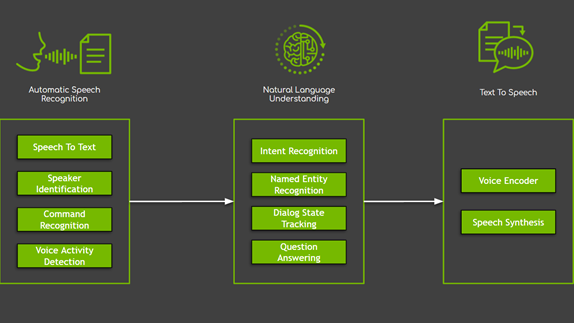
Building an agent is more than just “call an API”—it requires stitching together retrieval, speech, safety, and reasoning components so they behave like one cohesive system. Each layer has its own interface, latency constraints, and integration challenges, and you start to feel them as soon as you move beyond a simple prototype.
In this tutorial, you’ll learn how to build a voice-powered RAG agent with guardrails using the latest NVIDIA Nemotron models released at CES 2026 for speech, RAG, safety, and reasoning. By the end, you’ll have an agent that:
- Listens to spoken input
- Uses multimodal RAG to ground itself in your data
- Reasons over long context
- Applies guardrails before responding
- Returns a safe answer as audio
You can start on your local GPU for development, then deploy the same code on a scalable NVIDIA environment—whether that’s a managed GPU service, an on‑demand cloud workspace, or a production‑ready API runtime—without changing your workflow.
Prerequisites
Before you begin this tutorial, you’ll need:
- NVIDIA API Key for cloud-hosted reasoning models (get one free)
- Local deployment requires:
- ~20GB of disk space
- NVIDIA GPU with at least 24GB of VRAM
- Operating system with Bash (Ubuntu, macOS, or Windows Subsystem for Linux)
- Python 3.10+ environment
- One hour of free time
What you’ll build

| Component | Model | Purpose |
|---|---|---|
| ASR | nemotron-speech-streaming-en-0.6b | Ultra-low latency voice input |
| Embedding | llama-nemotron-embed-vl-1b-v2 | Semantic search over text and images |
| Reranking | llama-nemotron-rerank-vl-1b-v2 | Sharpen retrieval accuracy by 6-7% |
| Safety | llama-3.1-nemotron-safety-guard-8b-v3 | Multilingual content moderation |
| Vision-Language | nemotron-nano-12b-v2-vl | Describe images in context |
| Reasoning | nemotron-3-nano-30b-a3b | High-efficiency reasoning with 1M tokens |
Step 1: Set up the environment
To build a voice agent, you’ll run several NVIDIA Nemotron models together (shown above). The speech, embedding, reranking, and safety models run locally via Transformers and NVIDIA NeMo, while the reasoning models use the NVIDIA API.
uv sync --all-extras
The companion notebook handles all environment configuration. Set your NVIDIA API key for the cloud-hosted reasoning models, and you’re ready to go.
Step 2: Ground the agent with multimodal RAG
Retrieval is the backbone of a reliable agent. With the new Llama Nemotron multimodal embedding and reranking models, you can embed text, images (including scanned documents), and store them directly in a vector index without extra preprocessing. This retrieves the grounded context that the reasoning model will rely on, ensuring the agent references real enterprise data rather than hallucinating.

The llama-nemotron-embed-vl-1b-v2 model supports three input modes—text-only, image-only, and combined image and text—allowing you to index everything from plain documents to slide decks and technical diagrams. In this tutorial, we embed an example that combines both image and text. The embedding model loads via Transformers with flash attention enabled:
from transformers import AutoModel
model = AutoModel.from_pretrained(
"nvidia/llama-nemotron-embed-vl-1b-v2",
trust_remote_code=True,
device_map="auto"
).eval()
# Embed queries and documents
query_embedding = model.encode_queries(["How does AI improve robotics?"])
doc_embeddings = model.encode_documents(texts=documents)
After initial retrieval, the llama-nemotron-rerank-vl-1b-v2 model reranks the results using both text and images to ensure higher accuracy post-retrieval. In benchmarks, adding reranking improves accuracy by approximately 6 to 7%, a meaningful gain when precision matters.
Step 3: Add real‑time speech with Nemotron Speech ASR
With grounding in place, the next step is enabling natural interaction through speech.

The Nemotron Speech ASR model is a streaming model, trained on tens of thousands of hours of English audio from the Granary dataset and a wide range of public speech corpora, optimized for ultra-low latency, real-time decoding. Developers stream audio to the ASR service, receive text results as they arrive, and feed that output directly into the RAG pipeline.
import nemo.collections.asr as nemo_asr
model = nemo_asr.models.ASRModel.from_pretrained(
"nvidia/nemotron-speech-streaming-en-0.6b"
)
transcription = model.transcribe(["audio.wav"])[0]
The model has configurable latency settings, achieving 8.53% average WER at its lowest latency setting of 80ms, improving to 7.16% WER at a 1.1s latency, well below the one-second threshold critical for voice assistants, field tools, and hands-free workflows.
Step 4: Enforce safety with Nemotron Content Safety and PII Models
AI agents operating across regions and languages must understand not only harmful content, but also cultural nuance and context-dependent meaning.

The llama-3.1-nemotron-safety-guard-8b-v3 model provides multilingual content safety across 20+ languages and real-time PII detection across 23 safety categories.
Available via the NVIDIA API, the model makes it straightforward to add input and output filtering without hosting additional infrastructure. It distinguishes between similar phrases that carry different meanings depending on language, dialect, and cultural context—especially important when processing real-time ASR output that may be noisy or informal.
from langchain_nvidia_ai_endpoints import ChatNVIDIA
safety_guard = ChatNVIDIA(model="nvidia/llama-3.1-nemotron-safety-guard-8b-v3")
result = safety_guard.invoke([
{"role": "user", "content": query},
{"role": "assistant", "content": response}
])
Step 5: Add long‑context reasoning with Nemotron 3 Nano
NVIDIA Nemotron 3 Nano provides the reasoning capability for the agent, combining efficient mixture-of-experts (MoE) and hybrid Mamba-Transformer architecture with a 1M-token context window. This allows the model to incorporate retrieved documents, user history, and intermediate steps in a single inference request.

When retrieved documents contain images, the agent first uses Nemotron Nano VL to describe them in context, then passes all information to Nemotron 3 Nano for the final response. The model supports an optional thinking mode for more complex reasoning tasks:
completion = client.chat.completions.create(
model="nvidia/nemotron-3-nano-30b-a3b",
messages=[{"role": "user", "content": prompt}],
extra_body={"chat_template_kwargs": {"enable_thinking": True}}
)
The output routes through the safety filter before being returned, transforming your retrieval-augmented lookup into a full reasoning-capable agent.
Step 6: Wire it all together with LangGraph
LangGraph orchestrates the complete workflow as a directed graph. Each node handles one stage—transcription, retrieval, image description, generation, and safety checking—with clean handoffs between components:
Voice Input → ASR → Retrieve → Rerank → Describe Images → Reason → Safety → Response
The agent state flows through each node, accumulating context as it progresses. This structure makes it straightforward to add conditional logic, retry failed steps, or branch based on content type. The complete implementation in the companion notebook shows how to define each node and wire them into a production-ready pipeline.
Step 7: Deploy the agent
You can deploy your agent anywhere once it runs cleanly on your machine. Use NVIDIA DGX Spark when you need distributed ingestion, embedding generation, or large‑scale batch vector indexing. Nemotron models can be optimized, packaged, and run as NVIDIA NIM–a set of prebuilt, GPU‑accelerated inference microservices for deploying AI models on NVIDIA infrastructure– and can be called directly from Spark for scalable processing. Use NVIDIA Brev when you want an on‑demand GPU workspace where your notebook runs as-is, with no system setup, plus remote access to your Spark cluster that you can easily share with your team.
If you want to see the same deployment patterns applied to a physical robot assistant, check out the Reachy Mini personal assistant tutorial built with Nemotron and DGX Spark.
Both environments use the same code path, so you can move smoothly from experimentation to production with minimal changes.
What you’ve built
You now have the core structure of a Nemotron-powered agent with four core components: speech ASR for voice interaction, multimodal RAG for grounding, multilingual content‑safety filtering that accounts for cultural nuance, and Nemotron 3 Nano for long-context reasoning. The same code runs from local development to production GPU clusters without changes.
| Component | Purpose |
|---|---|
| Multimodal RAG | Ground responses in real enterprise data |
| Speech ASR | Enable natural voice interaction |
| Safety | Identify unsafe content across languages and cultural contexts |
| Long-Context LLM | Generate accurate responses with reasoning |
Each section in this tutorial aligns directly with a section in the notebook, so you can implement and test the pipeline incrementally. Once it works end-to-end, the same code scales to production deployment.
Ready to build? Open the companion notebook and follow along step-by-step:
If you’d like to explore the underlying components, each of the following is a collection of Nemotron models available on Hugging Face, along with the tools used to orchestrate the agent:
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, Discord, and YouTube.
- Visit our Nemotron developer page for all the essentials you need to get started with the most open, smartest-per-compute reasoning model.
- Explore new open Nemotron models and datasets on Hugging Face and NIM microservices and Blueprints on build.nvidia.com.
- Share your ideas and vote on features to help shape the future of Nemotron.
- Tune into upcoming Nemotron livestreams and connect with the NVIDIA Developer community through the Nemotron developer forum and the Nemotron channel on Discord
Browse video tutorials and livestreams to get the most out of NVIDIA Nemotron.