
Enterprises are sitting on a goldmine of data waiting to be used to improve efficiency, save money, and ultimately enable higher productivity. With generative AI, developers can build and deploy an agentic flow or a retrieval-augmented generation (RAG) chatbot, while ensuring the insights provided are based on the most accurate and up-to-date information.
Building these solutions requires not only high accuracy from models in a retrieval pipeline, but also requires the necessary infrastructure to cost-effectively and reliably deploy these models. The NVIDIA NeMo Retriever collection of NIM inference microservices enables these solutions for text embedding and reranking. NeMo Retriever is part of the NeMo platform, used for developing custom generative AI—including large language models (LLMs), multimodal, vision, and speech AI —anywhere. Today, NVIDIA announced the availability of four new community-based NeMo Retriever NIMs.
- Three NeMo Retriever Embedding NIMs:
- NV-EmbedQA-E5-v5: an embedding model optimized for text question-answering retrieval.
- NV-EmbedQA-Mistral7B-v2: a multilingual model fine-tuned for text embedding and accurate question answering.
- Snowflake-Arctic-Embed-L: an optimized model for text embedding.
- One NeMo Retriever Reranking NIM:
- NV-RerankQA-Mistral4B-v3: a model fine-tuned for text reranking and accurate question answering.
Understanding how an information retrieval pipeline works
Before diving into the models, let’s understand the function of embedding and reranking models in a retrieval pipeline (Figure 1).

Embedding Models
While ingesting documents, embedding models are used to generate vector representations of text that encode its semantic meaning. These vectors are then stored in a vector database. When a user asks a question, this question is encoded into a vector using the same embedding model. This vector is then used to match against the vectors stored in the vector database to retrieve the most relevant information using a heuristic metric like “Approximate Nearest Neighbor” search.
Reranking Models
Reranking models take in text chunks from the documents and the question, create a combined representation of both, and then score the relevance of the two texts.
An embedding model, along with a heuristic metric and a reranking model are all fundamentally doing the same thing: scoring how similar two pieces of information are. Given this overlap, one might reasonably ask why use them both. Or, which is the better model to use?
The answer to these questions lies in the underlying trade-offs being made. Embedding models are considerably faster and cheaper than a reranking model, but a reranking model is significantly more accurate.
To make the best of both models, the lighter and cheaper embedding models are used to identify a small pool of relevant chunks to a user’s question, say 100. Then a heavier but more accurate reranking model is used to identify the most relevant chunks. If multiple retrieval pipelines are being used to extract the top five most relevant information from each source (think data coming from the web, local pdf files, structured databases, and so on), the reranking model is used to narrow down the best pieces of information from that given pool.
NeMo Retriever NIMs: a complete retrieval solution
For building enterprise-grade model inference pipelines, there are two primary considerations—cost and stability. Let’s touch on how NeMo Retriever NIMs address them.
Cost
Cost is impacted by time-to-market and the cost of running the models.
Time-to-market: NIMs are designed to be easy-to-use and scalable model inference solutions, enabling enterprise application developers to focus on working on their application logic rather than having to spend cycles on building and scaling out the infrastructure. NIMs are containerized solutions, which come with industry-standard APIs and Helm charts to scale.
Maximizing utilization: NIMs use the full suite of NVIDIA AI Enterprise software to accelerate model inference, maximizing the value enterprises can derive from their models and in turn reducing the cost of deploying the pipelines at scale.
Stability
NIMs are part of the NVIDIA AI Enterprise license, which offers API stability, security patches, quality assurance, and support for a smooth transition from prototype to production for enterprises that run their businesses on AI.
Selecting NIMs for your retrieval pipeline
While designing a retrieval pipeline, there are four factors to balance: accuracy, latency, throughput for data ingestion, and throughput in production. A suite of NIMs enables developers to balance the above considerations to build the pipeline most suited to their workload. The following are three general recommendations:
Maximize throughput and minimize latency
The recommended path for maximizing throughput is to use the NV-EmbedQA-E5-v5 NIM, which enables inference for an optimized and fine-tuned lightweight embedding model.
Optimize for low-volume, low-velocity databases
Low-volume and low-velocity databases tend to include critical documents that are referred to often and by a wide number of users. In these cases, it is recommended to use the NV-EmbedQA-Mistral7B-v2 NIM for both ingestion and production cases to maximize throughput and accuracy while retaining low latency.
Optimize for high-volume and high-velocity data
High-volume and high-velocity data requires considerations for minimizing ingestion costs while maximizing accuracy. This can be achieved by using a lightweight embedding model to index data and then use a reranker to boost retrieval accuracy. It is recommended to use the NV-EmbedQA-E5-v5 NIM to ingest the documents paired with NV-RerankQA-Mistral-4B-v3 for reranking.
Figure 3 and Figure 4 contain further information about throughput and accuracy of the NeMo Retriever NIMs. While the accuracy numbers below showcase a few of the academic benchmarks which are good representations of the general enterprise retrieval use case, it is recommended to evaluate all the NIMs as every dataset has its own unique nuances.
Refer to this article to learn more about the best practices for evaluating retrieval pipelines.
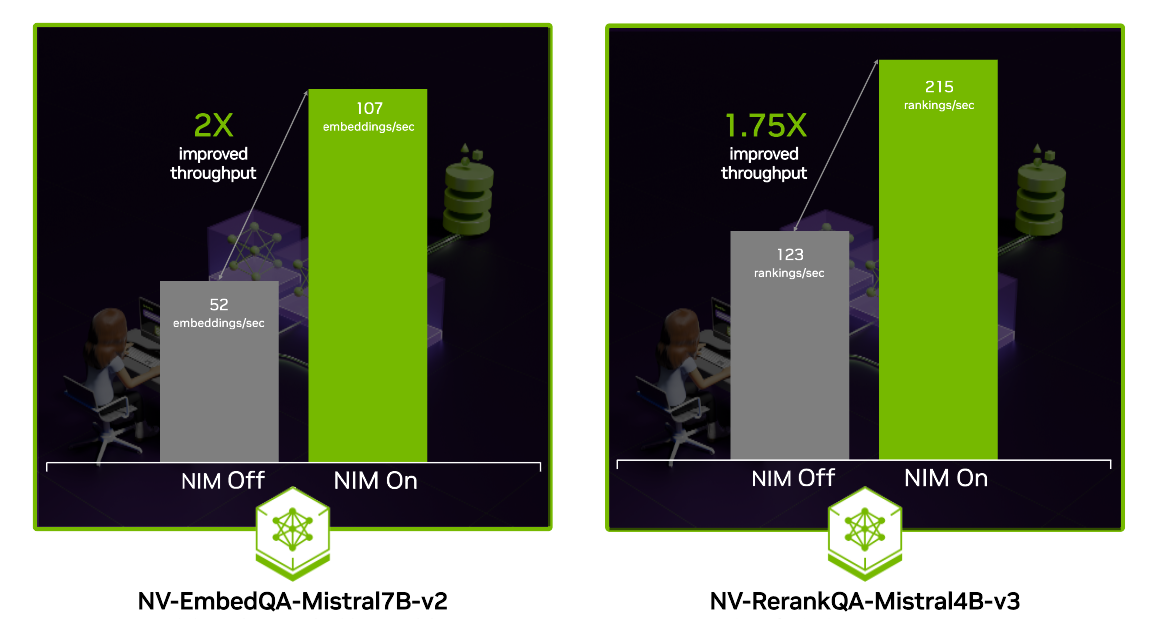
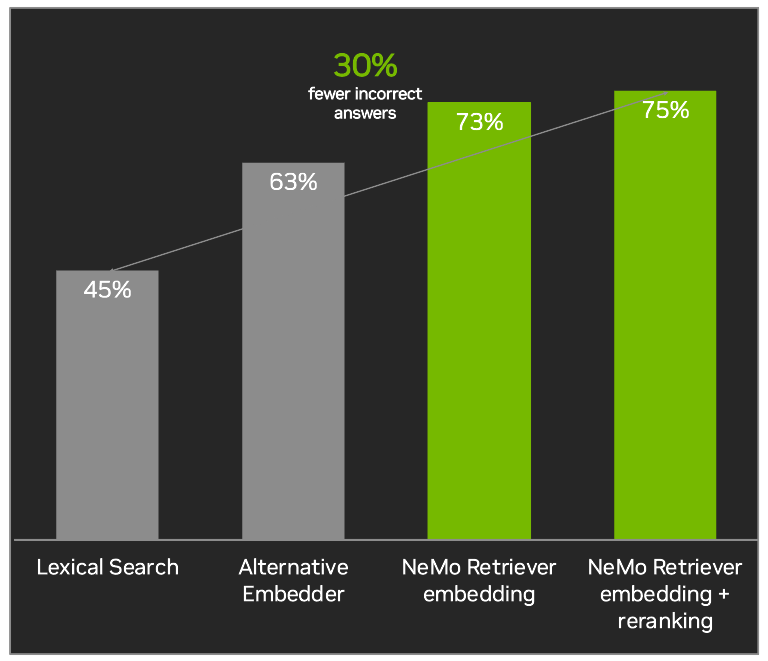
Figure 4. Performance of NeMo Retriever NIM pipeline shows improved accuracy on popular benchmark datasets like NQ, HotpotQA, FiQA and TechQA (Recall @5)
Get started
Experience the NVIDIA NeMo Retriever NIMs today in the API catalog in our hosted environment. Explore NVIDIA generative AI examples, illustrating how to integrate NVIDIA NIMs to write sample applications. Apply for a lab to try the AI Chatbot with RAG workflow in NVIDIA LaunchPad. Customize and download the NIMs to deploy anywhere your data resides.
