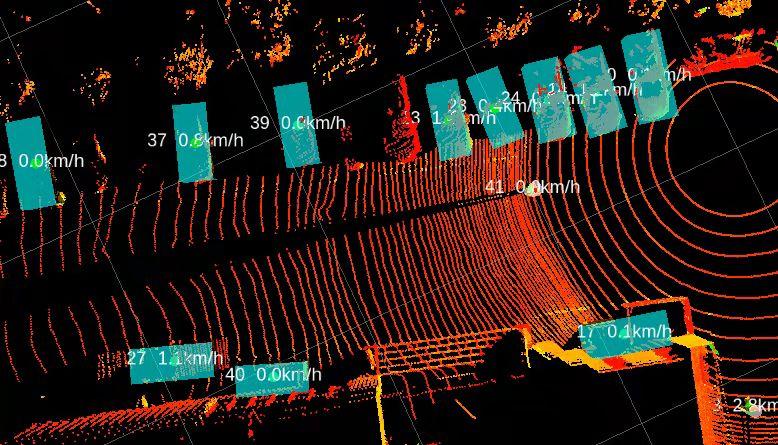
A point cloud is a data set of points in a coordinate system. Points contain a wealth of information, including three-dimensional coordinates X, Y, Z; color; classification value; intensity value; and time. Point clouds mostly come from lidars that are commonly used in various NVIDIA Jetson use cases, such as autonomous machines, perception modules, and 3D modeling.
One of the key applications is to leverage long-range and high-precision data sets to achieve 3D object detection for perception, mapping, and localization algorithms.
PointPillars is one the most common models used for point cloud inference. This post discusses an NVIDIA CUDA-accelerated PointPillars model for Jetson developers. Download the CUDA-PointPillars model today.
What is CUDA-Pointpillars
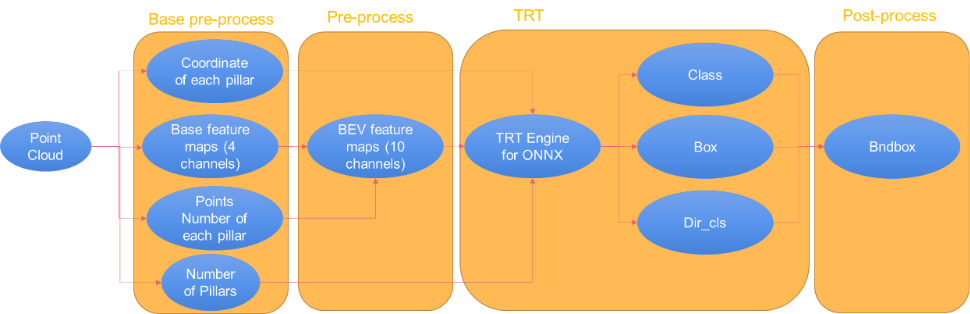
In this post, we introduce CUDA-Pointpillars, which can detect objects in point clouds. The process is as follows:
- Base preprocessing: Generates pillars.
- Preprocessing: Generates BEV feature maps (10 channels).
- ONNX model for TensorRT: An ONNX mode that can be implemented by TensorRT.
- Post-processing: Generates bounding boxes by parsing the output of the TensorRT engine.
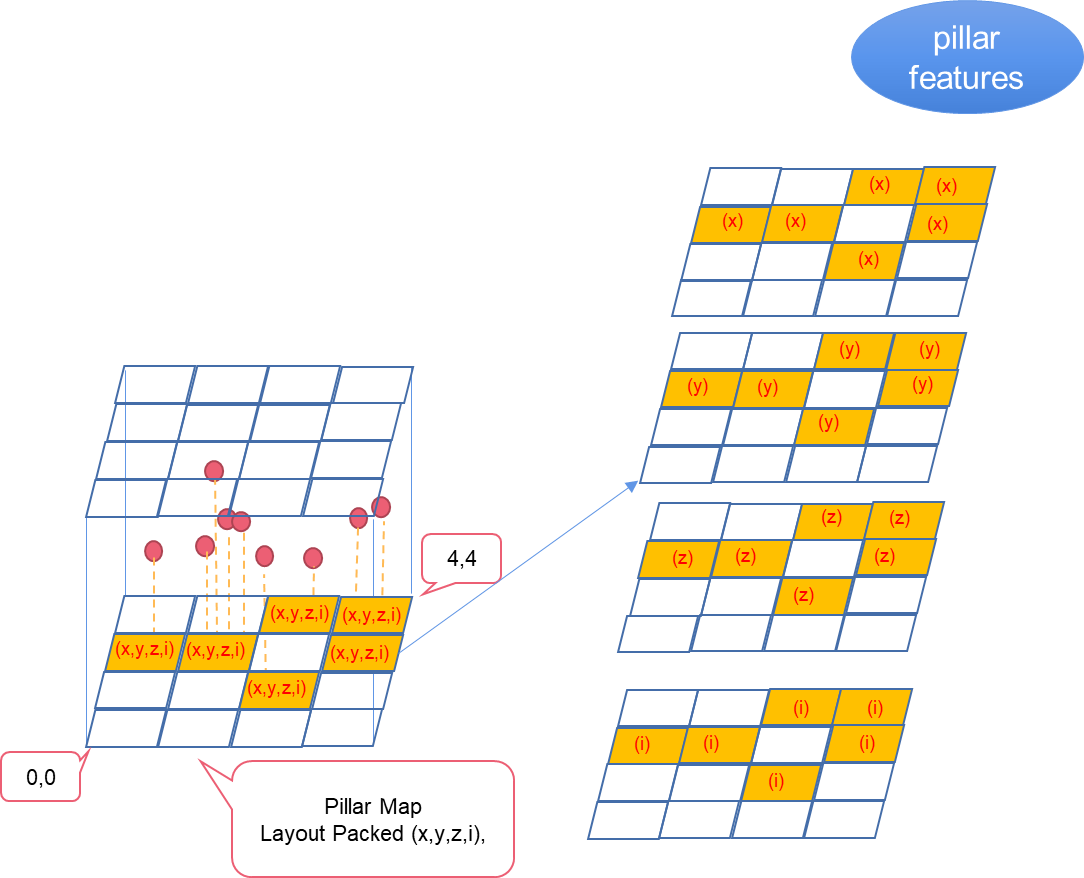
Base preprocessing
The base preprocessing step converts point clouds into base feature maps. It provides the following components:
- Base feature maps
- Pillar coordinates: Coordinates of each pillar.
- Parameters: Number of pillars.
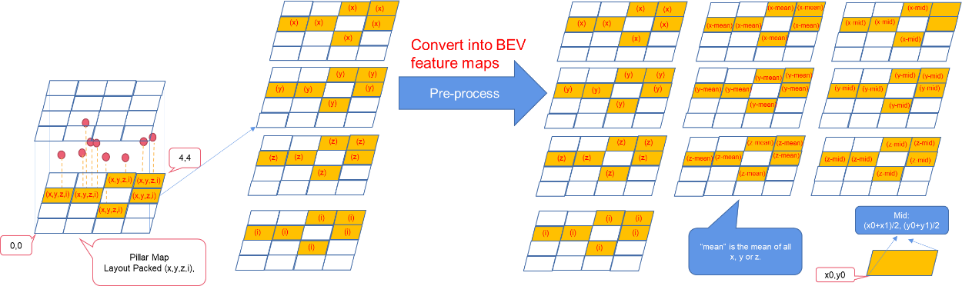
Preprocessing
The preprocessing step converts the basic feature maps (four channels) into BEV feature maps (10 channels).
ONNX model for TensorRT
The native point pillars from OpenPCDet were modified for the following reasons:
- Too many small operations, with low memory bandwidth.
- Some operations, like NonZero, are not supported by TensorRT.
- Some operations, like ScatterND, have low performance.
- They use “dict” as input and output, which cannot export ONNX files.
To export ONNX from native OpenPCDet, we modified the model (Figure 4).
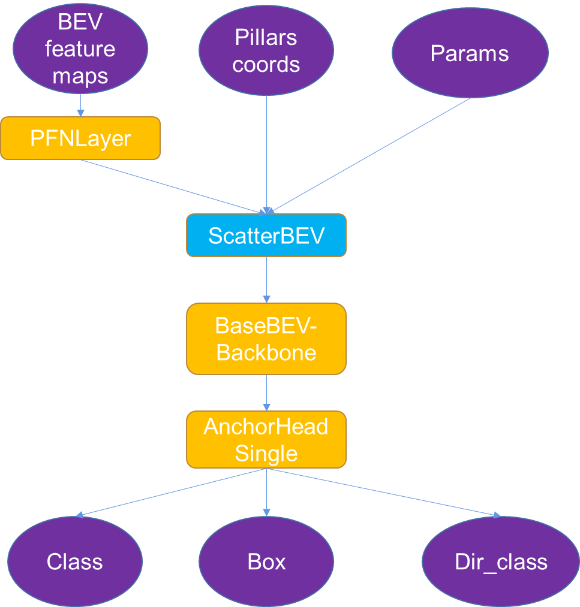
You can divide the whole ONNX file into the following parts:
- Inputs: BEV feature maps, pillar coordinates, parameters. These are all generated in preprocessing.
- Outputs: Class, Box, Dir_class. These are parsed by post-processing to generate a bounding box.
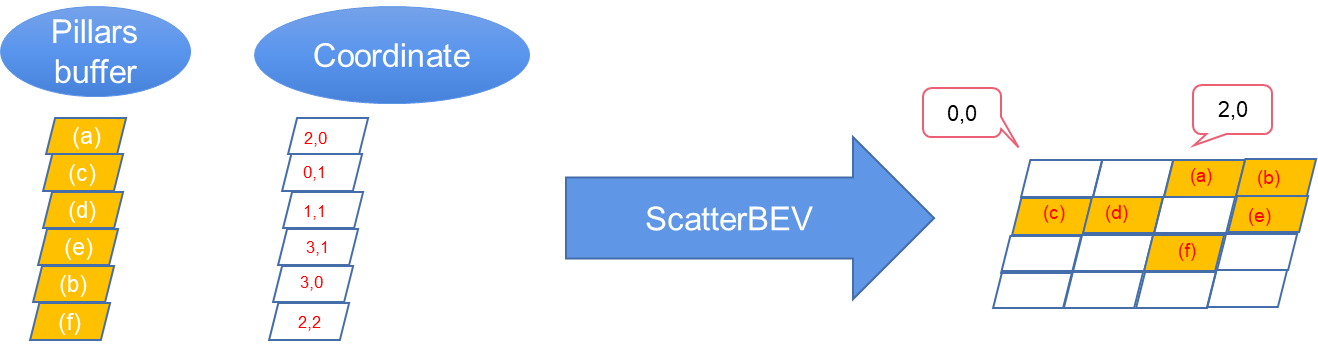
- ScatterBEV: Converts point pillars (1D) into a 2D image, which can work as a plug-in for TensorRT.
- Others: Supported by TensorRT. [OTHER WHAT?]
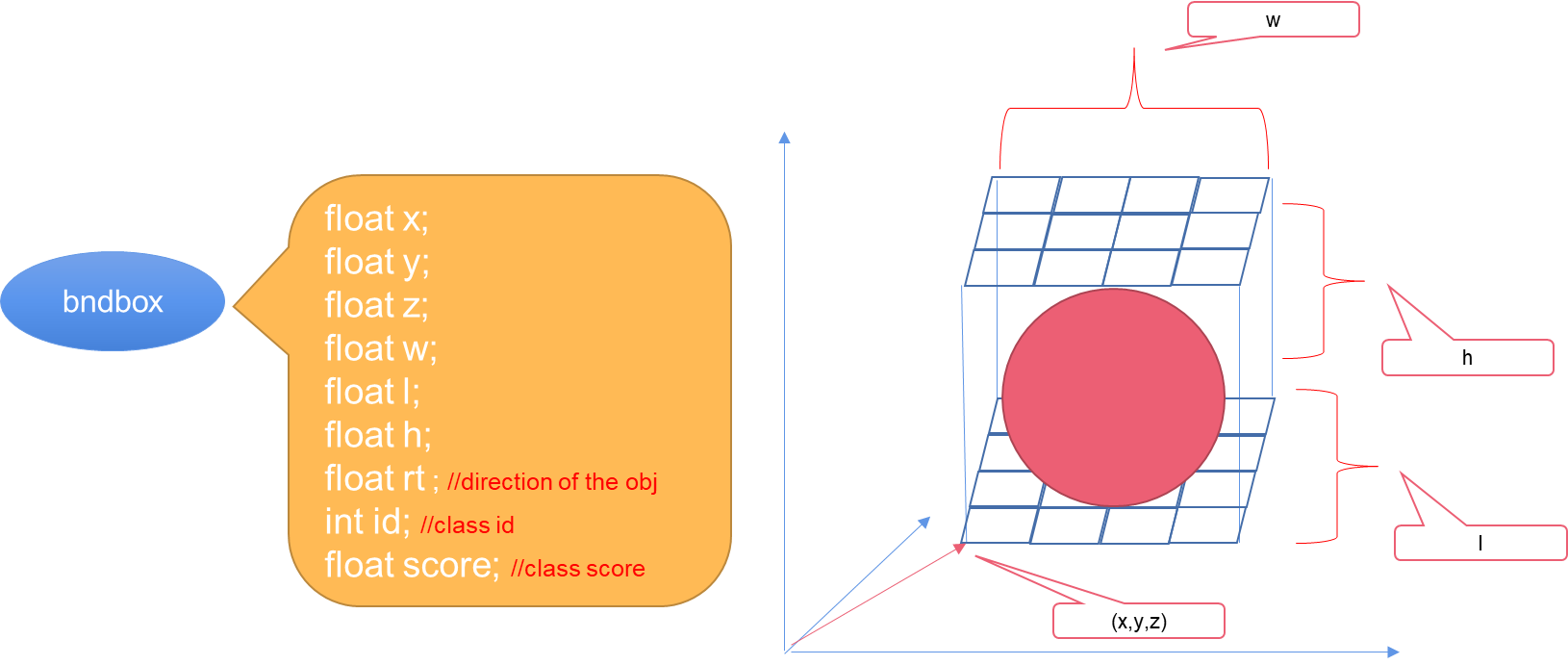
Post-processing
The post-processing parses the output of the TensorRT engine (class, box, and dir_class) and output-bounding boxes. Figure 6 shows example parameters.
Using CUDA-PointPillars
To use CUDA-PointPillars, provide the ONNX mode file and data buffer for the point clouds:
std::vector<Bndbox> nms_pred;
PointPillar pointpillar(ONNXModel_File, cuda_stream);
pointpillar.doinfer(points_data, points_count, nms_pred);
Converting a native model trained by OpenPCDet into an ONNX file for CUDA-Pointpillars
In our project, we provide a Python script that can convert a native model trained by OpenPCDet into am ONNX file for CUDA-Pointpillars. Find the exporter.py script in the /tool directory of CUDA-Pointpillars.
To get a pointpillar.onnx file in the current directory, run the following command:
$ python exporter.py --ckpt ./*.pth
Performance
The table shows the test environment and performance. Before the test, boost CPU and GPU.
| Jetson | Xavier NVIDIA AGX 8GB |
| Release | NVIDIA JetPack 4.5 |
| CUDA | 10.2 |
| TensorRT | 7.1.3 |
| Infer Time | 33 ms |
Get started with CUDA-PointPillars
In this post, we showed you what CUDA-PointPillars is and how to use it to detect objects in point clouds.
Because native OpenPCDet cannot export ONNX and has too many small operations with low performance for TensorRT, we developed CUDA-PointPillars. This application can export native models trained by OpenPCDet to a special ONNX model and inference the ONNX model by TensorRT.
