
The pre-trained models on the NVIDIA NGC catalog offer state of the art accuracy for a wide variety of use-cases including natural language understanding, computer vision, and recommender systems. NGC models now include the important credentials that help data scientists and developers quickly identify the right model to deploy for their AI software development.
These credentials provide a report card of the models showing the training configurations, performance metrics and key parameters for the model. The metrics show important hyperparameters like model accuracy, epoch, batch size, precision, training dataset, throughput and other important dimensions that help users identify the usability of the models and gives them the confidence to deploy them.
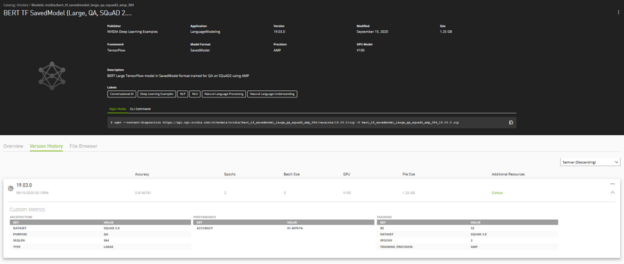
The version number corresponds to the version of the framework container used to build the model; the GPU configuration and various training attributes along with the GitHub link to the detailed recipe on building the models gives users the option to replicate and customize the models to better fit their use cases.
NGC private registry users have access to the model credentials features, enabling developers to quickly identify the right models and deploy them faster in production. The scorecard metrics are customizable so that appropriate attributes can be used to better describe the models. For example, a compute vision model would better describe the inference performance with the images-per-second metric while sentences-per-second is suitable for NLP models.
Deploying the NGC models has also been simplified. Now you can browse, identify, and pull the right model from the same page with wget and NGC CLI commands. Simply copy the commands in your terminal or Jupyter notebooks to pull and run the models.
Pull NVIDIA AI software and pre-trained models from the NGC catalog to build your solutions.
Follow along in this blog to get started with pre-trained conversation AI models.
