
Some programming situations call for reporting “soft” errors asynchronously. While printf can be a useful tool, it can increase register use and impact performance. In this post, we present an alternative, including a header library for generating custom error and warning messages on the GPU without a hard stop to your kernel.
Often error reporting can get in the way of performance. While there are some errors that must be handled immediately, others can manifest in the form of warnings and soft errors that can be reported and resolved later.
For GPUs, this is often a good strategy since different kernels can be launched on different streams. You can query and resolve the error asynchronously if any occur.
In some physics simulation codes, for example, there may be numeric solutions that are not physically feasible, such as negative mass. You may want to vary the run parameters to achieve a feasible solution, such as setting a smaller timestep.
While it is sometimes possible to create an error estimator, there may be rare cases where the estimator may still fail.
In the context of GPUs, CUDA users may be inclined to check for the occasionally occurring infeasible solution and then use printf to alert the end user on screen. There are several potential downsides to this solution:
- If there are several streams running asynchronously, the output may get convoluted. When an error occurs, you must restart certain operations. Additional debugging feedback is not as useful.
- In the case of register-constrained kernels where you may want to increase the occupancy, using
printfindiscriminately can force the compiler to dedicate many registers to a branch of the code that may only be triggered on occasion. - You have less control over when to query the error and when to report the error.
We have come across this error reporting problem in several instances and have used atomicCAS to help performantly detect soft errors. We then used pinned system memory to coordinate host-side query and soft-error reporting.
We provide this solution in a small header-only library that provides infrastructure such that you can potentially drop this asynchronous error-reporting solution into your code. Use of templating enables you to customize your error-reporting payloads, while our library handles creating and mapping system-pinned and device-side error information.
Furthermore, our library uses lambda functions to give you plenty of flexibility in triggering the error within your GPU kernels. It provides helper functions for flexibility in querying and reporting errors.
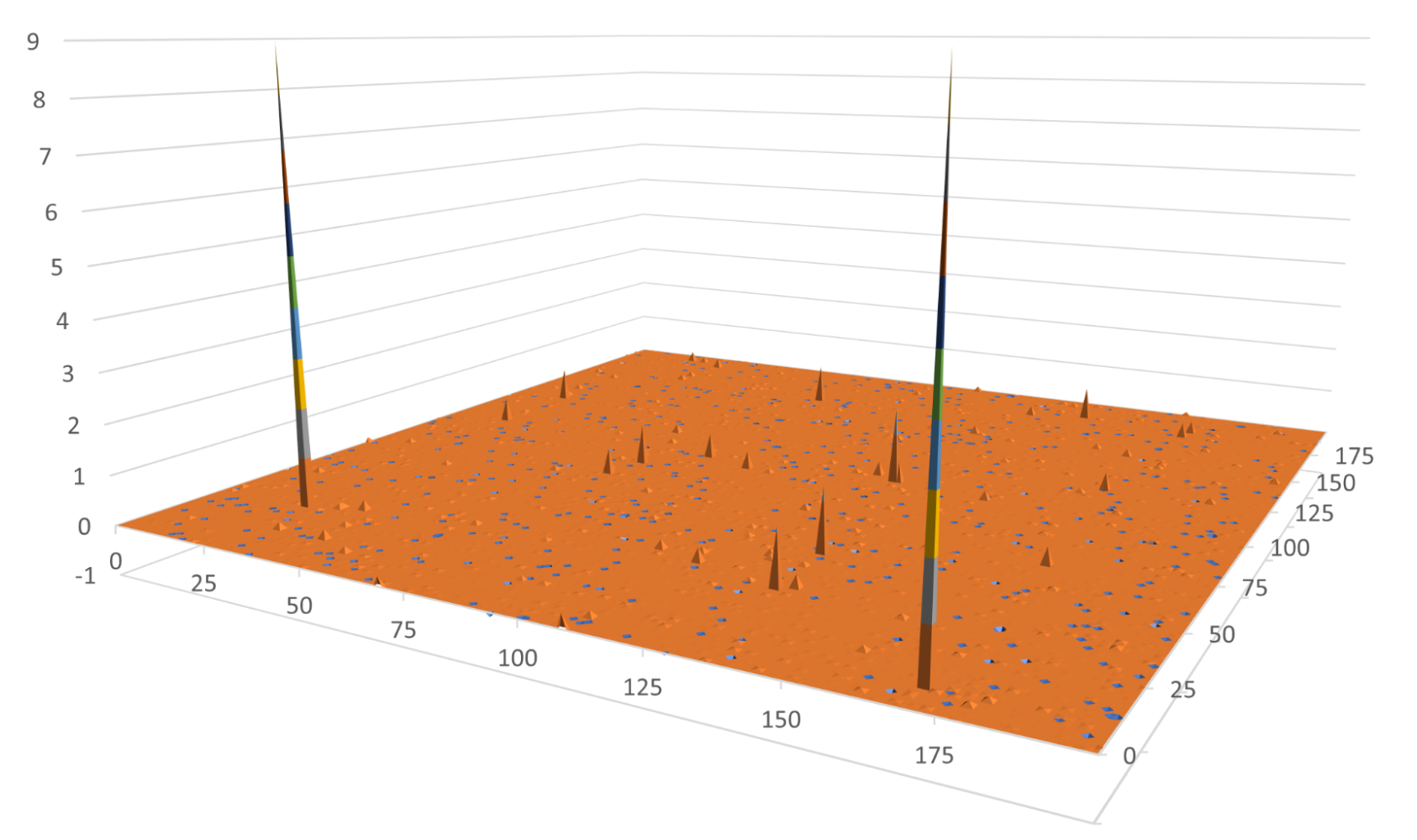
Example workload
As a demonstration, we used the following kernel to simulate a workload that produces smoothly varying results except in rare edge cases. The kernel generates some pseudo-random integers between 0 and 7210. Then it passes that integer into a function that is sharply peaked around 100. On rare occasions, this kernel generates 1e6. The rest of the time, the values are less than 1.0.
#include <iostream>
#include <stdio.h>
#include <assert.h>
#include <cuda.h>
__global__ void randomSpikeKernel(float* out, int sz)
// Generate a pseudo-random number
// Pass it into f(x) = 1/(x-100+1e-6)
// Write result to out
{
for (int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx < sz;
idx += blockDim.x * gridDim.x)
{
const int A = 187;
const int M = 7211;
int ival = ((idx + A) * A) % M;
ival = (ival*A) % M;
ival = (ival*A) % M;
float val = 1.f/(ival-100+1e-6);
//assert(val < 10000);
out[idx] = val;
}
}
We commented out a call to assert, a function callable on the GPU or the CPU that immediately halts execution and returns an error. This is one solution for error from which there is no recovery.
In many cases, it might be preferable to let the kernel run and report a soft error later. You may be interested in being notified if any errors have occurred, but not in stopping the work. Your first instinct might be to add a printf statement like the following:
__global__ void randomSpikeKernelwError(float* out, int sz)
// Generate a pseudo-random number
// Pass it into f(x) = 1/(x-100+1e-6)
// Write result to out
// In the case of a large value (>1e5) print and error, but continue
{
for (int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx < sz;
idx += blockDim.x * gridDim.x)
{
const int A = 187;
const int M = 7211;
int ival = ((idx + A) * A) % M;
ival = (ival*A) % M;
ival = (ival*A) % M;
float val = 1.f/(ival-100+1e-6);
if (val >= 10000) {
printf("val (%f) out of range for idx = %d\n",
val, idx);
}
out[idx] = val;
}
}
This is frequently an acceptable solution. But for kernels whose occupancy is limited by register use, this may have undesirable consequences. Even if the printf statement is rarely executed, the compiler must allocate registers just in case.
Registers are fast memory for use only within a thread. Data in registers can be read and written with low latency, but registers from one thread are not visible to any other thread. You can see the register requirements of a kernel at compile time by adding -Xptxas=-v to the compile line or by using NVIDIA Nsight Compute to profile the kernel.
Compile the previous code as follows:
nvcc -c -arch=sm_80 -Xptxas=-v kernel.cu
You see the following message during compilation:
ptxas info : 36 bytes gmem
ptxas info : Compiling entry function '_Z17randomSpikeKernelPfi' for 'sm_80'
ptxas info : Function properties for _Z17randomSpikeKernelPfi
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 14 registers, 364 bytes cmem[0], 8 bytes cmem[2]
ptxas info : Compiling entry function '_Z23randomSpikeKernelwErrorPfi' for 'sm_80'
ptxas info : Function properties for _Z23randomSpikeKernelwErrorPfi
16 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 24 registers, 364 bytes cmem[0], 8 bytes cmem[2]
The first kernel has no error reporting and used 14 registers. The second kernel added the printf statement for large values and the register count jumped to 24.
As each SM has a fixed amount of space for kernel registers, a kernel’s higher register requirement can limit the number of thread blocks that can be active on each SM. This can lead to exposed latency and poor performance. This example kernel is only for demonstration and is unlikely to have problems with register pressure.
It is quite common in HPC code to struggle with high register counts. Register counts can often be artificially limited during compilation, but this can have other negative consequences for performance. We discuss this in the next section.
Further, by relying on the console stream to report information, you give up some control over when you query and report potential soft errors. While reporting soft errors for several kernels or device functions running simultaneously, using a shared console stream may convolute the output.
Small improvements
If register pressure is reducing the performance of a kernel because printf consumes extra registers that are reserved but generally unused, a potential solution is to tell the compiler to restrict the number of registers either by setting the -maxregcount compile flag or by using __launch_bounds__ in the code.
This restricts the number of registers, spilling the extra registers. You only take a performance hit on the rare occasion that printf occurs. This is an essential tip for mitigating register-pressure issues generally, but they can be a blunt instrument and interfere with other register-reduction efforts.
The proposed alternative: compare and swap
An even better way to report errors of this kind is to use an atomicCAS function as an asynchronous barrier to detect the first instance of the soft error.
The CAS in atomicCAS stands for compare and swap, also commonly called compare-exchange.
atomicCAS takes a memory location, a compare value, and a new value and writes the value to the memory location only if the memory location matches the compare value. If the value read from memory is equal to the compare value provided, atomicCAS writes the new value to the memory location. Otherwise, it leaves the value unchanged. In either case, it returns the value originally read from the memory location.
Most importantly, if there is contention between threads, only one thread at a time does its full read, compare, and swap. The remaining threads read a changed value from memory and skip the write. CUDA has support for atomicCAS for 32-bit signed integers and 16-, 32-, or 64-bit unsigned integers.
In this solution, you use atomicCAS to ensure that only one thread can write an error message. All errors detected later are not reported until you clear the error. This avoids race conditions between different threads writing error messages and matches the behavior of native CUDA errors.
When an error is detected, an application typically must record some additional data—the line number, an error code, and so on. In this example, you write this additional data, called the error “payload” zero copy, as a direct write from the GPU kernel onto system-pinned CPU memory. Because the payload for soft errors is often small, you can write the payload directly, skipping an explicit memory copy.
You also track the status of this error in system-pinned memory. This makes the CPU host aware of errors generated on the GPU. Use __threadfence_system to provide a system-wide barrier to ensure that the payload is fully written before the status flag changes. This enables the host to asynchronously query the status. When the host sees that the status has changed, it can be sure that the error payload contains appropriate data.
Library
As the setup and initialization of the solution can be a little cumbersome, we have provided a templated header-only library that simplifies this process and enables you to specify custom error payloads.
We introduce two base templated types, PinnedMemory<ErrorType> and DeviceStatus<T>, that allocate and destroy system-pinned memory for the error payload as well as device-side and pinned status allocations. DeviceStatus also has a host-only status getter that enables you to query the pinned status using cuda::atomics.
The main class that you interact with is MappedErrorType, which uses the PinnedMemory and DeviceStatus classes underneath to coordinate status and payload components easily. MappedErrorType handles the initialization of the underlying type, querying errors asynchronously, querying the payload asynchronously, clearing errors, and synchronizing device-side and host-pinned statuses.
The following code example shows how an error of type RandomSpikeError can be recorded using the struct RandomSpikeError.
struct RandomSpikeError
{
int code;
int line;
int filenum;
int block;
int thread;
// payload information
int idx;
float val;
};
__global__ void randomSpikeKernelFinal(float* out, int sz, MappedErrorType<RandomSpikeError> device_error_data)
// This kernel generates a pseudo-random number
// then puts it into 1/num-100+1e-6. That curve is
// sharply peaked at num=100 where the value is 1e6.
// In the case of a large value, you want to report an
// error without stopping the kernel.
{
for (int idx = threadIdx.x + blockIdx.x * blockDim.x;
idx < sz;
idx += blockDim.x * gridDim.x)
{
const int A = 187;
const int M = 7211;
int ival = ((idx + A) * A) % M;
ival = (ival*A) % M;
ival = (ival*A) % M;
float val = 1.f/(ival-100+1e-6);
if (val >= 10000) {
report_first_error(device_error_data, [&] (auto &error){
error = RandomSpikeError {
.code = LARGE_VALUE_ERROR,
.line = __LINE__,
.filenum = 0,
.block = static_cast<int>(blockIdx.x),
.thread = static_cast<int>(threadIdx.x),
.idx = idx,
.val = val
};
});
}
out[idx] = val;
}
}
The error payload of type RandomSpikeError in pinned-memory is directly set on the device within the user-supplied lambda function.
The function report_first_error is defined as follows:
template <typename ErrorType, typename FunctionType>
inline __device__ void report_first_error(
MappedErrorType<ErrorType> & error_dat,
FunctionType func){
if(atomicCAS(reinterpret_cast<int*>(error_dat.deviceData.device_status),
static_cast<int>(ATOMIC_NO_ERROR),
static_cast<int>(ATOMIC_ERROR_REPORTED)) ==
static_cast<int>(ATOMIC_NO_ERROR) ) {
func(*error_dat.deviceData.host_data);
__threadfence_system();
error_dat.synchronizeStatus();
}
}
As you can see, using atomicCAS with the device-side status is performed first. If it is successful, the user-supplied lambda function is executed and writes to the pinned-memory. Afterward, a system-wide thread fence is used to guarantee that the function has executed before synchronizing the host-pinned status with the device-side status.
The host can then query and report the error using MappedErrorType<RandomSpikeError> directly.
int reportError( MappedErrorType<RandomSpikeError> & error_dat)
{
int retval = NO_ERROR;
if (error_dat.checkErrorReported()) {
auto & error = error_dat.get();
retval = error.code;
std::cerr << "ERROR " << error.code
<< ", line " << error.line
<< ". block " << error.block
<< ", thread " << error.thread;
if (retval == LARGE_VALUE_ERROR)
std::cerr << ", value = " << error.val;
std::cerr << std::endl;
}
return retval;
}
auto async_err = reportError(mapped_error);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: " << async_err << std::endl;
else std::cout << "No error" << std::endl;
As the errors can occur asynchronously, your application may have to properly synchronize or wait for a particular event to guarantee the kernel has finished. This is similar to the behavior of native CUDA errors.
Putting it all together
While our library simplifies much of the necessary work, here is what is happening behind the scenes so that you can extend and adjust error reporting for your needs.
Before the kernel is executed, we initialize a MappedErrorType<T> object whose host-side and device-side status is automatically initialized (ATOMIC_NO_ERROR = 0). When an error is detected in a kernel, report_first_error uses atomicCAS to mark the device-side status (ATOMIC_ERROR_REPORTED=1) and then executes the user-supplied lambda function to write the payload to system-pinned memory before applying the previously mentioned thread fence and host-device status synchronization.
A thread may only write the error data if atomicCAS returns ATOMIC_NO_ERROR, meaning that no other thread has already recorded an error. Unless you reset the status to ATOMIC_NO_ERROR, no other instances of this error are recorded. The thread that receives ATOMIC_NO_ERROR writes its error code and associated data.
To clear the data, we’ve provided a clear(cudaStream_t) method that sets the status to ATOMIC_NO_ERROR on both the host and device-side status.
To check if there has been an error from the host, our implementations of reportError use checkErrorReported, which merely checks if the host-side status is set to ATOMIC_ERROR_REPORTED. Then we call get on the payload of the error type (struct RandomSpikeError) and read the error information.
Detection of an error during kernel execution halts neither the kernel nor the host. Like native CUDA errors, the host may launch several kernels before the error in this kernel is detected.
int main(void)
{
…
// Create pinned flags/data and device-side atomic flag for CAS
auto mapped_error =
CASError::MappedErrorType<RandomSpikeError>();
auto mapped_error2 = CASError::MappedErrorType<OtherError>();
…
int async_err; // error query result
// Allocate memory and a stream
float *out, *h_out;
h_out = (float*)malloc(sizeof(float)*MAX_IDX);
cudaMalloc((void**)&out, sizeof(float)*MAX_IDX);
cudaStream_t stream; cudaStreamCreate(&stream);
CASError::checkCuda(
cudaEventCreate(&finishedRandomSpikeKernel) );
// Launch the kernel. This launch causes a
// LARGE_VALUE_ERROR
randomSpikeKernel<<<100,32,0,stream>>>(out, MAX_IDX);
randomSpikeKernelFinal<<<100,32,0,stream>>>(out, MAX_IDX,
mapped_error);
CASError::checkCuda(
cudaEventRecord(finishedRandomSpikeKernel, stream) );
// Check the error message from err_data
async_err = reportError(mapped_error);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< async_err << std::endl;
else std::cout << "No error" << std::endl;
// Launch another kernel
otherKernel<<<100,32,0,stream>>>(out, MAX_IDX,
mapped_error2);
…
async_err = reportError(mapped_error2, stream);
if (async_err != NO_ERROR)
std::cout << "ERROR! " << "code: " << async_err <<
std::endl;
else std::cout << "No error" << std::endl;
std::cout << "Launch memcpy" << std::endl;
cudaMemcpyAsync(h_out, out, sizeof(float)*MAX_IDX,
cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
async_err = reportError(mapped_error);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< async_err << std::endl;
else std::cout << "No error" << std::endl;
mapped_error.clear(stream);
async_err = reportError(mapped_error2, stream);
if (async_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< async_err << std::endl;
else std::cout << "No error" << std::endl;
int final_err = reportError(mapped_error);
if (final_err != NO_ERROR) std::cout << "ERROR! " << "code: "
<< final_err << std::endl;
else std::cout << "No error" << std::endl;
// Free memory, stream
cudaFree(out);
free(h_out);
cudaStreamDestroy(stream);
return 0;
}
In the test, you first launch the kernel that generates the error. Then you check for errors on the host thread. You are not synchronizing the host and device before this check. When a synchronization hurts performance, you may want to queue up more GPU work before you synchronize.
You’re checking for errors in this sample code to demonstrate the asynchronous error reporting. If you don’t mind a performance hit and you want the errors reported in order, add a cudaStreamSynchronize call before the call to reportError.
After checking for errors, launch another kernel, otherKernel, and check for errors again. Copy the resulting data back to the host using cudaMemcpyAsync. Synchronize the stream to ensure the data on the host is correct and check for errors again. Now you are guaranteed to catch your error.
Next, clear the error, and check for the second type of error, also guaranteed to be caught. Lastly, to show that the error has been cleared, check for errors one last time.
When this code is compiled and executed, you might see this output:
No error No error Launch memcpy ERROR 2, line 144. block 92, thread 20, value = 1e+06 ERROR! code: 2 ERROR 3, line 171, file /tmp/devblog/main.cu. block 25, thread 8 ERROR! code: 3 No error
The error was generated during the GPU execution of randomSpikeKernelFinal, but because you are not synchronizing the host and device between calls, the host thread was able to queue both kernels and memcpy immediately, without waiting for the first CUDA kernel to finish. The CPU did not detect and report the error until after the stream was synchronized.
As you have two separate types of errors, you can catch and clear each one separately. Otherwise, you only report the first error you observed of each type.
Payoff
When you compile with -Xptxas=-v, you see this output (highlights added):
ptxas info : Compiling entry function '_Z17randomSpikeKernelPfi' for 'sm_70' ptxas info : Function properties for _Z17randomSpikeKernelPfi 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads ptxas info : Used 14 registers, 364 bytes cmem[0], 8 bytes cmem[2] ptxas info : Compiling entry function '_Z23randomSpikeKernelwErrorPfi' for 'sm_70' ptxas info : Function properties for _Z23randomSpikeKernelwErrorPfi 16 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads ptxas info : Used 24 registers, 364 bytes cmem[0], 8 bytes cmem[2] ptxas info : Compiling entry function '_Z22randomSpikeKernelFinalPfi' for 'sm_70' ptxas info : Function properties for _Z22randomSpikeKernelFinalPfi 0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads ptxas info : Used 18 registers, 364 bytes cmem[0], 8 bytes cmem[2]
The first kernel has no error reporting. The second reports errors using printf. The third and last kernel uses the new method described earlier. The following table shows the register counts from the earlier output.
| Kernel | Error report method | Registers |
randomSpikeKernel | None | 14 |
randomSpikeKernelwError | printf | 24 |
randomSpikeKernelFinal | atomicCAS | 18 |
Checking for errors and reporting using atomicCAS increased the register count by four registers compared with 10 new registers when using printf. In this small case, register count does not likely affect performance. For kernels where register usage is a performance issue, this new error reporting can make a significant difference.
A real-world example
Here’s an example of the difference that this new method can make in real code.
We tested this library in the wild within hpMusic, a higher-order computational fluid dynamics simulation code example. In the baseline code, a kernel with several printf statements for reporting rare soft errors used 248 registers. By commenting out printf (no error reporting), ncu reported 148 registers for the kernel.
Lastly, by dropping in our library, ncu reported the compiled kernel also as using 150 registers. Because these kernels were register-constrained, reducing register usage by avoiding printf in this performance critical kernel made a significant impact on runtime.
| Kernel variation | Registers | Occupancy | Kernel runtime (ms) |
| Printf | 248 | 11.97% | 293.5 |
| No reporting | 148 | 17.83% | 243.6 |
| print-alternative | 150 | 17.80% | 239.5 |
| printf and launch_bounds | 168 | 17.25% | 299.0 |
While the hpMusic developers are domain experts who also write GPU applications, they were surprised by the performance difference due to using printf in register-constrained kernels.
Conclusion
If you are reporting soft errors or other infrequent kernel information, download the headers and the example in this post and try this out for yourself. We are always interested in feedback, so send a message and let us know how it worked!
