
Embeddings play a key role in deep learning recommender models. They are used to map encoded categorical inputs in data to numerical values that can be processed by the math layers or multilayer perceptrons (MLPs).
Embeddings often constitute most of the parameters in deep learning recommender models and can be quite large, even reaching into the terabyte scale. It can be difficult to fit them in a single GPU’s memory during training.
As such, modern recommenders may require a combination of model parallel and data parallel distributed training approaches to achieve reasonable training times, and the best utilization of available GPU compute.
NVIDIA Merlin Distributed-Embeddings, a library for training large embedding based (for example, recommenders) models in TensorFlow 2 enables you to accomplish this easily with just a few lines of code.
Background
With data-parallel distributed training on GPUs, the whole model is replicated on each GPU worker. A batch of data is split among the multiple GPUs during training, and each device independently operates on its own shard of data.
This allows scaling computations to higher quantities of data with larger batches. The gradients calculated during backpropagation are accumulated across all devices using a reduction operation (for example, horovod.tensorflow.allreduce) for a synchronous parameter update.
With model parallel distributed training, the model parameters are split between various workers. This is a more suitable way to distribute large embedding tables. Training requires using an all-to-all communication primitive (for example, horovod.tensorflow.alltoall) such that workers can get access to the parameters that are not in their partition.
In a related previous post, Training a Recommender System on DGX A100 with 100B+ Parameters in TensorFlow 2, Tomasz discussed how distributing embeddings for a 113 billion-parameter DLRM model across multiple NVIDIA GPUs helped achieve a 672x speedup over a CPU-only solution. This significant improvement can potentially bring down training times from days to minutes! This is accomplished by distributing embedding tables through model parallelism and performing the much-smaller math-intensive MLP layer computation through data parallelism.
Compared to storing the embeddings in CPU memory, this hybrid approach enables you to use the high-memory bandwidth of the GPU memory for memory-bound embedding lookups. It also accelerates the MLP layers using the compute powers among several GPU devices. For reference, an NVIDIA A100-80GB GPU has 80 GB HBM2 memory with a bandwidth at over 2 TB/s).
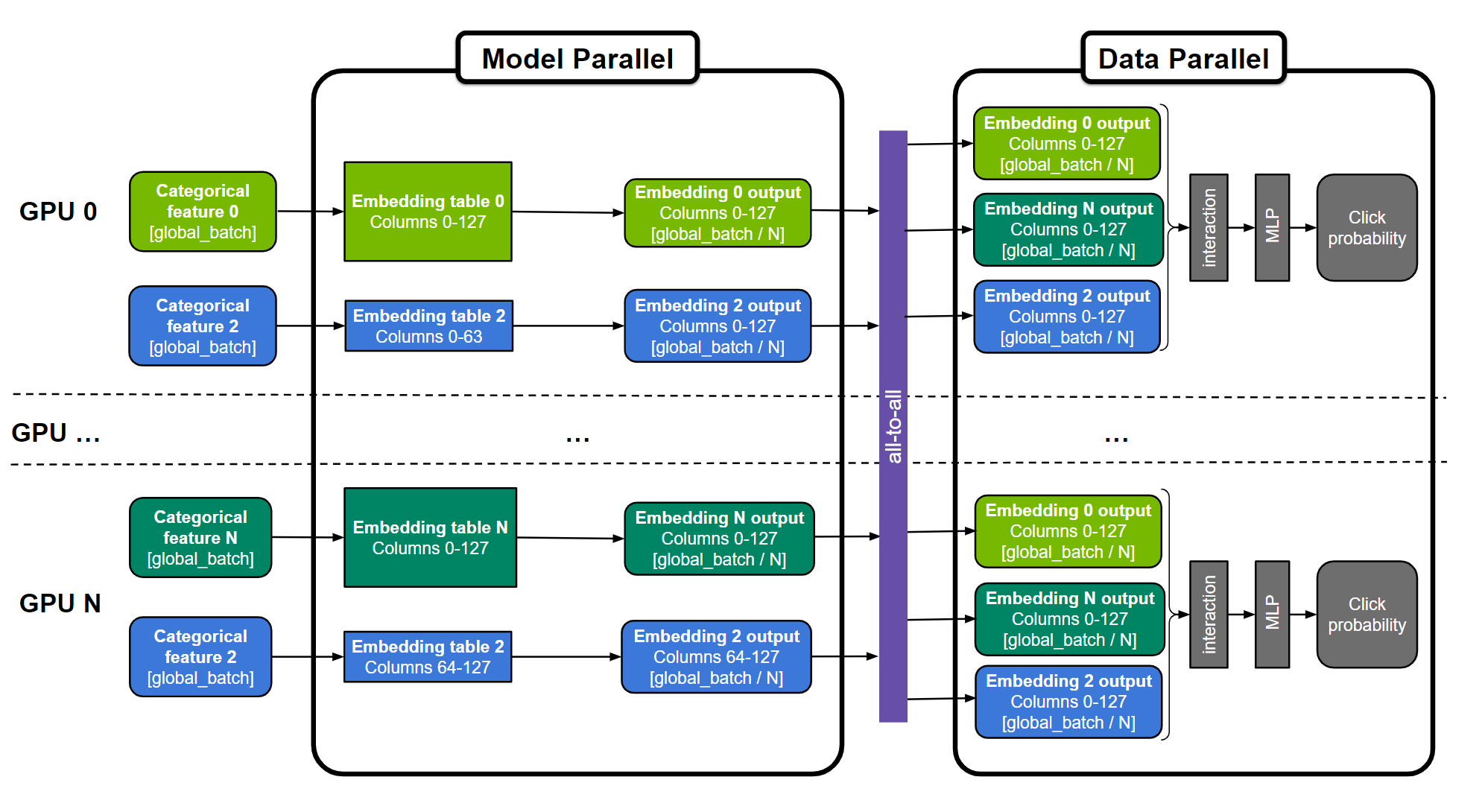
The embedding tables can be split “table-wise” (for example, embedding tables 0 and N), “column-wise” (for example, embedding table 2), or “row-wise”. The MLP layers are replicated across all GPUs. Numerical features can be fed directly into the MLP layers and are not represented in the figure.
However, implementing such a complex hybrid parallel training approach is not trivial and requires a domain expert to engineer several hundred lines of low-level code to develop and optimize training.
To make it more widely accessible, the NVIDIA Merlin Distributed-Embedding library provides an easy-to-use wrapper to democratize model parallelism in TensorFlow 2 with only three lines of Python code. It provides a scalable model parallel wrapper that automatically distributes embedding tables to multiple GPUs, in addition to some efficient embedding operations that cover and extend TensorFlow’s embedding functionalities. Here’s how it enables hybrid-parallelism.
Distributed model parallel
NVIDIA Merlin Distributed-Embeddings provides the distributed_embeddings.dist_model_parallel module. It helps distribute embeddings across several GPU workers without any complex code to handle cross-worker communication with primitives like all2all. The following code example shows the usage of this API:
import dist_model_parallel as dmp
class MyEmbeddingModel(tf.keras.Model):
def __init__(self, table_sizes):
...
self.embedding_layers = [tf.keras.layers.Embedding(input_dim, output_dim) for input_dim, output_dim in table_sizes]
# 1. Add this line to wrap list of embedding layers used in the model
self.embedding_layers = dmp.DistributedEmbedding(self.embedding_layers)
def call(self, inputs):
# embedding_outputs = [e(i) for e, i in zip(self.embedding_layers, inputs)]
embedding_outputs = self.embedding_layers(inputs)
...
To run the dense layers in a data-parallel fashion with Horovod, replace Horovod’s Distributed GradientTape and broadcast methods with their equivalent in Distributed Embeddings. The following example has been taken directly from the Horovod documentation and modified accordingly.
@tf.function
def training_step(inputs, labels, first_batch):
with tf.GradientTape() as tape:
probs = model(inputs)
loss_value = loss(labels, probs)
# 2. Change Horovod Gradient Tape to dmp tape
# tape = hvd.DistributedGradientTape(tape)
tape = dmp.DistributedGradientTape(tape)
grads = tape.gradient(loss_value, model.trainable_variables)
opt.apply_gradients(zip(grads, model.trainable_variables))
if first_batch:
# 3. Change Horovod broadcast_variables to dmp's
# hvd.broadcast_variables(model.variables, root_rank=0)
dmp.broadcast_variables(model.variables, root_rank=0)
return loss_value
With these minor changes, you are all set with a hybrid-parallel training step!
We also provide complete examples for training a DLRM model with Criteo 1TB click-logs data, as well as synthetic data that scales the model size up to 22.8 TiB.
Performance
To demonstrate the benefits of using NVIDIA Merlin Distributed-Embeddings, we show benchmarks on a DLRM model trained on the Criteo 1TB dataset, as well as various synthetic models with up to ~3 TiB embedding table sizes.
DLRM benchmark on Criteo dataset
Benchmarks indicate that we retain performance similar to expert engineered code with a much simpler API. The NVIDIA DeepLearningExamples DLRM code that uses TensorFlow 2 has now also been updated to leverage hybrid-parallel training with NVIDIA Merlin Distributed-Embeddings. For more information, see our previous post, Training a Recommender System on DGX A100 with 100B+ Parameters in TensorFlow 2.
The benchmarks section in the README provides more insight into performance numbers.
A DLRM model with 113 billion parameters (421 GiB model size) was trained on the Criteo Terabyte Click Logs dataset, over three different hardware setups:
- A CPU-only solution.
- A single-GPU solution, where CPU memory is used to store the largest embedding tables.
- A hybrid-parallel solution using an NVIDIA DGX A100-80GB with 8 GPUs. This leverages the model parallel wrapper and the Embedding API provided by NVIDIA Merlin Distributed-Embeddings.
| Hardware | Description | Training Throughput (samples/second) | Speedup over CPU |
| 2 x AMD EPYC 7742 | Both MLP layers and embeddings on CPU | 17.7k | 1x |
| 1 x A100-80GB; 2 x AMD EPYC 7742 | Large embeddings on CPU, everything else on GPU | 768k | 43x |
| DGX A100 (8xA100-80GB) | Hybrid parallel with NVIDIA Merlin Distributed-Embeddings, whole model on GPU | 12.1M | 683x |
We observe that a Distributed-Embeddings solution on a DGX-A100 provides a whopping 683x speedup over a CPU-only solution! We also notice a significant improvement in performance over a single-GPU solution. This is because retaining all the embeddings in GPU memory eliminates the overhead of embedding lookups over the CPU-GPU interface.
Synthetic models benchmark
To demonstrate the scalability of the solution further, we created synthetic DLRM models of varying sizes (Table 2). For more information about model generation methodology and the training script, see the NVIDIA-Merlin/distributed-embeddings GitHub repo.
| Model | Total number of embedding tables | Total embedding size (GiB) |
| Tiny | 55 | 4.2 |
| Small | 107 | 26.3 |
| Medium | 311 | 206.2 |
| Large | 612 | 773.8 |
| Jumbo | 1,022 | 3,109.5 |
Each synthetic model was trained using one or more DGX-A100-80GB nodes, with a global batch size of 65,536, and the Adagrad optimizer. You can see from Table 3 that NVIDIA Merlin Distributed-Embeddings can easily train terabyte-scale models on hundreds of GPUs.
| Model | Training step time (ms) | ||||
| 1 GPU | 8 GPU | 16 GPU | 32 GPU | 128 GPU | |
| Tiny | 17.6 | 3.6 | 3.2 | ||
| Small | 57.8 | 14.0 | 11.6 | 7.4 | |
| Medium | 64.4 | 44.9 | 31.1 | 17.2 | |
| Large | 65.0 | 33.4 | |||
| Jumbo | 102.3 | ||||
Table 3. Training step time (ms) for synthetic models on various hardware configurations
On the other hand, even for models that can fit into a single GPU, Distributed-Embeddings’ model parallelism still provides substantial speedup with multi-GPU, compared to conventional data parallelism. This is shown in Table 4 where a tiny model runs on DGX A100-80GB.
| Solution | Training step time (ms) | |||
| 1 GPU | 2 GPU | 4 GPU | 8 GPU | |
| NVIDIA Merlin Distributed Embeddings Model Parallel | 17.7 | 11.6 | 6.4 | 4.2 |
| Native TensorFlow Data Parallel | 19.9 | 20.2 | 21.2 | 22.3 |
Table 4. Comparing training step time (ms) for the “Tiny” model (4.2GiB) between an NVIDIA Merlin Distributed Embeddings Model Parallel and a Native TensorFlow Data Parallel solution for embeddings
A global batch size of 65,536 and the Adagrad optimizer were used for this experiment.
Conclusion
In this post, we introduced the NVIDIA Merlin Distributed-Embeddings library, which enables scalable and efficient model-parallel training of embedding-based, deep learning models on NVIDIA GPUs with just a few lines of code. To get started, try the examples for scalable training with synthetic data and training a DLRM model on Criteo data.