
General-purpose large language models (LLMs) have proven their usefulness across various fields, offering substantial benefits in applications ranging from text generation to complex problem-solving. However, there are circumstances where developing a bespoke language model becomes not just beneficial but essential. This necessity arises particularly in specialized domains characterized by distinctive vocabulary and content that diverges from typical linguistic structures.
Cybersecurity is one such domain where general LLM limitations become evident, especially when dealing with raw logs. The nature of natural language is vastly different from the structured format of machine-generated logs. Applying traditional LLMs directly to such data is impractical. These models struggle with the characteristics of machine logs that significantly differ from the constructs of natural language:
- Complex JSON formats that feature nested dictionaries
- Novel syntax
- Use of key-value pairs
- The spatial relationship between data elements
LLMs pretrained on corpora of natural language text, associated code, and machine logs lack the specificity required to effectively parse, understand, and build up cybersecurity data in real-world settings, leading to significant limitations to applications for cybersecurity challenges.
It’s necessary to use cyber language models trained with raw cyber logs to generate logs that are specific to an enterprise setting. Relying on traditional models to generate synthetic logs can introduce several disadvantages. These models may not capture the unique patterns and anomalies specific to a real operational environment, leading to synthetic logs that lack the intricacies and irregularities of genuine data.
Traditional models might also oversimplify the complex interactions within network logs, resulting in outputs that are not robust enough for effective training or testing of cybersecurity systems. This can reduce the effectiveness of simulations and other analyses intended to prepare for actual cybersecurity threats.
Improving the precision and effectiveness of cybersecurity measures against complex threats
Our research is centered on investigating whether these cybersecurity challenges can be effectively addressed by employing language models that have been pretrained specifically on raw cybersecurity logs. Through this approach, we aim to ensure the practicality and effectiveness of using specialized foundation models over general-purpose language models in cybersecurity.
One significant benefit to this approach is the reduction of false positives, which create unnecessary alerts also obscure genuine threats. This problem is worsened when anomaly detection models are trained on incomplete datasets that don’tt account for benign or expected events.
The application of generative AI can compensate for the shortage of realistic cybersecurity data, improving the precision of anomaly detection systems. This can happen through the creation of synthetic data or the use of cybersecurity-specific foundation models trained on raw logs.
These customized models offer robust support for defense hardening efforts. They enable the simulation of cyber-attacks and facilitate the exploration of various what-if scenarios. This capability is crucial for verifying the effectiveness of existing alerts and defensive measures against rare or unforeseen threats.
By continuously updating the training data to reflect emerging threats and evolving data patterns, these models can significantly contribute to strengthening cybersecurity defenses.
Another critical application of cybersecurity-specific foundation models is in red teaming. By learning from raw logs of past security incidents, these models can generate a wider variety of attack logs, including those tagged with MITRE identifiers. This ability to simulate multi-stage attack scenarios is invaluable for preparing and fortifying cybersecurity measures against complex and sophisticated threats.
Figure 1 shows an example workflow for using cyber language models to improve defenses.
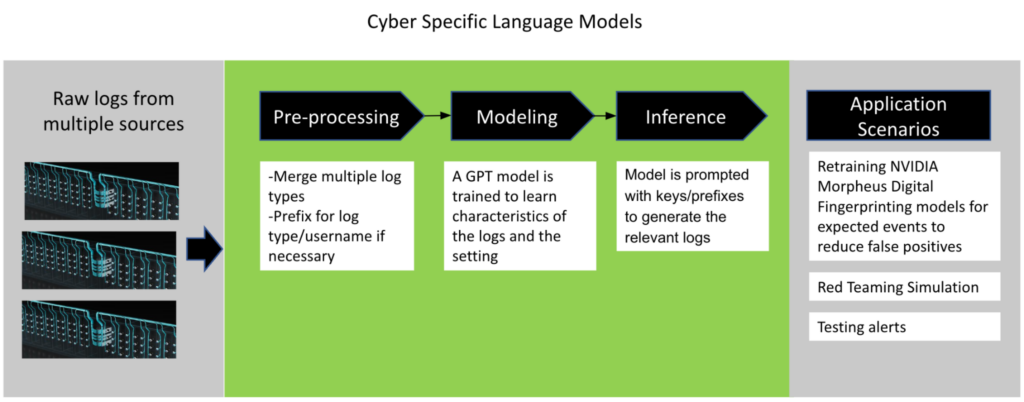
General-purpose LLMs vs. cyber-based LLMs
To verify if generic LLMs can understand and generate cyber logs, we established a baseline using hosted LLMs.
Our attempts with LLMs to generate raw cybersecurity logs have been challenging. Despite providing these models with specific examples, they struggled to expand upon log types. This challenge is increased by the variability seen within the same log types across different settings, which may not share the same columns or formats.
Such variability highlights the limitations of natural language-trained LLMs, emphasizing their inadequacy in meeting the complex demands of cybersecurity log generation. The comparison in Table 1 aims to show the distinct advantages of our specialized language model over conventional instruction-tuned models, particularly in its adept handling of the diverse and specific requirements of cybersecurity log types.
| Whether logs are specified in the prompts | Prompts | General purpose LLMs | NVIDIA Cyber Language Model |
| Generic | Zero-shot Attack example log generation | Limited | Yes |
| Generic | One-shot Attack example log generation | N/A | N/A |
| Generic | Few-shot Attack example log generation | N/A | N/A |
| Generic | Zero-shot Attack stream of logs generation | Limited | Yes |
| Generic | One-shot Attack stream of logs generation | No | N/A |
| Generic | Few-shot Attack stream of logs generation | No | N/A |
| Specific log type | Attack log generation by completion | No | Yes |
| Specific log type | One-shot attack logs generation | No | N/A |
| Specific log type | Few-shot attack logs generation | No | N/A |
Here’s our example prompt for the general-purpose LLMs to raw log generation:
Generate sample AWS CloudTrail logs that show signs of an attacker enumerating and discovering resources in a target AWS environment, as described in MITRE ATT&CK technique T1580 Cloud Infrastructure Discovery.
Experiments to explore the capabilities of cyber-specific LLMs
In our experiments, we explored using GPT language models to generate synthetic cyber logs for multiple purposes, including
- User-specific log generation
- Scenario simulation
- Suspicious event generation
- Anomaly detection
Our methodology was to export the raw logs from the database in jsonlines format and use that file to train a GPT from scratch.
Experiment A: Cyber log stream generation with GPT models
Unlike multi-billion-parameter LLMs trained with trillions of tokens, we observed that a GPT2 size or smaller models trained with fewer than 10M tokens from raw cybersecurity data can generate useful logs.
We began by training small GPT models from scratch on raw Microsoft Azure and Confluence logs in JSON format. By prompting the models with the start of each log type, they generated realistic synthetic logs. We then merged the two log types using the timestamp column and trained a new GPT on the combined data, enabling it to generate both Azure– and Confluence-style logs.
Next, we investigated generating user-specific logs by adding the username as a prefix to each log entry during training. The resulting model could generate logs for a specific user when prompted with their username. Some challenges encountered were malformed JSON in ~10% of outputs and log entries of high-activity users dominating and bleeding into the synthetic logs of other users. Using a character-level tokenizer helped produce more consistently well-formatted outputs.
To simulate logs for novel scenarios, like a user traveling to a new location, we trained a GPT model with username and location (country) prefixes. Prompting the model with a username and new location produced logs with the right user but the wrong location over 50% of the time.
To solve this, we trained separate GPTs, one for location metadata fields like city, state, latitude, and longitude with a country-level prefix, and another GPT for the rest of the fields. Querying the location-only model generates realistic combinations of location fields to insert into the user-specific logs. This is an approach we call Dual-GPT. Incorporating such simulated logs into the training of anomaly detection systems could help reduce false positive rates on unusual but benign events.
A deterministic way of dealing with such false positives for anticipated events would be disabling or ignoring alerts with certain fields. However, breaches can happen at any time and in any location, and disabling such alerts with specific fields would result in certain breaches not being detected. This applies to all the fields, not just location-related fields.
Reducing false positives is one strong motivation to use cyber language models. For example, NVIDIA Morpheus has a pipeline called digital fingerprinting, which detects anomalies in human or machine behavior, with multiple models for each user or user group. These models get retrained to avoid becoming stale. Such synthetic logs for anticipated events can easily be incorporated into the next training cycle, which would reduce the false positives.
Finally, we conducted some limited experiments using log prediction from GPT models trained on merged log streams as an anomaly detection approach. Most anomaly detection models monitor a single log type, although activities in different logs can be correlated and may together constitute an attack. This is where our approach could be crucial, as it can generate and predict the next logs across multiple log types.
We prompted the models with the last few log entries in a sequence and asked them to predict the next logs that should follow. By measuring the deviation of the actual incoming logs from the model’s predictions, we aimed to detect anomalies or unexpected events in the log stream that could signal an attack.
While the results of these initial experiments were inconclusive, we suggest that further refinement and testing are needed.
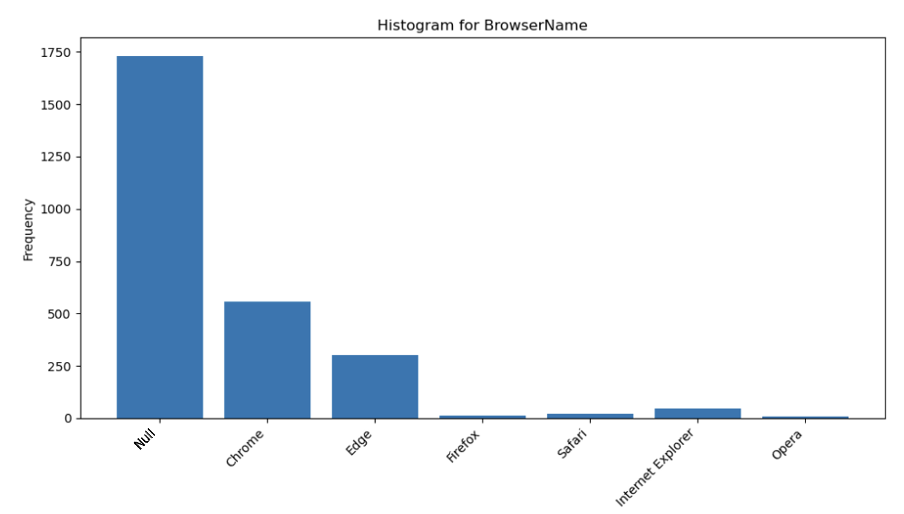
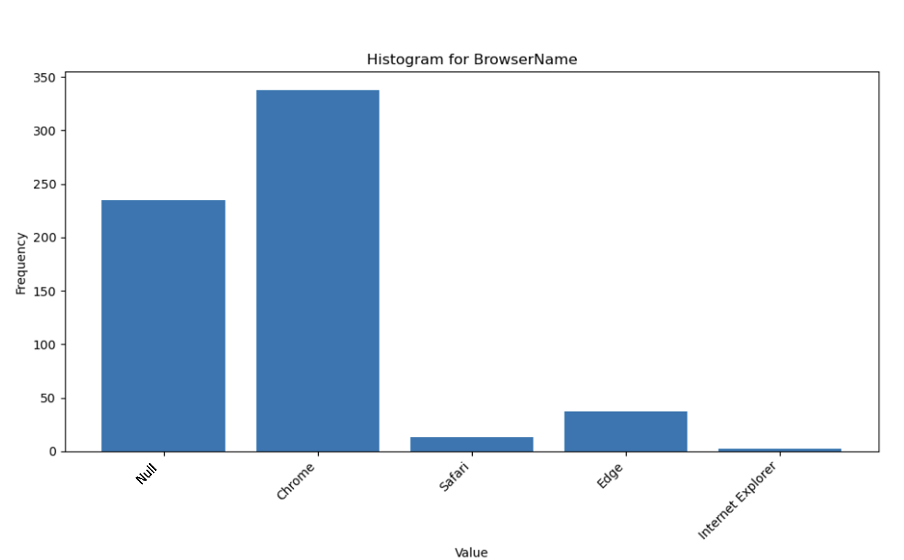
Figures 2 and 3 show that there are limitations in the distribution of unique categorical values. Sometimes rare values are omitted, and NULL values are not adequately represented in the synthetic logs. Increasing the model size or adjusting the generation temperature may help address this issue.
Cyber-specific GPT models show promise for enhancing cyber defense through synthetic log generation for simulation, testing, and anomaly detection, but challenges remain in preserving precise statistical profiles and generating fully realistic log event sequences. Further research will refine the techniques and quantify the benefits.
Here’s what we learned:
- It is possible to generate realistic logs using cyber language models and it’s possible to extend to generating multiple log types with a single model and novel scenario simulation.
- Fields with personally identifiable information (PII) can be hashed during training, yet the generation of corresponding logs remains effective.
- The dual-GPT approach enables the simulation of travel to any country or other specific fields, and this method can be extended to simulate different log types for various scenarios. Generated locations are based on company data, ensuring they are realistic. Dual-GPT approach is only needed to address the data gap for anticipated events.
- The character tokenizer is faster to train and slower in inference. In our experiments, character tokenizer worked well for the size of our data and models. Larger experiments may require subword tokenizers.
Experiment B: Simulating extensive red team activities with synthetic log generation
As the first experiment with security teams, we aimed to verify the feasibility of generating suspicious events to test the alerts with a more varied set of logs.
Deterministic alerts play a crucial role in identifying unusual events within system logs. To test the robustness of these alerts, we collaborated with security teams to generate synthetic logs using Cyber GPT models. By training a GPT model from scratch with historical logs that had previously triggered alerts, we aimed to produce new synthetic logs.
- 90% of these generated logs successfully triggered the same alerts, affirming their realism.
- 10% were deemed non-suspicious.
This experiment underscored the potential of synthetic log generation in enhancing the accuracy and reliability of security systems.
Taking a step further, we explored the generation of logs that simulate red team activities. Unlike traditional methods where LLMs are used to write code for red teaming, our approach uses these models to produce logs mimicking the traces of cyberattacks. This enables security teams to refine their detection and response strategies using logs that closely resemble those from real-world attacks.
Building on previous successes with synthetic log generation, we trained a GPT model using CloudTrail logs from a specific incident. This experiment aimed to assess the feasibility of creating accurate synthetic logs that simulate red team activities. The results were promising and aligned with prior experiments involving Azure and Microsoft SharePoint logs.
To enhance the dataset, we tagged each log entry with a sub-technique ID from the MITRE framework. The objective was to determine if the model could generate relevant logs when prompted with a specific MITRE sub-technique ID.
Currently, the dataset includes logs from a single incident, but there are plans to expand it with logs from multiple incidents, each tagged with a MITRE sub-technique ID. This comprehensive approach aims to simulate a diverse range of breaches, providing a robust platform for security teams to evaluate and improve their detectability and response capabilities.
The generation of synthetic logs using advanced language models represents a significant advancement in cybersecurity. By simulating both suspicious events and red team activities, this approach enhances the preparedness and resilience of security teams, ultimately contributing to a more secure enterprise.
Table 2 shows sample training times on a single GPU, including specific parameters and dataset sizes for this experiment.
| # of Layers | # of Heads | Context Size | GPT Size (M) | Tokenizer | Dataset Description | Dataset Length ~ (characters) | Training Time A100 GPU |
| 12 | 12 | 7000 | 120 M | Character | Azure Logs | 39,000,000 | ~45 minutes |
| 6 | 6 | 4000 | 85.2 | Character | Azure Logs | 39,000,000 | ~15 minutes |
| 12 | 12 | 7000 | 120 M | Character | Sharepoint Logs | 4,700,000 | ~15 minutes |
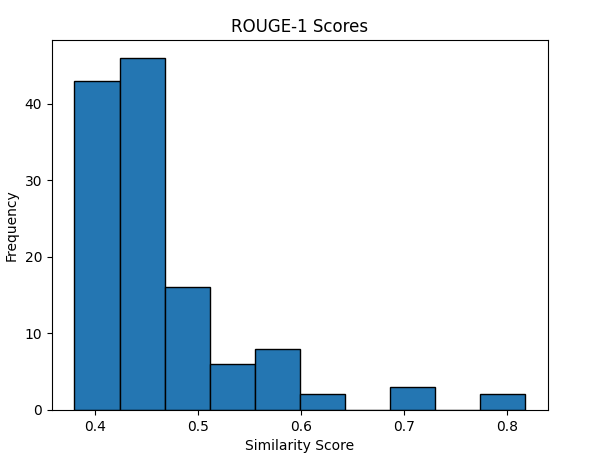
As a sanity check in our experiments, we measured the similarity between the generated and the real logs to make sure identical logs were not being produced (Figures 4 and 5).
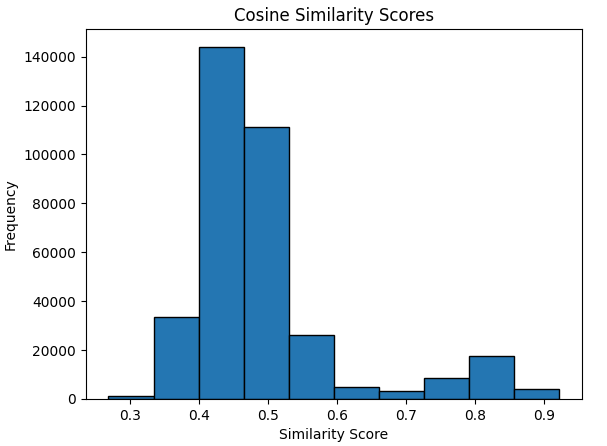
Conclusion
Our research underscores the limitations of general-purpose LLMs in meeting the unique requirements of cybersecurity. This research paves the way for developing cyber foundation models, where models are tailored to process vast and domain-specific datasets. Cyber foundation models excel by learning directly from low-level cybersecurity logs, enabling more precise anomaly detection, cyber threat simulation, and overall security enhancement.
We experimented with smaller models, but it is possible to train larger models with more data to potentially achieve higher adaptability across various cybersecurity tasks. We strongly encourage training language models with your own logs. This enables specialized task handling and also broader application potential.
Adopting these cyber foundation models presents a practical strategy for improving cybersecurity defenses, making your cybersecurity efforts more robust and adaptive. A single GPU may be sufficient to start training a foundation model for a dataset size similar to the ones we used in our experiments. For more data and larger models, use NVIDIA NeMo.
For more information, see the following resources:
- Cyber foundation notebook in the /nv-morpheus GitHub repo
- NVIDIA AI Enterprise
- Security Vulnerability Analysis (AI workflow)
