
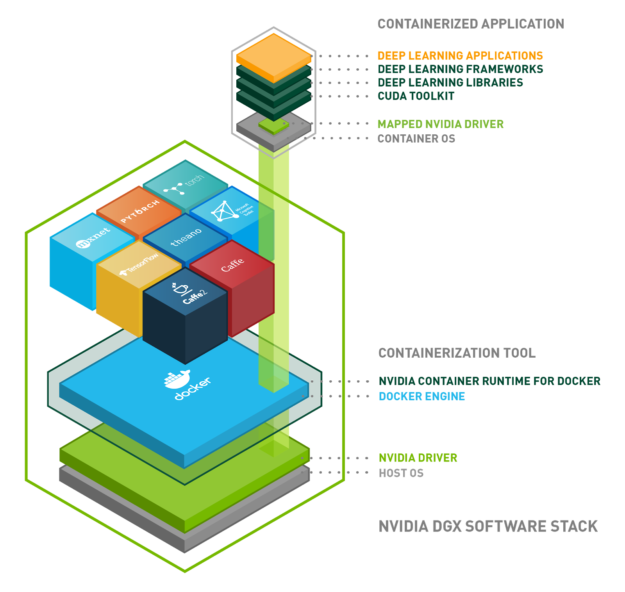
NVIDIA uses containers to develop, test, benchmark, and deploy deep learning (DL) frameworks and HPC applications. We wrote about building and deploying GPU containers at scale using NVIDIA-Docker roughly two years ago. Since then, NVIDIA-Docker has been downloaded close to 2 million times. A variety of customers used NVIDIA-Docker to containerize and run GPU accelerated workloads.
NVIDIA offers GPU accelerated containers via NVIDIA GPU Cloud (NGC) for use on DGX systems, public cloud infrastructure, and even local workstations with GPUs. NVIDIA-Docker has been the critical underlying technology for these initiatives.
The adoption of container technologies other than Docker for an ever-evolving set of use cases for DL and HPC workloads among others led us to fundamentally rethink our existing NVIDIA-Docker architecture. Our primary goal pursued extensibility across not only various container runtimes but also container orchestration systems.
The NVIDIA Container Runtime introduced here is our next-generation GPU-aware container runtime. It is compatible with the Open Containers Initiative (OCI) specification used by Docker, CRI-O, and other popular container technologies.
You’ll learn about the NVIDIA Container Runtime components and how it can be extended to support multiple container technologies. Let’s examine the architecture and benefits of the new runtime, showcase some of the new features, and walk through some examples of deploying GPU accelerated applications using Docker and LXC.
NVIDIA Container Runtime
NVIDIA designed NVIDIA-Docker in 2016 to enable portability in Docker images that leverage NVIDIA GPUs. It allowed driver agnostic CUDA images and provided a Docker command line wrapper that mounted the user mode components of the driver and the GPU device files into the container at launch.
Over the lifecycle of NVIDIA-Docker, we realized the architecture lacked flexibility for a few reasons:
- Tight integration with Docker did not allow support of other container technologies such as LXC, CRI-O, and other runtimes in the future
- We wanted to leverage other tools in the Docker ecosystem – e.g. Compose (for managing applications that are composed of multiple containers)
- Support GPUs as a first-class resource in orchestrators such as Kubernetes and Swarm
- Improve container runtime support for GPUs – esp. automatic detection of user-level NVIDIA driver libraries, NVIDIA kernel modules, device ordering, compatibility checks and GPU features such as graphics, video acceleration
As a result, the redesigned NVIDIA-Docker moved the core runtime support for GPUs into a library called libnvidia-container. The library relies on Linux kernel primitives and is agnostic relative to the higher container runtime layers. This allows easy extension of GPU support into different container runtimes such as Docker, LXC and CRI-O. The library includes a command-line utility and also provides an API for integration into other runtimes in the future. The library, tools, and the layers we built to integrate into various runtimes are collectively called the NVIDIA Container Runtime.
In the next few sections, you’ll learn about the integration into both Docker and LXC.
Support for Docker
Before diving into NVIDIA Container Runtime integration with Docker, let’s briefly look at how the Docker platform has evolved.
Since 2015, Docker has been donating key components of its container platform, starting with the Open Containers Initiative (OCI) specification and an implementation of the specification of a lightweight container runtime called runc. In late 2016, Docker also donated containerd, a daemon which manages the container lifecycle and wraps OCI/runc. The containerd daemon handles transfer of images, execution of containers (with runc), storage, and network management. It is designed to be embedded into larger systems such as Docker. More information on the project is available on the official site.
Figure 1 shows how the libnvidia-container integrates into Docker, specifically at the runc layer. We use a custom OCI prestart hook called nvidia-container-runtime-hook to runc in order to enable GPU containers in Docker (more information about hooks can be found in the OCI runtime spec). The addition of the prestart hook to runc requires us to register a new OCI compatible runtime with Docker (using the –runtime option). At container creation time, the prestart hook checks whether the container is GPU-enabled (using environment variables) and uses the container runtime library to expose the NVIDIA GPUs to the container.
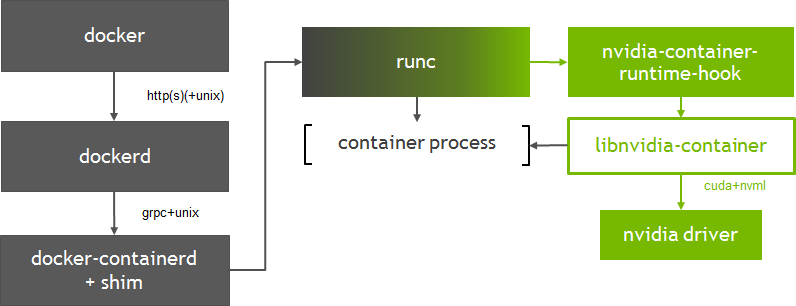
Integration at the runc layer also allows flexibility to support other OCI runtimes such as CRI-O. Version 1.1 of containerd added support for the Container Runtime Interface (CRI) in Kubernetes; last week Kubernetes announced the general availability of the containerd integration via the CRI plugin. The new architecture of the NVIDIA runtime can easily support either choice of runtime with Kubernetes. This level of flexibility is important as we work closely with the community to enable first-class GPU support in Kubernetes.
Environment Variables
The NVIDIA Container Runtime uses environment variables in container images to specify a GPU accelerated container.
- NVIDIA_VISIBLE_DEVICES : controls which GPUs will be accessible inside the container. By default, all GPUs are accessible to the container.
- NVIDIA_DRIVER_CAPABILITIES : controls which driver features (e.g. compute, graphics) are exposed to the container.
- NVIDIA_REQUIRE_* : a logical expression to define the constraints (e.g. minimum CUDA, driver or compute capability) on the configurations supported by the container.
If no environment variables are detected (either on the Docker command line or in the image), the default runc is used. You can find more information on these environment variables in the NVIDIA Container Runtime documentation. These environment variables are already set in the official CUDA containers from NVIDIA.
Installation
Your system must satisfy the following prerequisites to begin using NVIDIA Container Runtime with Docker.
- Supported version of Docker for your distribution. Follow the official instructions from Docker.
- The latest NVIDIA driver. Use the package manager to install the
cuda-driverspackage or use the installer from the driver downloads site. Note that using thecuda-driverspackage may not work on Ubuntu 18.04 LTS systems.
To get started using the NVIDIA Container Runtime with Docker, either use the nvidia-docker2 installer packages or manually setup the runtime with Docker Engine. The nvidia-docker2 package includes a custom daemon.json file to register the NVIDIA runtime as the default with Docker and a script for backwards compatibility with nvidia-docker 1.0.
If you have nvidia-docker 1.0 installed, you need to remove it and any existing GPU containers before installing the NVIDIA runtime. Note that the following installation steps apply to Debian distributions and their derivatives.
$ docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
$ sudo apt-get purge -y nvidia-docker
Now, let’s add the package repositories and refresh the package index.
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add - $ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list $ sudo apt-get update
Then install the various components using the nvidia-docker2 package and reload the Docker daemon configuration.
$ sudo apt-get install -y nvidia-docker2 $ sudo pkill -SIGHUP dockerd
Run the following command line utility (CLI) to verify that NVIDIA driver and runtime have installed correctly on your system (provided as part of the installer packages). The runtime CLI provides information on the driver and devices detected in the system. In this example, the runtime library has correctly detected and enumerated 4 NVIDIA Tesla V100s in the system.
$ sudo nvidia-container-cli --load-kmods info NVRM version: 396.26 CUDA version: 9.2 Device Index: 0 Device Minor: 2 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-e354d47d-0b3e-4128-74bf-f1583d34af0e Bus Location: 00000000:00:1b.0 Architecture: 7.0 Device Index: 1 Device Minor: 0 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-716346f4-da29-392a-c4ee-b9840ec2f2e9 Bus Location: 00000000:00:1c.0 Architecture: 7.0 Device Index: 2 Device Minor: 3 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-9676587f-b418-ee6b-15ac-38470e1278fb Bus Location: 00000000:00:1d.0 Architecture: 7.0 Device Index: 3 Device Minor: 2 Model: Tesla V100-SXM2-16GB GPU UUID: GPU-2370332b-9181-d6f5-1f24-59d66fc7a87e Bus Location: 00000000:00:1e.0 Architecture: 7.0
The CUDA version detected by nvidia-container-cli verifies whether the NVIDIA driver installed on your host is sufficient to run a container based on a specific CUDA version. If an incompatibility exists, the runtime will not start the container. More information on compatibility and minimum driver requirements for CUDA is available here.
Now, let’s try running a GPU container with Docker. This example pulls the NVIDIA CUDA container available on the Docker Hub repository and runs the nvidia-smi command inside the container.
$ sudo docker run --rm --runtime=nvidia -ti nvidia/cuda root@d6c41b66c3b4:/# nvidia-smi Sun May 20 22:06:13 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.26 Driver Version: 396.26 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | Off | | N/A 41C P0 34W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | Off | | N/A 39C P0 35W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 2 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | Off | | N/A 39C P0 38W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 3 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 | | N/A 42C P0 38W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
Running GPU Containers
Let’s now look at some examples of running more complex GPU applications. NVIDIA offers a variety of pre-built containers for deep learning and HPC on the NGC registry.
Deep Learning Framework Container
This example trains a deep neural network using the PyTorch deep learning framework container available from NGC. You’ll need to open a free NGC account to access the latest deep learning framework and HPC containers. The NGC documentation outlines the steps required to get started.
This example uses the NVIDIA_VISIBLE_DEVICES variable, to expose only two GPUs to the container.
$ sudo docker run -it --runtime=nvidia --shm-size=1g -e NVIDIA_VISIBLE_DEVICES=0,1 --rm nvcr.io/nvidia/pytorch:18.05-py3 Copyright (c) 2006 Idiap Research Institute (Samy Bengio) Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz) All rights reserved. Various files include modifications (c) NVIDIA CORPORATION. All rights reserved. NVIDIA modifications are covered by the license terms that apply to the underlying project or file.
Run the nvidia-smi command inside the container to verify only two GPUs are visible.
root@45cebefa1480:/workspace# nvidia-smi Mon May 28 07:15:39 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.26 Driver Version: 396.26 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 | | N/A 39C P0 36W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 | | N/A 38C P0 35W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ root@45cebefa1480:/workspace#
Try running the MNIST training example included with the container:
root@45cebefa1480:/workspace/examples/mnist# python main.py Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz Processing... Done! main.py:68: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument. return F.log_softmax(x) main.py:90: UserWarning: invalid index of a 0-dim tensor. This will be an error in PyTorch 0.5. Use tensor.item() to convert a 0-dim tensor to a Python number 100. * batch_idx / len(train_loader), loss.data[0])) Train Epoch: 1 [0/60000 (0%)] Loss: 2.373651 Train Epoch: 1 [640/60000 (1%)] Loss: 2.310517 Train Epoch: 1 [1280/60000 (2%)] Loss: 2.281828 Train Epoch: 1 [1920/60000 (3%)] Loss: 2.315808 Train Epoch: 1 [2560/60000 (4%)] Loss: 2.235439 Train Epoch: 1 [3200/60000 (5%)] Loss: 2.234249 Train Epoch: 1 [3840/60000 (6%)] Loss: 2.226109 Train Epoch: 1 [4480/60000 (7%)] Loss: 2.228646 Train Epoch: 1 [5120/60000 (9%)] Loss: 2.132811
OpenGL Graphics Container
As discussed in the previous sections, the NVIDIA Container Runtime now provides support for running OpenGL and EGL applications. The next example builds and runs the N-body simulation using OpenGL. Use the sample Dockerfile available on NVIDIA GitLab to build the container.
Copy the Dockerfile and build the N-body sample
$ docker build -t nbody .
Allow the root user to access the running X server
$ xhost +si:localuser:root
Run the N-body sample
$ sudo docker run --runtime=nvidia -ti --rm -e DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix nbody
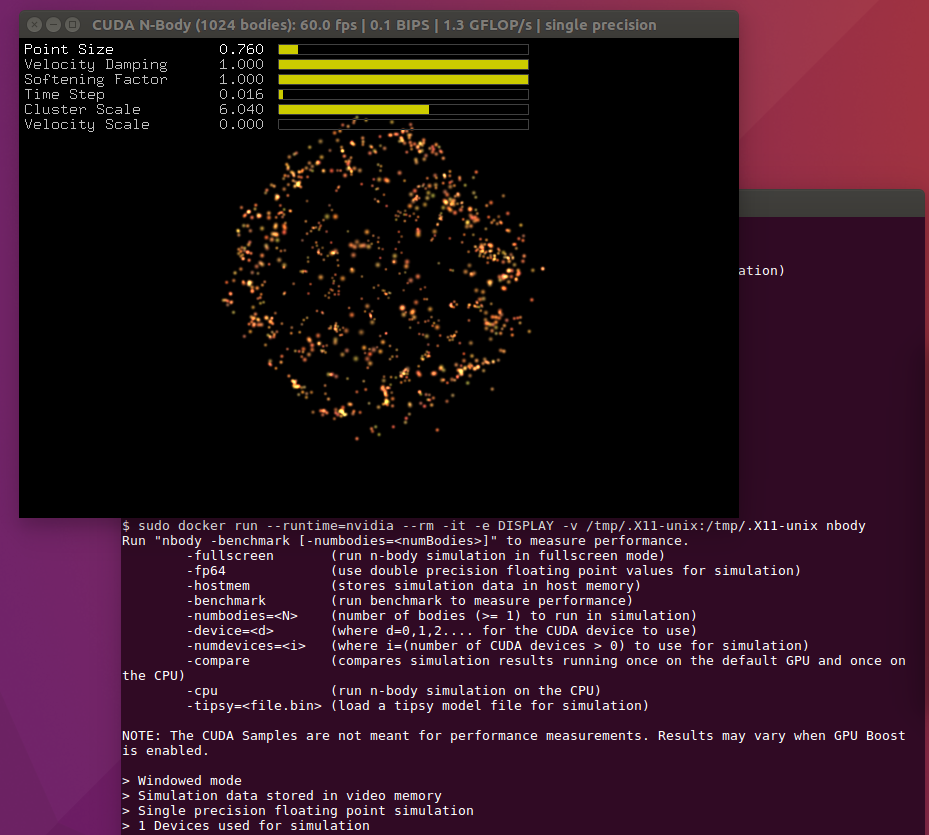
Docker Compose
The final example uses Docker Compose to show how easy it can be to launch multiple GPU containers with the NVIDIA Container Runtime. The example will launch 3 containers – the N-body sample with OpenGL, an EGL sample (peglgears from Mesa) and a simple container that runs the nvidia-smi command.
Install Docker Compose
$ sudo curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose
Clone the samples available from NVIDIA Gitlab
$ git clone https://gitlab.com/nvidia/samples.git
Write a docker-compose.yml to specify the three containers and the environments. Copy the following using a text editor of your choice:
version: '2.3'
services:
nbody:
build: samples/cudagl/ubuntu16.04/nbody
runtime: nvidia
environment:
- DISPLAY
volumes:
- /tmp/.X11-unix:/tmp/.X11-unix
peglgears:
build: samples/opengl/ubuntu16.04/peglgears
runtime: nvidia
nvsmi:
image: ubuntu:18.04
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=all
command: nvidia-smi
Allow the root user to access the running X server (for the N-body sample)
$ xhost +si:localuser:root
Finally, start the containers
$ sudo docker-compose up
Your console output may appear as below
Building nbody
Step 1/6 : FROM nvidia/cudagl:9.0-base-ubuntu16.04
---> b6055709073e
Step 2/6 : ENV NVIDIA_DRIVER_CAPABILITIES ${NVIDIA_DRIVER_CAPABILITIES},display
---> Using cache
---> ebd1c003a592
Step 3/6 : RUN apt-get update && apt-get install -y --no-install-recommends cuda-samples-$CUDA_PKG_VERSION && rm -rf /var/lib/apt/lists/*
---> Using cache
---> 1987dc2c1bbc
Step 4/6 : WORKDIR /usr/local/cuda/samples/5_Simulations/nbody
---> Using cache
---> de7af4fbb03e
Step 5/6 : RUN make
---> Using cache
---> a6bcfb9a4958
Step 6/6 : CMD ./nbody
---> Using cache
---> 9c11a1e93ef2
Successfully built 9c11a1e93ef2
Successfully tagged ubuntu_nbody:latest
WARNING: Image for service nbody was built because it did not already exist. To rebuild this image you must use `docker-compose build` or `docker-compose up --build`.
Starting ubuntu_nbody_1 ... done
Starting ubuntu_nvsmi_1 ... done
Starting ubuntu_peglgears_1 ... done
Attaching to ubuntu_nvsmi_1, ubuntu_peglgears_1, ubuntu_nbody_1
ubuntu_nvsmi_1 exited with code 0
peglgears_1 | peglgears: EGL version = 1.4
peglgears_1 | peglgears: EGL_VENDOR = NVIDIA
peglgears_1 | 246404 frames in 5.0 seconds = 49280.703 FPS
ubuntu_peglgears_1 exited with code 0
Support for GPU Containers with LXC
Linux Containers (or LXC) is an OS-level virtualization tool for creating and managing system or application containers. Early releases of Docker used LXC as the underlying container runtime technology. LXC offers an advanced set of tools to manage containers (e.g. templates, storage options, passthrough devices, autostart etc.) and offers the user a lot of control. In the references, We have provided a link to a GTC 2018 talk on LXC by engineers from Canonical and Cisco in the references at the end of this post.
LXC supports unprivileged containers (using the user namespaces feature in the Linux kernel). This becomes great advantage in the context of deployment of containers in HPC environments, where users may not have administrative rights to run containers. LXC also supports import of Docker images and we will explore an example in more detail below.
NVIDIA continues to work closely with the LXC community on upstreaming patches to add GPU support. LXC 3.0.0 released in early April includes support for GPUs using the NVIDIA runtime. For more information and a demo, see this news post from Canonical.
Figure 2 shows how the container runtime library (libnvidia-container) integrates into LXC.
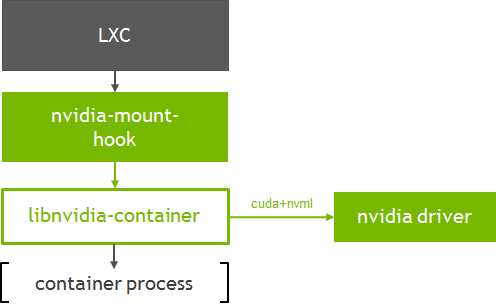
Let’s look at running a simple CUDA container with LXC. This example shows how the default LXC OCI template can be used to create an application container from OCI images such as those available on Docker Hub (using tools such as skopeo and umoci).
First, lets setup the repositories for the tools:
$ sudo add-apt-repository ppa:ubuntu-lxc/lxc-stable $ sudo apt-add-repository ppa:projectatomic/ppa
Install LXC and dependent tools such as skopeo:
$ apt-get install libpam-cgfs lxc-utils lxcfs lxc-templates skopeo skopeo-containers jq libnvidia-container-tools
Setup umoci:
$ sudo curl -fsSL -o /usr/local/bin/umoci https://github.com/openSUSE/umoci/releases/download/v0.4.0/umoci.amd64 $ sudo chmod ugo+rx /usr/local/bin/umoci
Setup user, group ids and virtual ethernet interfaces for each user. Refer to the LXC documentation on creating unprivileged containers. The sample scripts are provided here for convenience.
$ sudo curl -fsSL -o /usr/local/bin/generate-lxc-perms https://gist.githubusercontent.com/3XX0/ef77403389ffa1ca85d4625878706c7d/raw/4f0d2c02d82236f74cf668c42ee72ab06158d1d2/generate-lxc-perms.sh $ sudo chmod ugo+rx /usr/local/bin/generate-lxc-perms $ sudo curl -fsSL -o /usr/local/bin/generate-lxc-config https://gist.githubusercontent.com/3XX0/b3e2bd829d43104cd120f4258c4eeca9/raw/890dc720e1c3ad418f96ba8529eae028f01cc994/generate-lxc-config.sh $ sudo chmod ugo+rx /usr/local/bin/generate-lxc-config
Now, setup GPU support for every container:
$ sudo tee /usr/share/lxc/config/common.conf.d/nvidia.conf <<< 'lxc.hook.mount = /usr/share/lxc/hooks/nvidia' $ sudo chmod ugo+r /usr/share/lxc/config/common.conf.d/nvidia.conf
As a one-time setup, setup the permissions and configuration as a regular user:
$ sudo generate-lxc-perms $ generate-lxc-config
Use lxc-create to download and create a CUDA application container from the CUDA image available on NVIDIA’s Docker Hub repository.
$ lxc-create -t oci cuda -- -u docker://nvidia/cuda
Getting image source signatures
Copying blob sha256:297061f60c367c17cfd016c97a8cb24f5308db2c913def0f85d7a6848c0a17fa
41.03 MB / 41.03 MB [======================================================] 0s
Copying blob sha256:e9ccef17b516e916aa8abe7817876211000c27150b908bdffcdeeba938cd004c
850 B / 850 B [============================================================] 0s
Copying blob sha256:dbc33716854d9e2ef2de9769422f498f5320ffa41cb79336e7a88fbb6c3ef844
621 B / 621 B [============================================================] 0s
Copying blob sha256:8fe36b178d25214195af42254bc7d5d64a269f654ef8801bbeb0b6a70a618353
851 B / 851 B [============================================================] 0s
Copying blob sha256:686596545a94a0f0bf822e442cfd28fbd8a769f28e5f4018d7c24576dc6c3aac
169 B / 169 B [============================================================] 0s
Copying blob sha256:aa76f513fc89f79bec0efef655267642eba8deac019f4f3b48d2cc34c917d853
6.65 MB / 6.65 MB [========================================================] 0s
Copying blob sha256:c92f47f1bcde5f85cde0d7e0d9e0caba6b1c9fcc4300ff3e5f151ff267865fb9
397.29 KB / 397.29 KB [====================================================] 0s
Copying blob sha256:172daef71cc32a96c15d978fb01c34e43f33f05d8015816817cc7d4466546935
182 B / 182 B [============================================================] 0s
Copying blob sha256:e282ce84267da687f11d354cdcc39e2caf014617e30f9fb13f7711c7a93fb414
449.41 MB / 449.41 MB [====================================================] 8s
Copying blob sha256:91cebab434dc455c4a9faad8894711a79329ed61cc3c08322285ef20599b4c5e
379.37 MB / 552.87 MB [=====================================>-----------------]
Writing manifest to image destination
Storing signatures
Unpacking the rootfs
• rootless{dev/agpgart} creating empty file in place of device 10:175
• rootless{dev/audio} creating empty file in place of device 14:4
• rootless{dev/audio1} creating empty file in place of device 14:20
As a regular user, we can run the nvidia-smi inside the container:
$ lxc-execute cuda root@cuda:/# nvidia-smi Mon May 28 21:48:57 2018 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 396.26 Driver Version: 396.26 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:1B.0 Off | 0 | | N/A 40C P0 36W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 Tesla V100-SXM2... On | 00000000:00:1C.0 Off | 0 | | N/A 39C P0 35W / 300W | 0MiB / 16160MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 2 Tesla V100-SXM2... On | 00000000:00:1D.0 Off | 0 | | N/A 39C P0 38W / 300W | 0MiB / 16160MiB | 1% Default | +-------------------------------+----------------------+----------------------+ | 3 Tesla V100-SXM2... On | 00000000:00:1E.0 Off | 0 | | N/A 40C P0 38W / 300W | 0MiB / 16160MiB | 1% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
Conclusion
This post covers the NVIDIA Container Runtime and how it can be easily integrated into the container runtime and orchestration ecosystem to enable GPU support. Get started with building and running GPU containers with it today! Installer packages are available for a variety of Linux distributions. Nvidia-Docker 1.0 is deprecated and is no longer actively supported. We strongly encourage users to upgrade to the new NVIDIA runtime when using Docker. The future roadmap includes a number of exciting features including support for Vulkan, CUDA MPS, containerized drivers and much more.
If you are running containers on public cloud service providers such as Amazon AWS or Google Cloud, NVIDIA offers virtual machine images that include all the components you need, including the NVIDIA Container Runtime to get started.
If you have questions or comments please leave them below in the comments section. For technical questions about installation and usage, we recommend starting a discussion on the NVIDIA Accelerated Computing forum.
References
[1] Watch a 3-part series on installing NVIDIA Container Runtime and using it with NGC containers (https://www.youtube.com/watch?v=r3LrCnou1K4)
[2] Using Container for GPU Workloads (GTC 2018 talk on LXC) http://on-demand-gtc.gputechconf.com/gtc-quicklink/a6WCcp
[3] Frequently asked questions are available in the documentation https://github.com/NVIDIA/nvidia-docker/wiki/Frequently-Asked-Questions