
The NVIDIA Arm HPC Developer Kit is an integrated hardware and software platform for creating, evaluating, and benchmarking HPC, AI, and scientific computing applications on a heterogeneous GPU- and CPU-accelerated computing system. NVIDIA announced its availability in March of 2021.
The kit is designed as a stepping stone to the next-generation NVIDIA Grace Hopper Superchip for HPC and AI applications. It can be used to identify non-obvious x86 dependencies and ensure software readiness ahead of NVIDIA Grace Hopper systems available in 1H23. For more information, see the NVIDIA Grace Hopper Superchip Architecture whitepaper.
The Oak Ridge National Laboratory Leadership Computing Facility (OLCF) integrated the NVIDIA Arm HPC Developer Kit into their existing Wombat Arm cluster. Application teams worked to build, validate, and benchmark several HPC applications to evaluate application readiness for the next generation of Arm- and GPU-based HPC systems.
The teams have jointly submitted for publication in the IEEE Transactions on Parallel and Distributed Systems Journal, demonstrating that the suite of software and tools available for GPU-accelerated Arm systems are ready for production environments. For more information, see Application Experiences on a GPU-Accelerated Arm-based HPC Testbed.
OLCF Wombat cluster
Wombat is an experimental cluster equipped with Arm-based processors from various vendors. It is operational since 2018. The cluster is managed by the OLCF and is freely accessible to users and researchers.
At the time of the study, the cluster consisted of three types of compute nodes:
- Four HPE Apollo 70 nodes, each equipped with dual Cavium (now Marvell) ThunderX2 CN9980 processors and two NVIDIA V100 Tensor Core GPUs
- Sixteen HPE Apollo 80 nodes, each equipped with a single Fujitsu A64FX processor
- Eight NVIDIA Arm HPC Developer Kit nodes, each equipped with a single Ampere Altra Q80–30 CPU and two NVIDIA A100 GPUs
These nodes share a common TX2-based login node, Arm-based, and all nodes are connected through InfiniBand EDR and HDR.
HPC application evaluation
Eleven different teams carried out the evaluation work
- Oak Ridge National Laboratory
- Sandia National Laboratories
- University of Illinois at Urbana – Champaign
- Georgia Institute of Technology
- University of Basel
- Swiss National Supercomputing Center (SNSC)
- Helmholtz-Zentrum Dresden-Rossendorf
- University of Delaware
- NVIDIA
Table 1 summarizes the final list of applications and their various characteristics. The applications cover eight different scientific domains and include codes written in Fortran, C, and C++. The parallel programming models used were MPI, OpenMP/OpenACC, Kokkos, Alpaka, and CUDA. No changes were made to the application codes during the porting activities. The evaluation process primarily focused on application porting and testing, with less emphasis on absolute performance considering the experimental nature of the testbed.
| Application | Science domain | Language | Parallel programming model |
| ExaStar | Stellar Astrophysics | Fortran | OpenACC, OpenMP offload |
| GPU-I-TASSER | Bioinformatics | C | OpenACC |
| LAMMPS | Molecular Dynamics | C++ | OpenMP, KOKKOS |
| MFC | Fluid Dynamics | Fortran | OpenACC |
| MILC | QCD | C/C++ | CUDA |
| MiniSweep | Sn Transport | C | OpenMP, CUDA |
| NAMD/VMD | Molecular Dynamics | C++ | CUDA |
| PIConGPU | Plasma Physics | C++ | Alpaka, CUDA |
| QMCPACK | Chemistry | C++ | OpenMP offload, CUDA |
| SPECHPC 2021 | Variety of Apps | C/C++/Fortran | OpenMP offload, OpenMP |
| SPH-EXA2 | Hydrodynamics | C++ | OpenMP, CUDA |
This post covers the results for four of the applications. For more information about the other applications, see Application Experiences on a GPU-Accelerated Arm-based HPC Testbed.
Bioinformatics for protein structure and function prediction
GPU-I-TASSER is a GPU-capable bioinformatics method for protein structure and function prediction. The I-TASSER suite predicts protein structures through four main steps. These include threading template identification, iterative structure assembly simulation, model selection, and refinement. The final step is structure-based function annotation. The structure folding and reassembling stage is conducted by replica exchange Monte Carlo simulations.
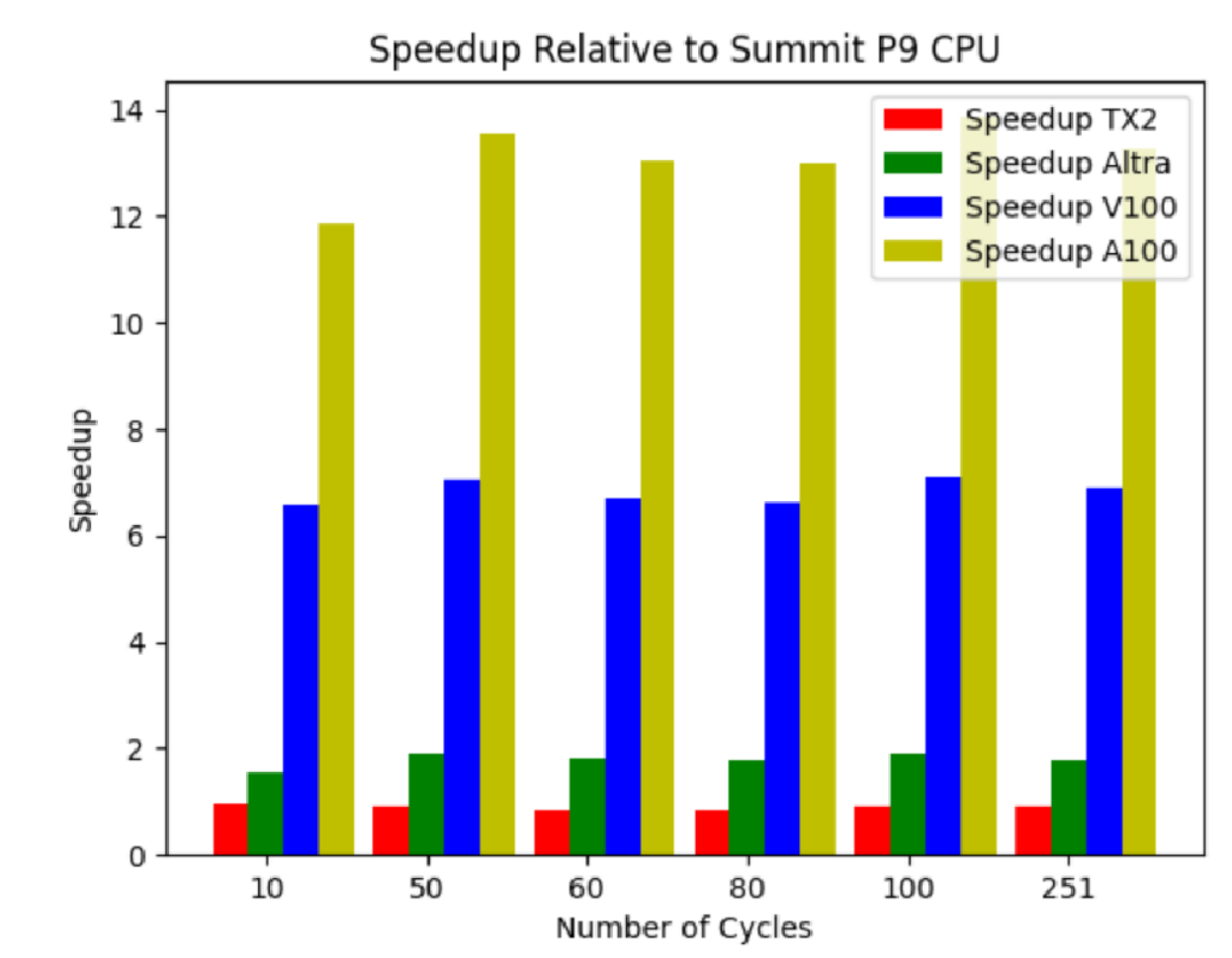
Figure 1 shows the performance of Wombat’s ThunderX2 and Ampere Altra processors and NVIDIA A100 and V100 GPUs relative to the POWER9 processor on Summit. For Ampere Altra, NVIDIA V100, and NVIDIA A100, speedups of 1.8x, 6.9x, and 13.3x, respectively, were observed.
Fluid flow solver for physical problems
Multi-Component Flow Code (MFC) is an open-source, fluid flow solver that provides high-order accurate solutions to a wide variety of physical problems, including multi-phase compressible flows and sub-grid dispersions.
Table 2 shows the average wall-clock times and relative performance metrics for the different hardware. The Time column has little absolute meaning, with the relative performance being the most meaningful (also shown in the last column). All comparisons use either the NVHPC v22.1 or GCC v11.1 compilers as indicated. The CPU wall-clock times are normalized by the number of CPU cores per chip. The results show that the A100 GPU is 1.72x faster than the V100 on Summit.
| Compiler | Time (sec) | Speedup | |
| NVIDIA A100 | NVHPC | 0.28 | 15.71 |
| NVIDIA V100 | NVHPC | 0.5 | 8.80 |
| 2xXeon 6248 | NVHPC | 2.7 | 1.63 |
| 2xXeon 6248 | GCC | 2.1 | 2.10 |
| Ampera Altra | NVHPC | 3.9 | 1.13 |
| Ampera Altra | GCC | 2.7 | 1.63 |
| 2xPOWER9 | NVHPC | 4.4 | 1.00 |
| 2xPOWER9 | GCC | 3.5 | 1.26 |
| 2xThunderX2 | NVHPC | 21 | 0.21 |
| 2xThunderX2 | GCC | 5.4 | 0.81 |
| A64FX | NVHPC | 4.3 | 1.02 |
| A64FX | GCC | 13 | 0.34 |
Bold indicates the use of NVIDIA Arm HPC Developer Kit hardware.
NAMD and VMD for biomolecular dynamics simulation and visualization
NAMD and VMD are biomolecular modeling applications for molecular dynamics simulation (NAMD) and for preparation, analysis, and visualization (VMD). Researchers use NAMD and VMD to study biomolecular systems ranging from individual proteins, large multiprotein complexes, photosynthetic organelles, and entire viruses.
Table 3 shows that the simulations on A100 for NAMD are as much as 50% faster than on the V100. Similar performance is demonstrated between Cavium ThunderX2 and IBM POWER9, with the latter benefiting from its low=latency NVIDIA NVLink connection between CPU and GPU.
| CPU | GPU | Compiler | Perf (ns/day) |
| 2x EPYC 7742 | A100-SXM4 | GCC | 15.87 |
| 1x Ampera Altra | A100-PCIe | GCC | 15.09 |
| 2x Xeon 6134 | A100-PCIe | ICC | 14.52 |
| 2x POWER9 | V100-NVLINK | XLC | 10.26 |
| 2x ThunderX2 | V100-PCIe | GCC | 9.43 |
1M-atom STMV simulation, NVE ensemble with 12A cutoff, rigid bond constraints, multiple time stepping with 2fs fast time step, and 4fs for PME.
Bold indicates the use of NVIDIA Arm HPC Developer Kit hardware.
For VMD, the GPU-accelerated results in Table 4 showcase the performance gains provided by the much higher peak arithmetic throughput and memory bandwidth provided by GPUs, relative to existing CPU platforms. The GPU molecular orbital results highlight GPU performance and host-GPU interconnect bandwidth.
| CPU | Compiler | SIMD | Time (sec) |
| AMD TR 3975WX | ICC | AVX2 | 1.32 |
| AMD TR 3975WX | ICC | SSE2 | 2.89 |
| 1x Ampere Altra | ArmClang | NEON | 1.35 |
| 2x ThunderX2 | ArmClang | NEON | 3.02 |
| A64FX | ArmClang | SVE | 4.15 |
| A64FX | ArmClang | NEON | 13.89 |
| 2x POWER9 | ArmClang | VSX | 6.43 |
Bold indicates the use of NVIDIA Arm HPC Developer Kit hardware.
QMCPACK
QMCPACK is an open-source, high-performance Quantum Monte Carlo (QMC) package that solves the many-body Schrödinger equation using a variety of statistical approaches. The few approximations made in QMC can be systematically tested and reduced. This potentially enables the uncertainties in the predictions to be quantified at a trade-off of the significant computational expense compared to more widely used methods such as density functional theory.
Applications include weakly bound molecules, two-dimensional nanomaterials, and solid-state materials such as metals, semiconductors, and insulators.
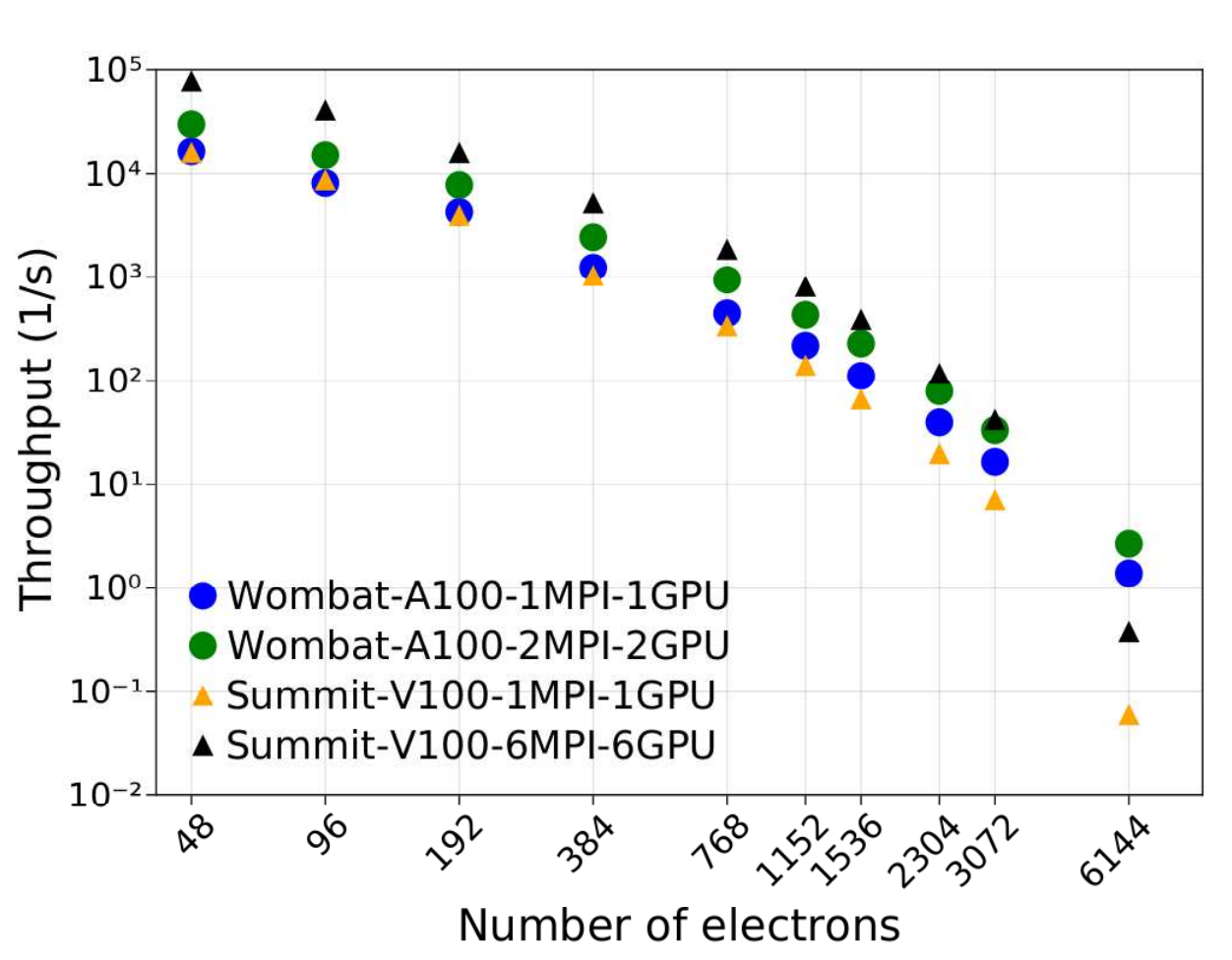
As shown in Figure 2, single A100 GPU runs on Wombat outperform those on V100 GPUs, with significantly larger throughput for nearly all problem sizes. Wombat’s A100 2 GPUs are significantly more performant for the largest and most computationally challenging case. For these system sizes, greater GPU memory is the most significant factor in increased performance.
NVIDIA Arm HPC Developer Kit evaluation results
The research teams working with the NVIDIA Arm HPC Developer Kit as part of the Wombat cluster said, “In our deployment of Wombat testbed nodes incorporating NVIDIA GPUs, we found that general cluster setup was made easier by contributions across the stack from Arm ServerReady firmware OSes, software, libraries, and end-user packages.”
“Many of the GPU-accelerated applications tested in this study derived most of their performance from application kernels optimized for the GPU architecture,” they added. “This does not negate the importance of testing new Arm and GPU platforms. We noted that the biggest limitations seemed to be related to limited GPU memory sizes and the mechanisms used to migrate and keep data near the GPU accelerators.”
The path to NVIDIA Grace Hopper systems
The NVIDIA Arm HPC Developer Kit was developed to offer a stable hardware and software platform for the development and performance analysis of accelerated HPC, AI, and scientific computing applications in the Arm ecosystem.
The NVIDIA Grace Hopper Superchip combines the high single-threaded performance of 72 Arm Neoverse V2 CPU cores with the next generation of NVIDIA Hopper H100 GPUs to offer unparalleled performance for HPC and AI applications. The NVIDIA Grace Hopper Superchip innovates by connecting the CPU to the GPU through NVLink-C2C, which is 7x faster than the PCIe Gen5 and supports 3.5 TB/s of memory bandwidth through LPDDR5X and HBM3 memory.
The NVIDIA Grace Hopper Superchip has already been adopted by leading HPC customers, including the Swiss National Supercomputing Centre (CSCS), Los Alamos National Laboratory (LANL), and King Abdullah University of Science and Technology (KAUST).
Systems based on the NVIDIA Grace Hopper Superchip will be available from leading original equipment manufacturers in the first half of 2023. If you are interested in getting a head start on moving applications to the Arm ecosystem, you can still purchase an NVIDIA Arm HPC Developer Kit from Gigabyte Systems.
For more information about how the NVIDIA Grace Hopper Architecture delivers next-generation performance and ease of programming, see the NVIDIA Grace Hopper Superchip Architecture whitepaper.
