
Remote Direct Memory Access (RDMA) allows computers to exchange data in memory without the involvement of a CPU. The benefits include low latency and high bandwidth data exchange. GPUDirect RDMA extends the same philosophy to the GPU and the connected peripherals in Jetson AGX Xavier.
GPUDirect RDMA enables a direct path for data exchange between the GPU-accessible memory (the CUDA memory) and a third-party peer device using standard PCI Express features. Examples of third-party devices include network interfaces, video acquisition devices, storage adapters, and more. CUDA 10.0 extends GPUDirect RDMA support to the Jetson AGX Xavier platform and is included in JetPack as part of the Linux4Tegra (L4T) release. Figure 1 shows a block diagram of memory accesses using GPUDirect RDMA.
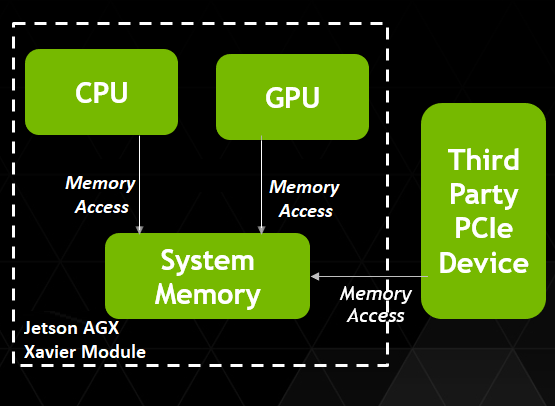
How GPUDirect RDMA Works
Standard DMA Transfer
First, let’s look at how standard DMA transfer initiates from the userspace. The following components are present in this scenario:
- Userspace program
- Userspace communication library
- Kernel driver for the device interested in doing DMA transfers
The general sequence works like this:
- The userspace program requests a transfer via the userspace communication library. This operation takes a pointer to data (a virtual address) and a size in bytes.
- The communication library makes sure the memory region corresponding to the virtual address and size is ready for the transfer. If this is not the case, it needs to be handled by the kernel driver (next step).
- The kernel driver receives the virtual address and size from the userspace communication library. It then asks the kernel to translate the virtual address range to a list of physical pages and makes sure they are ready to be transferred to or from it. We refer to this operation as pinning the memory.
- The kernel driver uses the list of pages to program the physical device’s DMA engine(s).
- The communication library initiates the transfer.
- After the transfer completes, the communication library cleans up resources used to pin the memory. We refer to this operation as unpinning the memory.
GPUDirect RDMA Transfers
Some changes to the sequence above have to be introduced for the communication to support GPUDirect RDMA transfers. First, two new components are present:
- Userspace CUDA library
- NVIDIA kernel driver
The Basics of UVA CUDA Memory Management describes how programs using the CUDA library have their address space split between GPU and CPU virtual addresses. The communication library has to implement two separate paths for them.
The userspace CUDA library provides a function that lets the communication library distinguish between CPU and GPU addresses. The library returns additional metadata for GPU addresses that is required to uniquely identify the GPU memory represented by the address. See Userspace API for details.
The difference between the paths for CPU and GPU addresses is in how the memory is pinned and unpinned. Built-in Linux kernel functions (get_user_pages() and put_page()) handle CPU memory. However, pinning and unpinning of GPU memory has to be handled by functions provided by the NVIDIA kernel driver. See Pinning GPU Memory and Unpinning GPU Memory for details.
Porting to Jetson AGX Xavier Platform
The Jetson AGX Xavier platform supports GPUDirect RDMA starting with CUDA 10.0. Hardware and software specific divergence of Jetson versus Linux-Desktop means existing applications need to be slightly modified in order to port them to Jetson. Highlights of the necessary changes follows.
Changing the Allocator
GPUDirect RDMA on desktop allows applications to operate exclusively on GPU pages allocated using cudaMalloc(). Jetson applications need to change the memory allocator from cudaMalloc() to cudaHostAlloc(). Applications can either:
- Treat the returned pointer as if it is a device pointer, provided that the iGPU supports UVA or that the cudaDevAttrCanUseHostPointerForRegisteredMem device attribute is a non-zero value when queried using cudaDeviceGetAttribute() for iGPU.
- Get the device pointer corresponding to the host memory allocated using cudaHostGetDevicePointer(). Once the application has the device pointer, all the rules that are applicable to the standard GPUDirect solution also apply to Jetson.
Modification to Kernel API
The declarations under the Jetson API column of the following table can be found in the nv-p2p.h header distributed in the NVIDIA Driver package. Refer to the inline documentation contained in that header file for a detailed description of the parameters and return values.
The table below represents the kernel API changes on Jetson vis-a-vis Desktop:
|
Desktop APIs |
Jetson AGX APIs |
|
int nvidia_p2p_get_pages(uint64_t p2p_token, uint32_t va_space_token, uint64_t virtual_address, uint64_t length, struct nvidia_p2p_page_table **page_table, void (*free_callback)(void *data), void *data); |
int nvidia_p2p_get_pages(u64 virtual_address, u64 length, struct nvidia_p2p_page_table **page_table, void (*free_callback)(void *data), void *data); |
|
int nvidia_p2p_put_pages(uint64_t p2p_token, uint32_t va_space_token, uint64_t virtual_address, struct nvidia_p2p_page_table *page_table); |
int nvidia_p2p_put_pages(struct nvidia_p2p_page_table *page_table); |
|
int nvidia_p2p_dma_map_pages(struct pci_dev *peer, struct nvidia_p2p_page_table *page_table, struct nvidia_p2p_dma_mapping **dma_mapping); |
int nvidia_p2p_dma_map_pages(struct device *dev, struct nvidia_p2p_page_table *page_table, struct nvidia_p2p_dma_mapping **dma_mapping, enum dma_data_direction direction); |
|
int nvidia_p2p_dma_unmap_pages(struct pci_dev *peer, struct nvidia_p2p_page_table *page_table, struct nvidia_p2p_dma_mapping *dma_mapping); |
int nvidia_p2p_dma_unmap_pages(struct nvidia_p2p_dma_mapping *dma_mapping); |
|
int nvidia_p2p_free_page_table(struct nvidia_p2p_page_table *page_table); |
int nvidia_p2p_free_page_table(struct nvidia_p2p_page_table *page_table); |
|
int nvidia_p2p_free_dma_mapping(struct nvidia_p2p_dma_mapping *dma_mapping); |
int nvidia_p2p_free_dma_mapping(struct nvidia_p2p_dma_mapping *dma_mapping); |
Other highlights include:
- The length of the requested mapping must be a multiple of 4KB. If not, then the request fails, leading to an error. (Note that on Desktop the alignment is 64KB.)
- Unlike the Desktop version, callback registered at nvidia_p2p_get_pages() will always be triggered when nvidia_p2p_put_pages() is invoked. It is the responsibility of the kernel driver to free the page_table allocated by calling nvidia_p2p_free_page_table(). Similar to the Desktop version, the callback will also be triggered in scenarios explained in Unpin Callback.
- Since cudaHostAlloc() can be allocated with cudaHostAllocWriteCombined flag or default flag, applications are expected to exercise caution when mapping the memory to userspace, for example using standard linux mmap(). In this regard:
- When GPU memory is allocated as writecombined, the userspace mapping should also be done as writecombined by passing the vm_page_prot member of vm_area_struct to the standard linux interface: pgprot_writecombine().
- When GPU memory is allocated as default, no modifications to the vm_page_prot member of vm_area_struct should be done.
- Incompatible combination of map and allocation attributes will lead to undefined behavior.
The design and interfaces of GPUDirect are featured in CUDA documentation.
Benefits of Using GPUDirect RDMA on Jetson AGX Xavier
- Performance (lower latency, higher throughput). GPUDirect RDMA eliminates additional wait times and reduces the number of operations to process the pipeline by enabling the direct data exchange between the third-party PCIe device and CUDA memory. This enhances the overall system performance.
If GPUDirect RDMA is absent, the application running CUDA algorithms on the data coming in from a third-party PCIe device must copy the data from that third-party PCIe device to the host memory. It must then perform an explicit memory copy from the host to CUDA memory. The application must wait for the third-party driver to write the data into application-accessible system memory and then copy this data to CUDA memory.
- Application portability / familiarity with the desktop environment. A major advantage with GPUDirect RDMA is its similarity with working on a desktop. GPUDirect RDMAenables developers to also write their code on the desktop and have it work on Tegra platforms such as Jetson AGX Xavier with a few minor changes.
Use Cases
Applications built on the Jetson AGX Xavier platform solve various real-world problems in many embedded and edge-based systems. While the Jetson platform caters to computational needs, a number of use cases exist where third-party peer devices connect using standard features over PCI Express. Here are a few:
- A custom image processing chip plugged into Jetson with data from multiple cameras initially processed on the GPU and then sent over to this external image processing chip for further processing. GPUDirect RDMA solves this problem where there is a need for faster data exchange between the GPU and a third-party peer device.
- Images captured by the camera are sent directly to the GPU using RDMA. Deep learning inference is then done on the images using CUDA and the results reported back.
- High bandwidth, low-latency network data transfer such as large surface transfers, allow a PCIe-based network interface card to provide, retrieve, and stream data for processing.
- The virtualized network functions can utilize GPUDirect for streaming in and out the data to be processed by the GPU.
- Jetson systems can communicate with another GPU, Jetson or x86-based systems over a PCIe or PCIe switch for high bandwidth, low latency compute work.
- Custom FPGAs can distribute data to the GPU for CUDA processing and the results are aggregated to the master CPU for various purposes like display, communication, etc.
Demonstration
NVIDIA has created a simple demonstration of GPUDirect RDMA on Jetson AGX Xavier. This demonstration uses an FPGA device attached to Jetson’s PCIe port to copy memory from one CUDA surface to another and validate the result.
The FPGA configuration, the Linux kernel driver code, and the user space test applications are written in a minimal fashion. These form a reference on how to implement GPUDirect RDMA in your own application and provide a simple and cost-effective method for validating the correct operation of GPUDirect RDMA.
You can find the reference code on GitHub. The repo also contains links to the required hardware and full instructions to operate the demonstration.
In summary, CUDA 10.0 gives users of the Jetson AGX platform to utilize the GPUDirect RDMA feature to achieve higher throughput and lower latencies by making minimal changes to their desktop application and porting them on the Jetson platform.