
The NVIDIA BlueField DPU (data processing unit) can be used for network function acceleration. This network offloading is possible using DPDK and the NVIDIA DOCA software framework.
In this series, I built an app and offloaded it two ways, through the use of DPDK and the NVIDIA DOCA SDK libraries. I recorded each step as a separate code patch and provided the complete steps in each series. This shows you what it takes to program the BlueField DPU and the choice for the most elegant option for your unique use case. For part 2, see Developing Applications with NVIDIA BlueField DPU and NVIDIA DOCA Libraries.
Use case
First, I needed a simple yet meaningful use case for deploying an application on the DPU. I chose policy-based routing (PBR) to steer traffic to different gateways based on Layer 3 and Layer 4 packet attributes, overriding (or supplementing) the gateway chosen by the X86-host. This can be done for a variety of reasons in the real world, including the following examples:
- Sending select host traffic to an external firewall for additional auditing
- Enhanced load balancing to anycast servers
- Applying QoS
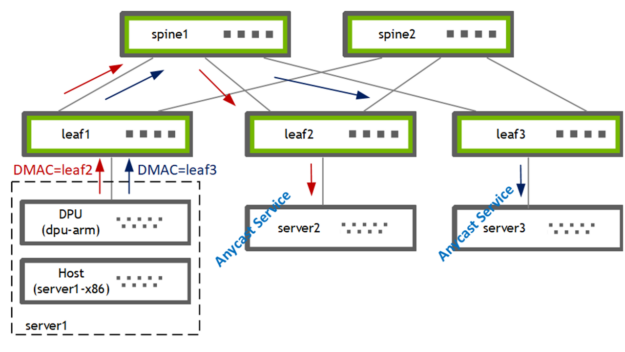
I used PBR on the DPU (bf2-arm) to steer traffic from the host (server1-x86) to one of the two gateways [leaf2, leaf3]. The leaf switch subsequently forwards the traffic to its locally attached anycast service provider [server2, server3].
Building the application
First question: do I write a brand-new app or do I offload an existing one?
I decided to offload the PBR functionality of my favorite open-source routing stack, FRRouting (FRR). This allows me to extend an existing codebase and provides a nice contrast to the existing sample apps. FRR has an infrastructure for multiple dataplane plugins so DPDK and DOCA can be easily added as new FRR plugins.
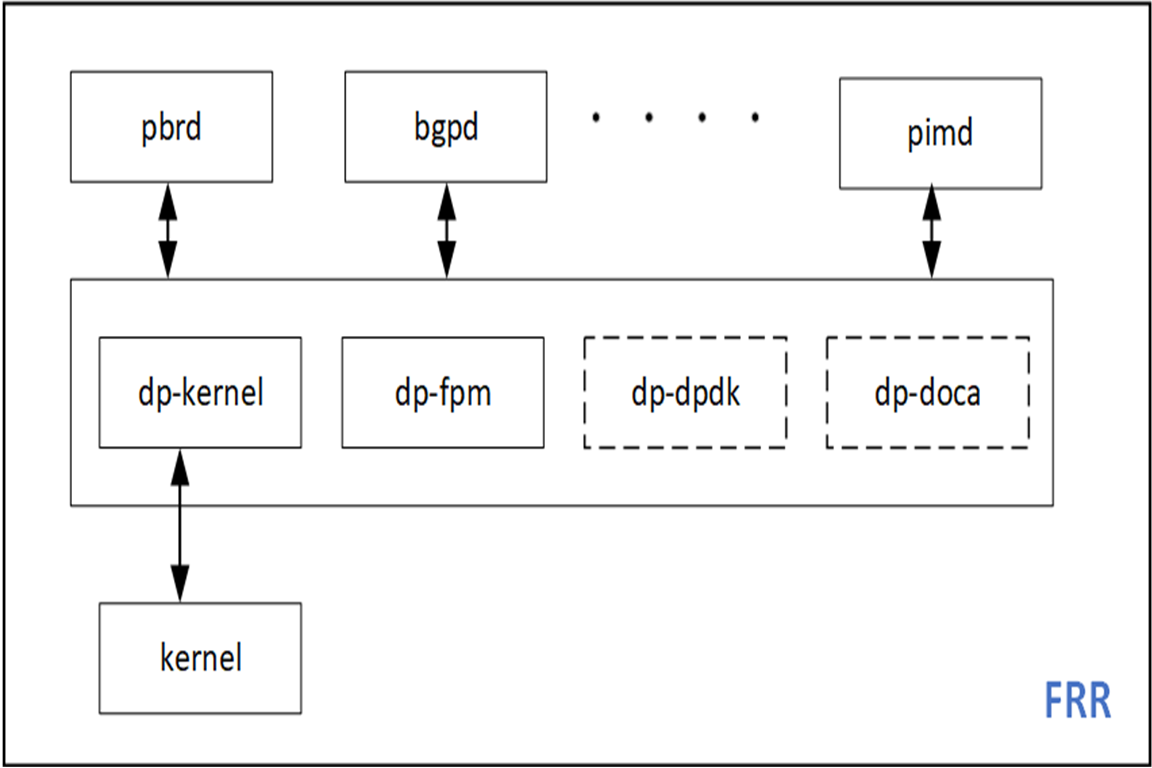
DPU application prototyping
In this section, I walk through the prep work needed for creating an app with DPU hardware acceleration.
DPU hardware
I have a BlueField-2 DPU hosted by an x86 server. This DPU has two 25G uplinks and an Arm CPU with 8G RAM. For more information about hardware installation, see the DOCA SDK docs. You can alternately bootstrap your setup using the DPU PocKit.
I installed the BlueField boot file (BFB), which provides the Ubuntu OS image for the DPU and comes with the libraries for DOCA-1.2 and DPDK-20.11.3.
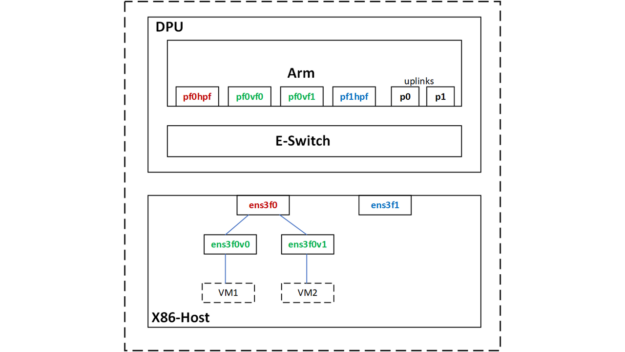
Using SR-IOV, I created two virtual function (VF) interfaces on the host for two VMs.
root@server1-x86:~# echo 2 > /sys/class/net/ens3f0/device/sriov_numvfs
The host physical and virtual functions are mapped to the following netdev representors on the DPU-Arm CPU.
|
Netdev Type |
Host netdev |
DPU netdev |
|
PF |
ens3f0 [vf0, vf1] |
pf0hpf |
|
VF |
ens3f0v0 |
pf0vf0 |
|
VF |
ens3f0v1 |
pf0vf1 |
Prototyping using the DPDK testpmd app
First, I prototyped my use case using DPDK’s testpmd, which is available on the DPU under the /opt/mellanox/ directory.
For any DPDK application, including testpmd, you must set up hugepages.
root@dpu-arm:~# echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
Optionally, persist the config so that it survives a DPU reboot.
root@dpu-arm:~# echo "vm.nr_hugepages = 1024" > /etc/sysctl.d/99-hugepages.conf
Fire up testpmd.
root@dpu-arm:~# /opt/mellanox/dpdk/bin/dpdk-testpmd -- --total-num-mbufs=100000 --flow-isolate-all -i
Testpmd is memory hungry and allocates a cool 3.5G by default. As I didn’t need to process data traffic in the CPU, I allocated a total-mem value of 200M, where total-mem = total-num-mbufs * mbuf-size (the default mbuf-size is 2048 bytes). I also used flow-isolation because I had to send ARP packets up to the kernel networking stack on the DPU, for PBR next-hop resolution). The -i option drops you into the testpmd interactive shell after the initialization is complete.
As a part of the rte_eal initialization done by testpmd, the mlx5_pci devices are probed and the DPDK ports populated.
testpmd> show port summary all
Number of available ports: 6
Port MAC Address Name Driver Status Link
0 04:3F:72:BF:AE:38 0000:03:00.0 mlx5_pci up 25 Gbps
1 4A:6B:00:53:79:E5 0000:03:00.0_representor_vf4294967295 mlx5_pci up 25 Gbps
2 62:A1:93:8D:68:C4 0000:03:00.0_representor_vf0 mlx5_pci up 25 Gbps
3 0A:8E:97:F5:C0:41 0000:03:00.0_representor_vf1 mlx5_pci up 25 Gbps
4 04:3F:72:BF:AE:39 0000:03:00.1 mlx5_pci up 25 Gbps
5 D2:0B:15:45:94:E8 0000:03:00.1_representor_vf4294967295 mlx5_pci up 25 Gbps
testpmd>
The DPDK ports that you see here correspond to the PF/VF representors and the two uplinks.
| DPDK port |
DPU netdev |
Comments |
|
0 |
p0 |
25G uplink attached to leaf1 |
|
1 |
pf0hpf | |
|
2 |
pf0vf0 |
VM1 |
|
3 |
pf0vf1 |
VM2 |
|
4 |
p1 | |
|
5 |
pf1hpf |
Flow creation
Next, I set up the PBR rule as a rte_flow by defining the ingress port, source IP, destination IP, protocol, and port. Along with that, I defined the action to take on matching packets. The source and destination MACs are rewritten, the TTL is decremented, and the egress port is set to the physical uplink, p0.
In-port=pf0vf0, match [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53], actions [dec-ttl, set-src-mac=p0-mac, set-dst-mac=leaf2-MAC, out-port=p0]
This PBR rule receives UDP and DNS traffic from VM1 and sends it to a specific GW (leaf2, server2). I also attached a counter-action to the flow for easy troubleshooting.
testpmd> flow create 2 ingress transfer pattern eth / ipv4 src is 172.20.0.8 dst is 172.30.0.8 proto is 17 / udp dst is 53 / end actions dec_ttl / set_mac_src mac_addr 00:00:00:00:00:11 / set_mac_dst mac_addr 00:00:5e:00:01:fa / port_id id 0 / count / end
Flow rule #0 created
testpmd>
The DPU can operate in the DPU-switch or DPU-NIC modes. In this use case, I had to redirect traffic from the X86-host to the 25G-uplink, after a few packet modifications. So, I conceptually used it in the switch or FDB mode. There is no additional configuration to setting up this mode beyond using the right rte_flow attribute, which in this case is transfer.
Flow verification
I sent some traffic from VM1 to see if it matched the flow that I created with the testpmd flow query <port-id, flow-id> command.
testpmd> flow query 2 0 count
COUNT:
hits_set: 1
bytes_set: 1
hits: 22
bytes: 2684
testpmd>
The flow is matched, and traffic is seen on leaf2/server2 with the modified packet headers. The traffic that is being steered is DNS, so to test the flow, I sent DNS requests from VM1. To have some control over the traffic rate and other packet fields, I used mz for test traffic generation.
ip netns exec vm1 mz ens3f0v0 -a 00:de:ad:be:ef:01 -b 00:de:ad:be:ef:02 -A 172.20.0.8 -B 172.30.0.8 -t udp "sp=25018, dp=53" -p 80 -c 0 -d 1s
An additional sanity check is to see if this flow is really offloaded. There are two ways to do that:
- Use
tcpdumpon the Arm CPU to ensure that this packet flow is NOT received by the kernel. - Check if the hardware eSwitch is programmed with the flow.
mlx_steering_dump allows you to look at the hardware programmed flows. Download and install the tool using git.
root@dpu-arm:~# git clone https://github.com/Mellanox/mlx_steering_dump
Verify the flows programmed in hardware using the mlx_steering_dump_parser.py script.
root@dpu-arm:~# ./mlx_steering_dump/mlx_steering_dump_parser.py -p `pidof dpdk-testpmd` -f /tmp/dpdkDump
domain 0xbeb3302, table 0xaaab23e69c00, matcher 0xaaab23f013d0, rule 0xaaab23f02650
match: outer_l3_type: 0x1, outer_ip_dst_addr: 172.30.0.8, outer_l4_type: 0x2, metadata_reg_c_0: 0x00030000, outer_l4_dport: 0x0035, outer_ip_src_addr: 172.20.0.8
action: MODIFY_HDR, rewrite index 0x0 & VPORT, num 0xffff & CTR(hits(154), bytes(18788)),
This command dumps all the flows programmed by the testpmd app. And we can see the outer IP header matches that we setup – [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53]. The flow counters are read and cleared as a part of the dump.
Prototyping, the final step of the app design-thinking process is now complete. I now know I can build a PBR rule in DPDK, that is installed in hardware and is taking action on our packets. Now to add the DPDK dataplane in the next section.
Building the DPDK dataplane plugin
In this section, I walk through the steps for PBR hardware acceleration on the DPU by adding a DPDK dataplane plugin to Zebra. I broke these steps into individual code-commits and the entire patch-set is available as a reference.
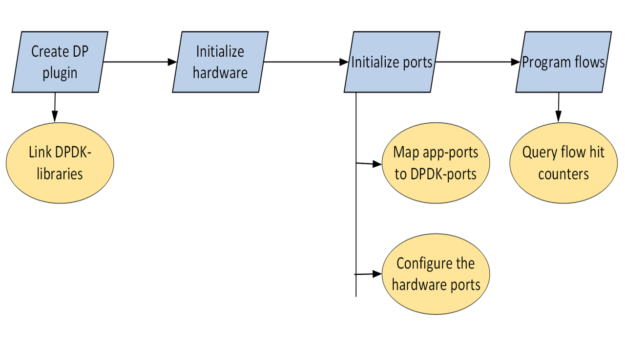
Development environment
As the target architecture is DPU-Arm, you can build directly on an Arm CPU, cross-compile on a X86 CPU, or build in the cloud. For this post, I coded and built directly on the DPU Arm CPU.
Run app as root user
FRR is typically run as a non-root user. FRR can download and upload the entire internet routing table; what could possibly go wrong with that? However, almost all the DPDK apps are run as root users and the DPDK libraries and drivers have come to expect that.
After much experimentation, I couldn’t make FRR work as a non-root user and re-compiled it with the root-user options. This is acceptable as I was running FRR in a secure space, the DPU-Arm CPU.
Adding a new plugin to Zebra
Zebra is a daemon in FRR that is responsible for consolidating the updates from routing protocol daemons and building the forwarding tables. Zebra also has an infrastructure for pushing those forwarding tables into dataplanes like the Linux kernel.
Link DPDK shared libraries to zebra
FRR has its own build system which limits direct import of external make files. Thanks to the simple elegance of pkg-config, linking the relevant libraries to Zebra was easy.
I located libdpdk.pc and added that to the PKG_CONFIG_PATH value:
root@dpu-arm:~# find /opt/mellanox/ -name libdpdk.pc
/opt/mellanox/dpdk/lib/aarch64-linux-gnu/pkgconfig/libdpdk.pc
root@dpu-arm:~# export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/opt/mellanox/dpdk/lib/aarch64-linux-gnu/pkgconfig
Pkg-config provides you with the following abstractions:
libs—Provides a list of DPDK shared libraries.cflags—Provides the location of the DPDK header files.
root@dpu-arm:~# pkg-config --libs libdpdk -L/opt/mellanox/dpdk/lib/aarch64-linux-gnu -Wl,--as-needed -lrte_node -lrte_graph -lrte_bpf -lrte_flow_classify -lrte_pipeline -lrte_table -lrte_port -lrte_fib -lrte_ipsec -lrte_vhost -lrte_stack -lrte_security -lrte_sched -lrte_reorder -lrte_rib -lrte_regexdev -lrte_rawdev -lrte_pdump -lrte_power -lrte_member -lrte_lpm -lrte_latencystats -lrte_kni -lrte_jobstats -lrte_gso -lrte_gro -lrte_eventdev -lrte_efd -lrte_distributor -lrte_cryptodev -lrte_compressdev -lrte_cfgfile -lrte_bitratestats -lrte_bbdev -lrte_acl -lrte_timer -lrte_metrics -lrte_cmdline -lrte_pci -lrte_ethdev -lrte_meter -lrte_ip_frag -lrte_net -lrte_mbuf -lrte_mempool -lrte_hash -lrte_rcu -lrte_ring -lrte_eal -lrte_telemetry -lrte_kvargs -lbsd root@dpu-arm:~# root@dpu-arm:~# pkg-config --cflags libdpdk -include rte_config.h -mcpu=cortex-a72 -I/opt/mellanox/dpdk/include/dpdk -I/opt/mellanox/dpdk/include/dpdk/../aarch64-linux-gnu/dpdk -I/opt/mellanox/dpdk/include/dpdk -I/usr/include/libnl3 root@dpu-arm:~#
I added the pkg check-and-define macro for DPDK in the FRR makefile (configure.ac).
if test "$enable_dp_dpdk" = "yes"; then
PKG_CHECK_MODULES([DPDK], [libdpdk], [
AC_DEFINE([HAVE_DPDK], [1], [Enable DPDK backend])
DPDK=true
], [
AC_MSG_ERROR([configuration specifies --enable-dp-dpdk but DPDK libs were not found])
])
fi
I included the DPDK libs and cflags abstractions into the zebra-dp-dpdk make macro (zebra/subdir.am).
zebra_zebra_dplane_dpdk_la_LIBADD = $(DPDK_LIBS)
zebra_zebra_dplane_dpdk_la_CFLAGS = $(DPDK_CFLAGS)
With that, I had all the necessary headers and libraries to build the plugin.
Initialize hardware
The first step was to initialize the hardware.
char*argv[] = {"/usr/lib/frr/zebra", "--"};
rc = rte_eal_init(sizeof(argv) / sizeof(argv[0]), argv);
This probes the PCIe devices and populates the DPDK rte_eth_dev database.
Initialize ports
Next, I set up the hardware ports.
Set up port mapping for the app
FRR has its own interface (port) table based on the Linux netdevs table, which is populated using NetLink updates and keyed in using ifIndex. PBR rules are anchored to an interface in this table. To program PBR dataplane entries, you need a mapping table between the Linux ifIndex and DPDK port-id values. The netdev information is already available in the DPDK driver and can be queried through rte_eth_dev_info_get.
struct rte_eth_dev_info *dev_info
RTE_ETH_FOREACH_DEV(port_id) {
/* dev_info->if_index is used for setting up the dpdk port_id<=>if_index mapping table
* in zebra */
rte_eth_dev_info_get(port_id, dev_info);
}
Configure hardware ports
In addition, all the ports need to be placed in flow isolation mode and started.
rte_flow_isolate(port_id, 1, &error);
Flow isolation sends flow-miss packets to the kernel networking stack, allowing it to handle things like ARP requests.
rte_eth_dev_start(port_id);
Program PBR rules using rte_flow APIs
PBR rules now need to be programmed as rte_flow lists. Here is a sample rule:
In-port=pf0vf0, match [SIP=172.20.0.8, DIP=172.30.0.8, IP-proto=UDP, UDP-dport=53], actions [set-src-mac=p0-mac, set-dst-mac=leaf2-MAC, dec-ttl, out-port=p0]
These parameters are populated through the rte_flow_attributes, rte_flow_item (match) and rte_flow_action data structures.
Flow attributes
This data structure is used to indicate that the PBR flow is for packet redirection, or transfer flow.
static struct rte_flow_attr attrs = {.ingress = 1, .transfer = 1};
Flow match items
DPDK uses a {key, mask} matching structure for each layer in the packet header: Ethernet, IP, UDP, and so on.
struct rte_flow_item_eth eth, eth_mask;
struct rte_flow_item_ipv4 ip, ip_mask;
struct rte_flow_item_udp udp, udp_mask;
Filling these data structures requires a fair amount of mostly repetitive code.
Flow actions
DPDK uses a separate data structure for each action and then allows you to provide all the actions as a variable length array at the time of flow creation. The relevant actions are as follows:
struct rte_flow_action_set_mac conf_smac, conf_dmac;
struct rte_flow_action_port_id conf_port;
struct rte_flow_action_count conf_count;
Filling these data structures is again just mechanical.
Flow validation and creation
Optionally, you can validate the rte_flow_attr, rte_flow_item, and rte_flow_action lists.
rc = rte_flow_validate(port_id, &attrs, items, actions, &error);
Flow validation is typically used to check if the underlying DPDK driver can support the specific flow configuration. Flow validation is an optional step and in the final code, you can jump directly to flow creation.
flow_ptr = rte_flow_create(port_id, &attrs, items, actions, &error);
Rte_flow commands are anchored to the incoming port. It is possible to create groups of flow entries and chain them. Even if a flow entry is not the first in the chain, not in group-0, it must still be anchored to the incoming port. That group-0 has performance limitations.
Flow insertion rate is limited in group-0. To bypass that limitation, you can install a default flow in group-0 to “jump to group-1” and then program the app’s steering flows in group-1.
Flow deletion
The flow creation API returns a flow pointer that must be cached for subsequent flow deletion.
rc = rte_flow_destroy(port_id, flow_ptr, &error);
The FRR-PBR daemon manages the state machine for resolving and adding or deleting PBR flows. So, I didn’t have to age them out using DPDK-native functions.
Flow statistics
At the time of flow creation, I attached a count-action to the flow. That can be used for querying the flow statistics and hits.
struct rte_flow_query_count query;
rte_flow_query(port_id, flow_ptr, actions, &query, &error);
I plugged that stat display into FRR’s vtysh CLI for easy testing and verification.
Testing the app
I fired up FRR as a root user with the newly added DPDK plugin enabled through the /etc/frr/daemons file:
zebra_options= " -M dplane_dpdk -A 127.0.0.1"
The FRR interface to DPDK-port mapping table is populated:
root@dpu-arm:~# systemctl restart frr
root@dpu-arm:~# vtysh -c "show dplane dpdk port"
Port Device IfName IfIndex sw,domain,port
0 0000:03:00.0 p0 4 0000:03:00.0,0,65535
1 0000:03:00.0 pf0hpf 6 0000:03:00.0,0,4095
2 0000:03:00.0 pf0vf0 15 0000:03:00.0,0,4096
3 0000:03:00.0 pf0vf1 16 0000:03:00.0,0,4097
4 0000:03:00.1 p1 5 0000:03:00.1,1,65535
5 0000:03:00.1 pf1hpf 7 0000:03:00.1,1,20479
root@dpu-arm:~#
Next, I configured the PBR rule to match DNS traffic from VM1 and redirect it to leaf2, using frr.conf.
!
interface pf0vf0
pbr-policy test
!
pbr-map test seq 1
match src-ip 172.20.0.8/32
match dst-ip 172.30.0.8/32
match dst-port 53
match ip-protocol udp
set nexthop 192.168.20.250
!
I sent DNS queries from VM1 to the anycast DNS server.
root@dpu-arm:~# vtysh -c "show dplane dpdk pbr flows"
Rules if pf0vf0
Seq 1 pri 300
SRC IP Match 172.20.0.8/32
DST IP Match 172.30.0.8/32
DST Port Match 53
Tableid: 10000
Action: nh: 192.168.20.250 intf: p0
Action: mac: 00:00:5e:00:01:fa
DPDK: installed 0x40
DPDK stats: packets 14 bytes 1708
root@dpu-arm:~#
Flow is matched and traffic is forwarded to the destination, leaf2/server2, with the modified packet headers. This can be verified with the counters attached to the flow and through the hardware dumps using mlx_steering_dump.
root@dpu-arm:~# ./mlx_steering_dump/mlx_steering_dump_parser.py -p `pidof zebra` -f /tmp/dpdkDump
domain 0x32744e02, table 0xaaab07849cf0, matcher 0xffff20011010, rule 0xffff20012420
match: outer_l3_type: 0x1, outer_ip_dst_addr: 172.30.0.8, outer_l4_type: 0x2, metadata_reg_c_0: 0x00030000, outer_l4_dport: 0x0035, outer_ip_src_addr: 172.20.0.8
action: MODIFY_HDR(hdr(dec_ip4_ttl,smac=04:3f:72:bf:ae:38,dmac=00:00:5e:00:01:fa)), rewrite index 0x0 & VPORT, num 0xffff & CTR(hits(33), bytes(4026)), index 0x806200
FRR now has a fully functioning DPDK dataplane plugin offloading PBR rules on the DPU hardware.
Summary
This post reviewed the creation of a FRR dataplane plugin to hardware accelerate PBR rules on BlueField using the DPDK rte_flow library. In the next post, I walk you through the creation of the FRR DOCA dataplane plugin and show you how to offload PBR rules using the new DOCA flow library. For more information, see Developing Applications with NVIDIA BlueField DPU and NVIDIA DOCA Libraries.
