
To enable deep learning, Yahoo added GPU nodes into their Hadoop clusters with each node having 4 Nvidia Tesla K80 cards, each card with two GK210 GPUs. These nodes have 10x processing power than the traditional commodity CPU nodes they generally use in their Hadoop clusters.
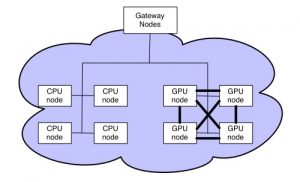
Yahoo has progressively invested in building and scaling Apache Hadoop clusters with a current footprint of more than 40,000 servers and 600 petabytes of storage spread across 19 clusters.
Hadoop clusters are the preferred platform for large-scale machine learning at Yahoo. Deep learning is used in many of Yahoo’s products, such as Flickr’s Magic View feature which automatically tags all user photos, enabling Flickr end users to organize and find photos easily. Read “Picture This: NVIDIA GPUs Sort Through Tens of Millions of Flickr Photos” for more information on the feature.
To enable deep learning on these enhanced clusters, the Yahoo Big Data and Machine Learning team developed a comprehensive distributed solution based upon open source software libraries, Apache Spark and Caffe. Caffe-on-Spark enables multiple GPUs, and multiple machines to be used for deep learning.
AI-Generated Summary
- Yahoo enhanced their Hadoop clusters by adding GPU nodes, each equipped with 4 NVIDIA Tesla K80 cards, significantly boosting processing power for deep learning tasks.
- The company's Hadoop clusters, comprising over 40,000 servers and 600 petabytes of storage, serve as the primary platform for large-scale machine learning.
- Yahoo's Big Data and Machine Learning team developed Caffe-on-Spark, a distributed solution that leverages Apache Spark and Caffe to facilitate deep learning across multiple GPUs and machines.
AI-generated content may summarize information incompletely. Verify important information. Learn more
About the Authors
0 responses to “Caffe on Spark for Deep Learning from Yahoo”
Leave a Reply
You must be logged in to post a comment.








Their example talks about training neural networks, is there any information on if this same technique can be applied for detection on a distributed platform like AWS to do a detection using a trained caffemodel file?