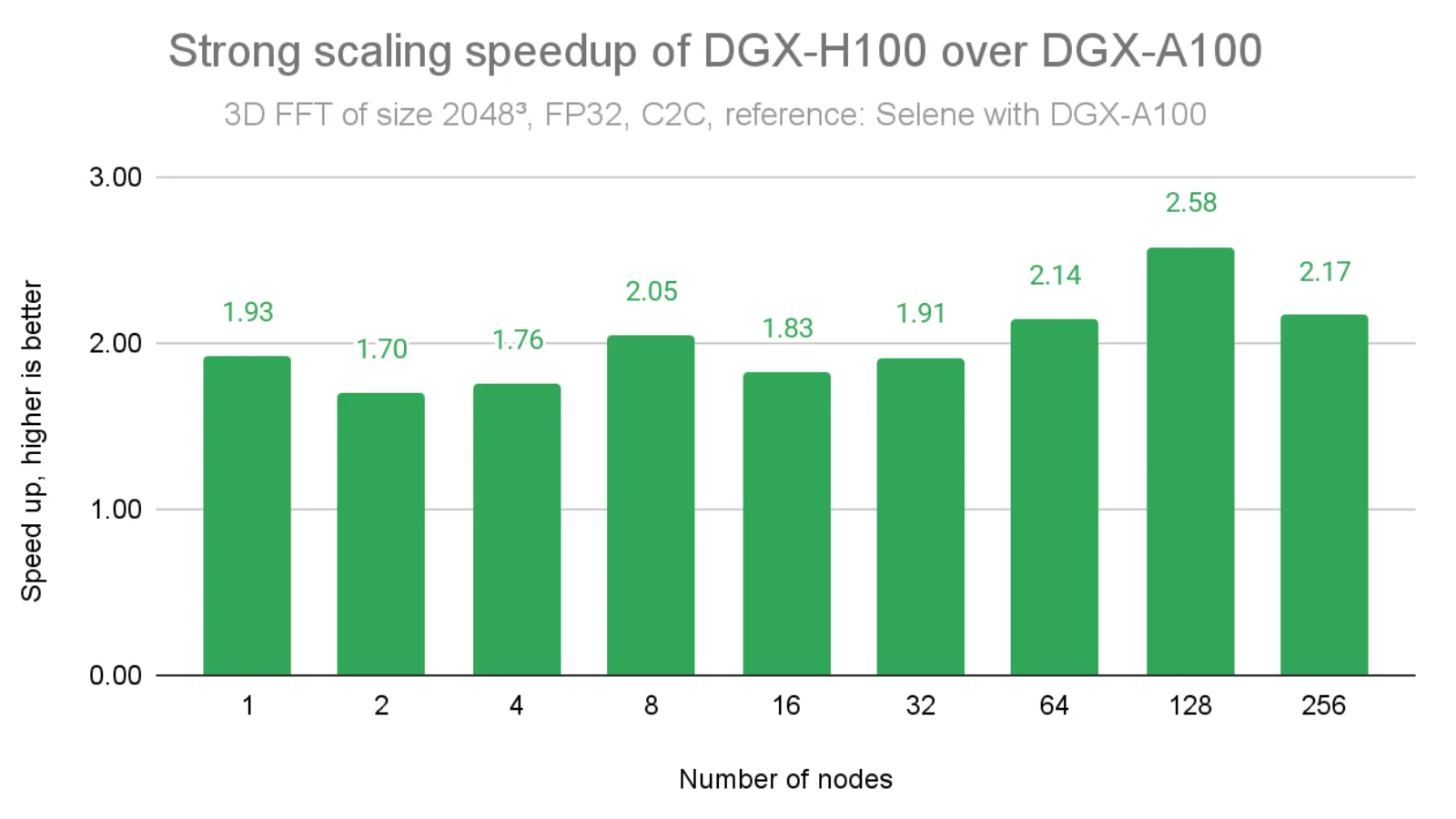
As shown in Figure 4 below, compared with DGX A100 results on problem size 2,048³, we obtain approximately 2x speedup when InfiniBand bandwidth is improved by 2x. In some cases, we achieve speedups exceeding 2x (e.g., 2.58x at 128 nodes) because of cuFFTMp’s state-of-the-art fused kernel implementations that address performance gaps identified in previous iterations.
How cuFFTMp performs and scales on NVIDIA Blackwell platforms
NVIDIA’s Blackwell architecture introduces significant improvements in interconnect bandwidth. Importantly, Blackwell introduces Multi-Node NVLink (MNNVL) technology which extends high-bandwidth NVLink connectivity across multiple nodes within a rack. cuFFTMp leverages the underlying hardware topology and network characteristics to achieve optimal performance.
Figure 5 below demonstrates the results for 1,024³ FFTs on the latest NVIDIA Blackwell systems. The NVIDIA DGX B200 system consists of eight fully connected B200 GPUs with fifth-generation NVLink and NVLink Switch providing 2x the bandwidth of the previous generation (1.8 TB/s/GPU, bidirectional). The NVIDIA GB200 NVL72 system is the new MNNVL rack-scale system that consists of two 72-core Grace CPUs and four Blackwell GPUs per node, and 18 nodes per rack. GPUs in the same rack are interconnected by NVLink 5 Switches at peak bandwidth. For both systems, different racks are connected by NVIDIA Quantum-2 InfiniBand (400 Gb/s/node, bidirectional).
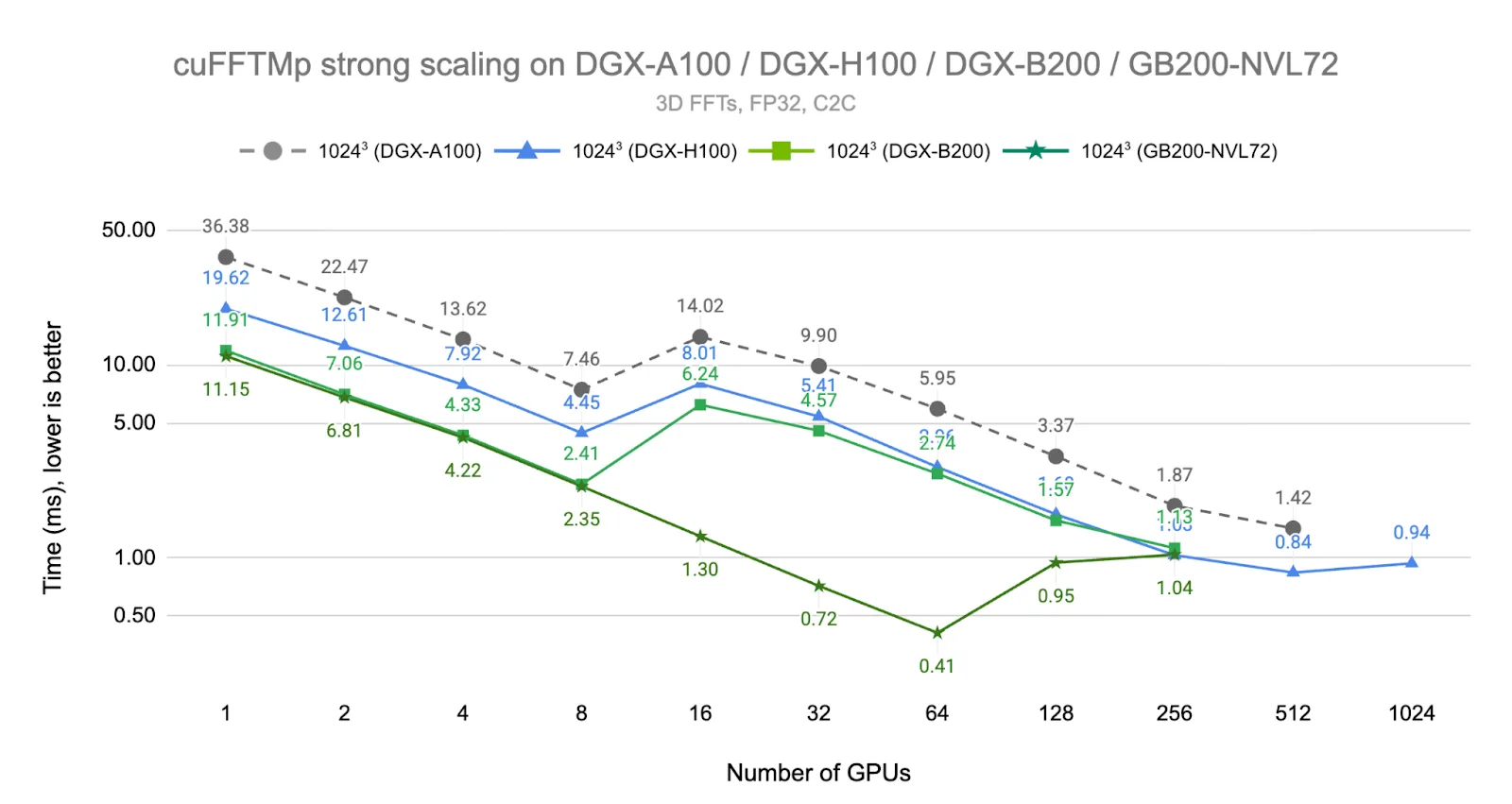
We first observe approximately 3.1x speedup from Ampere to Blackwell systems on up to eight GPUs (1.7x from Hopper to Blackwell). For DGX B200 systems, the same performance transition at 16 GPUs observed in DGX H100 systems occurs because we hit the peak bandwidth of InfiniBand. However, GB200 NVL72 demonstrates consistent linear scaling up to 64 GPUs since all 64 GPUs remain within the same NVLink domain with peak NVLink bandwidth.
Notably, the execution time achieved by NVIDIA GB200 NVL72 at 64 GPUs cannot be attained even by 1,024 H100 GPUs due to accumulated communication latency overhead, demonstrating the fundamental architectural advantage of MNNVL for latency-sensitive workloads. At 128 GPUs, performance becomes a function of the InfiniBand connections between different racks of the NVIDIA GB200 NVL72. Across all benchmarks, performance in InfiniBand scale-out connected regimes converges, albeit at different GPU counts, as all InfiniBand connections share the same bandwidth characteristics.
How GROMACS uses cuFFTMp for biomolecular simulations
GROMACS, a scientific software package widely used for simulating biomolecular systems, plays a crucial role in comprehending biological processes important for disease prevention and treatment. In a previous blog we described how integration of cuFFTMp into GROMACS allowed huge scalability improvements. We now showcase a further breakthrough by running this software on the new Grace-Blackwell MNNVL architecture.
We benchmarked the 5.9 million atom “PRS2” test case, an important system for novel research into synaptic vesicle fusion simulations: These reveal how key proteins involved in neurotransmitter release allow key structures in neurotransmitters to fuse with plasma membranes, a critical step in nerve cell communication. We also include the larger 12.4 million atom “benchPEP-h” case, to allow direct comparison with the previous blog.
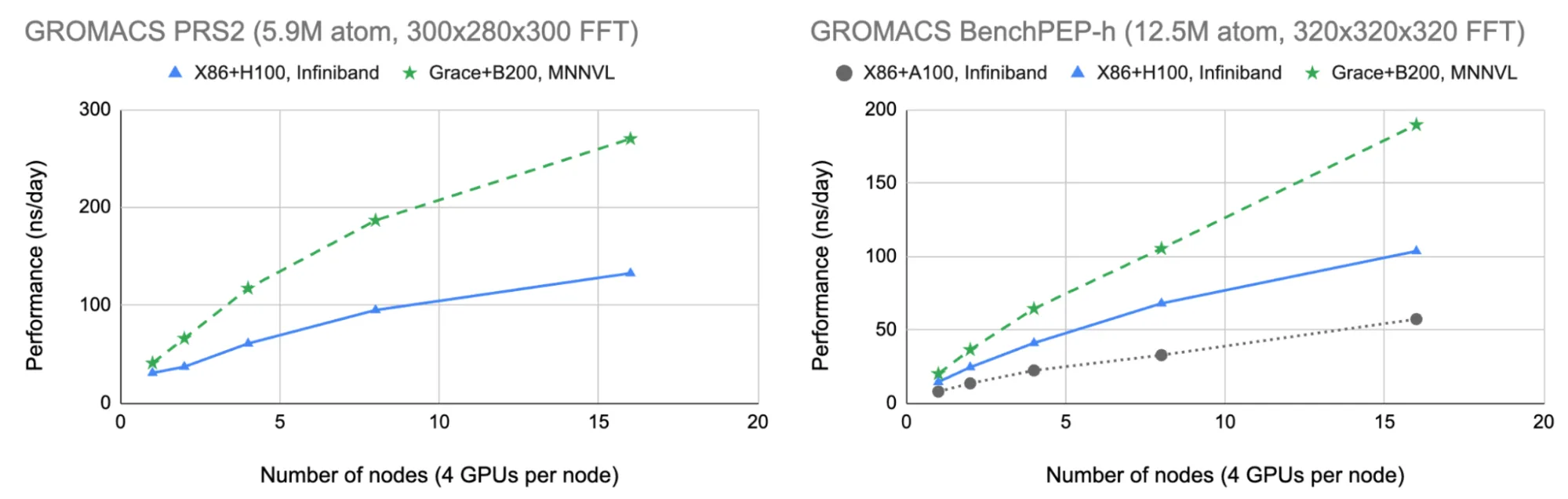
In the right plot of Figure 6, we see that the combination of NVIDIA Grace Blackwell and MNNVL is allowing the larger benchPEP-h case to scale up to almost 200 ns/day (nanoseconds of simulation performed per day of computation), nearly 2x faster than the x86+Hopper/InfiniBand result and over 3x faster than the equivalent x86+Ampere/InfiniBand result reported in the previous blog.
In the left plot of Figure 6, we see an even larger scaling and performance advantage for the smaller PRS2 system (which is more sensitive to communication cost than benchPEP-h). This demonstrates that the new Grace Blackwell MNNVL architecture is not only vital for scaling modern AI, but is also well suited to molecular dynamics: The high bandwidth and low-latency multi-node communications allow researchers to obtain simulation results faster than ever before.
Get started with cuFFTMp
For researchers and developers interested in leveraging these performance improvements, cuFFTMp can now be downloaded from the NVIDIA Developer Zone as a standalone package or as part of the NVIDIA HPC SDK stack. Code samples and API usage can be found in cuFFTMp documentation.
cuFFTMp depends on NVIDIA NVSHMEM for GPU-initiated communications, and its compatibility with NVSHMEM has improved significantly over the past few releases. Starting from cuFFTMp 11.2.6, NVSHMEM ABI backward compatibility between host and device libraries is supported within a major NVSHMEM version. This allows independent NVSHMEM updates within major versions without the need to update cuFFTMp.
Python users have multiple ways to access cuFFTMp features. Those who need a truly pythonic experience can scale distributed FFTs to thousands of GPUs with the nvmath-python library, which delivers the same performance as the native CUDA implementation. The library also provides Python bindings for a low-level integration. Below is a short example of computing distributed FFTs using nvmath-python with cuFFTMp backend.
import numpy as np
import cuda.core.experimental
import nvmath.distributed
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
nranks = comm.Get_size()
device_id = rank % cuda.core.experimental.system.num_devices
nvmath.distributed.initialize(device_id, comm, backends=["nvshmem"])
shape = 64, 256 // nranks, 128
a = np.random.rand(*shape) + 1j * np.random.rand(*shape)
b = nvmath.distributed.fft.fft(a, distribution=nvmath.distributed.distribution.Slab.Y)
Those who prefer pure cuFFTMp binaries can download those from PyPI or conda-forge.
The best developments come out of your feedback, so please contact us with your suggestions at: mathlibs-feedback@nvidia.com.
Leopold Cambier, Miguel Ferrer Avila, and Lukasz Ligowski contributed to the work mentioned in this blog.