
Retailers today have access to an abundance of video data provided by cameras and sensors installed in stores. Leveraging computer vision AI applications, retailers and software partners can develop AI applications faster while also delivering greater accuracy. These applications can help retailers:
- Understand in-store customer behavior and buying preference
- Reduce shrinkage
- Notify associates of low or depleted inventory
- Improve merchandising
- Optimize operations
Building and deploying such highly efficient computer vision AI applications at scale poses many challenges. Traditional techniques are time-consuming, requiring intensive development efforts and AI expertise to map all the complex architectures and options. These can include building customized AI models, deploying high-performance video decoding and AI inference pipelines, and generating an insightful analytics dashboard.
NVIDIA’s suite of SDKs helps to simplify this workflow. You can create high-quality video analytics with minimum configuration using the NVIDIA DeepStream SDK, and an easy model training procedure with the NVIDIA TAO Toolkit.
This post provides a tutorial on how to build a sample application that can perform real-time intelligent video analytics (IVA) in the retail domain using NVIDIA DeepStream SDK and NVIDIA TAO Toolkit.
To create an end-to-end retail vision AI application, follow the steps below:
- Use NVIDIA pretrained models for people detection and tracking.
- Customize the computer vision models for the specific retail use case using the NVIDIA TAO Toolkit.
- Develop an NVIDIA DeepStream pipeline for video analysis and streaming inference outputs using Apache Kafka. Kafka is an open-source distributed streaming system used for stream processing, real-time data pipelines, and data integration at scale.
- Set up a Kafka Consumer to store inference data into a database.
- Develop a Django web application to analyze store performance using a variety of metrics.
You can follow along with implementing this sample application using the code on the NVIDIA-AI-IOT/deepstream-retail-analytics GitHub repo.
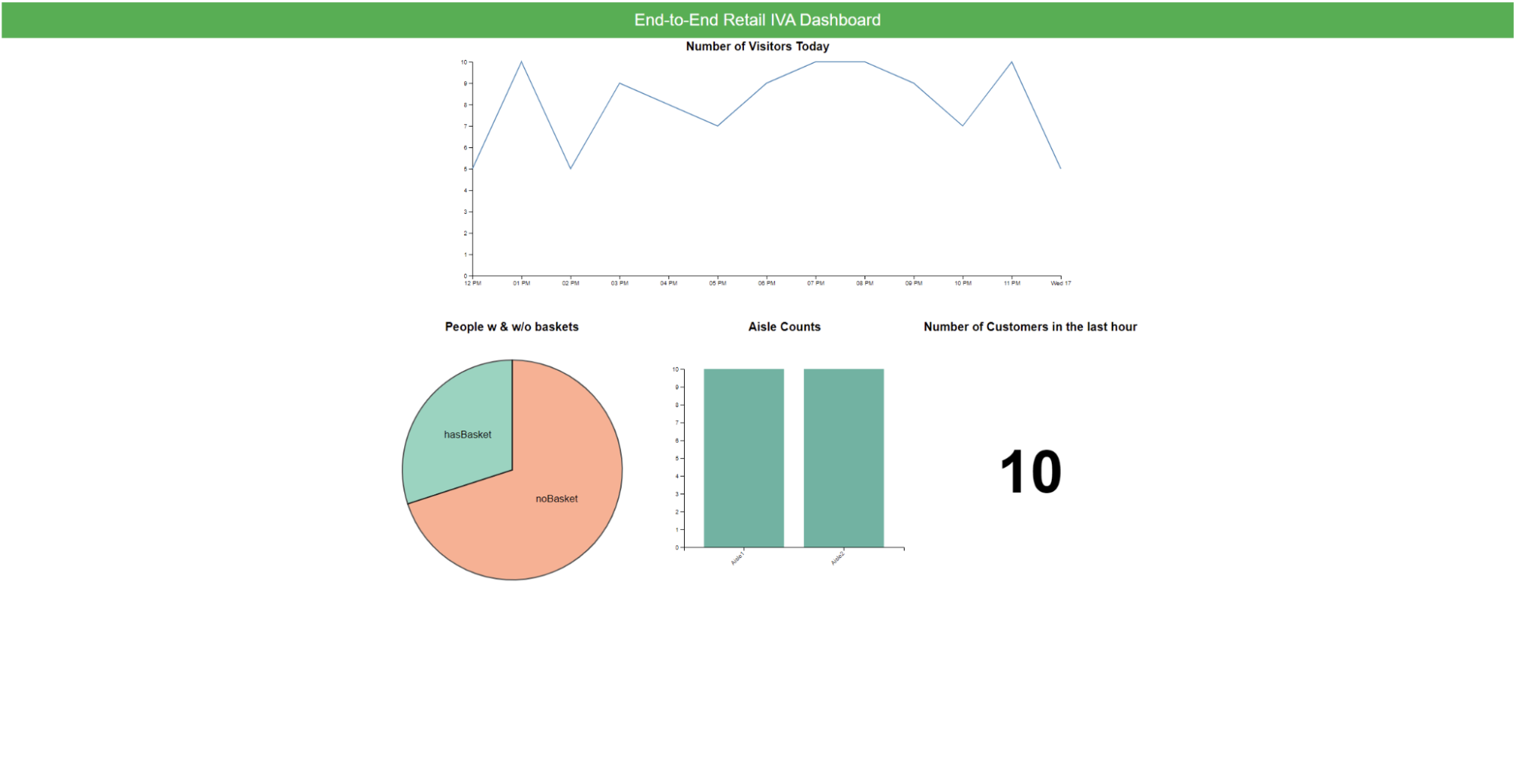
The end product of this sample is a custom dashboard, as shown in Figure 1. The dashboard provides analytical insights such as trends of the store traffic, counts of customers with shopping baskets, aisle occupancy, and more.
Introduction to the application architecture
Before diving into the detailed workflow, this section provides an overview of the tools that will be used to build this project.
NVIDIA DeepStream SDK
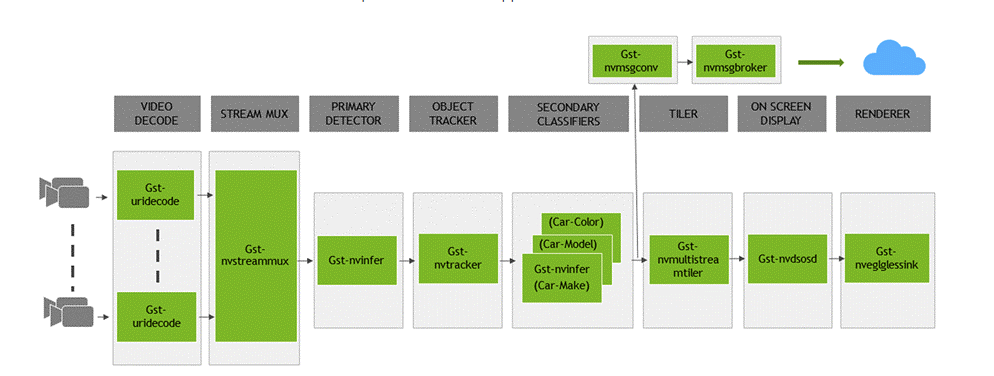
NVIDIA DeepStream SDK is NVIDIA’s streaming analytics toolkit that enables GPU-accelerated video analytics with support for high-performance AI inference across a variety of hardware platforms. DeepStream includes several reference applications to jumpstart development. These reference apps can be easily modified to suit new use cases and are available inside the DeepStream Docker images and at deepstream_reference_apps on GitHub.
This retail vision AI application is built on top of two of the reference applications, deepstream-test4 and deepstream-test5. Figure 2 shows the architecture of a typical DeepStream application.
NVIDIA TAO Toolkit and pretrained models
NVIDIA TAO (Train, Adapt, and Optimize) Toolkit enables fine-tuning a variety of AI pretrained models to new domains. The TAO Toolkit is used in concert with the DeepStream application to perform analyses for unique use cases.
In this project, the model is used to detect whether or not a customer is carrying a shopping basket. DeepStream enables a seamless integration of TAO Toolkit with its existing pipeline without the need for heavy configuration.
Getting started with TAO Toolkit is easy. TAO Toolkit provides complete Jupyter notebooks for model customization for 100+ combinations of CV architectures and backbones. TAO Toolkit also provides a library of task-specific pretrained models for common retail tasks like people detection, pose estimation, action recognition, and more. To get started, see TAO Toolkit Quick Start.
Retail vision AI application workflow
The retail vision AI application architecture (Figure 3) consists of the following stages:
A DeepStream Pipeline with the following configuration:
- Primary Detector: Configure PeopleNet pretrained model from NGC to detect ‘Persons’
- Secondary Detector: Custom classification model trained using the TAO Toolkit for shopping basket detection
- Object Tracker: NvDCF tracker (in the accuracy configuration) to track the movement in the video stream
- Message Converter: Message converter to generate custom Kafka streaming payload from inference data
- Message Broker: Message broker to relay inference data to a Kafka receiver
kSQL Time Series Database: Used to store inference output streams from an edge inference server
Django Web Application: Application to analyze data stored in the kSQL database to generate insights regarding store performance, and serve these metrics as RESTful APIs and a web dashboard
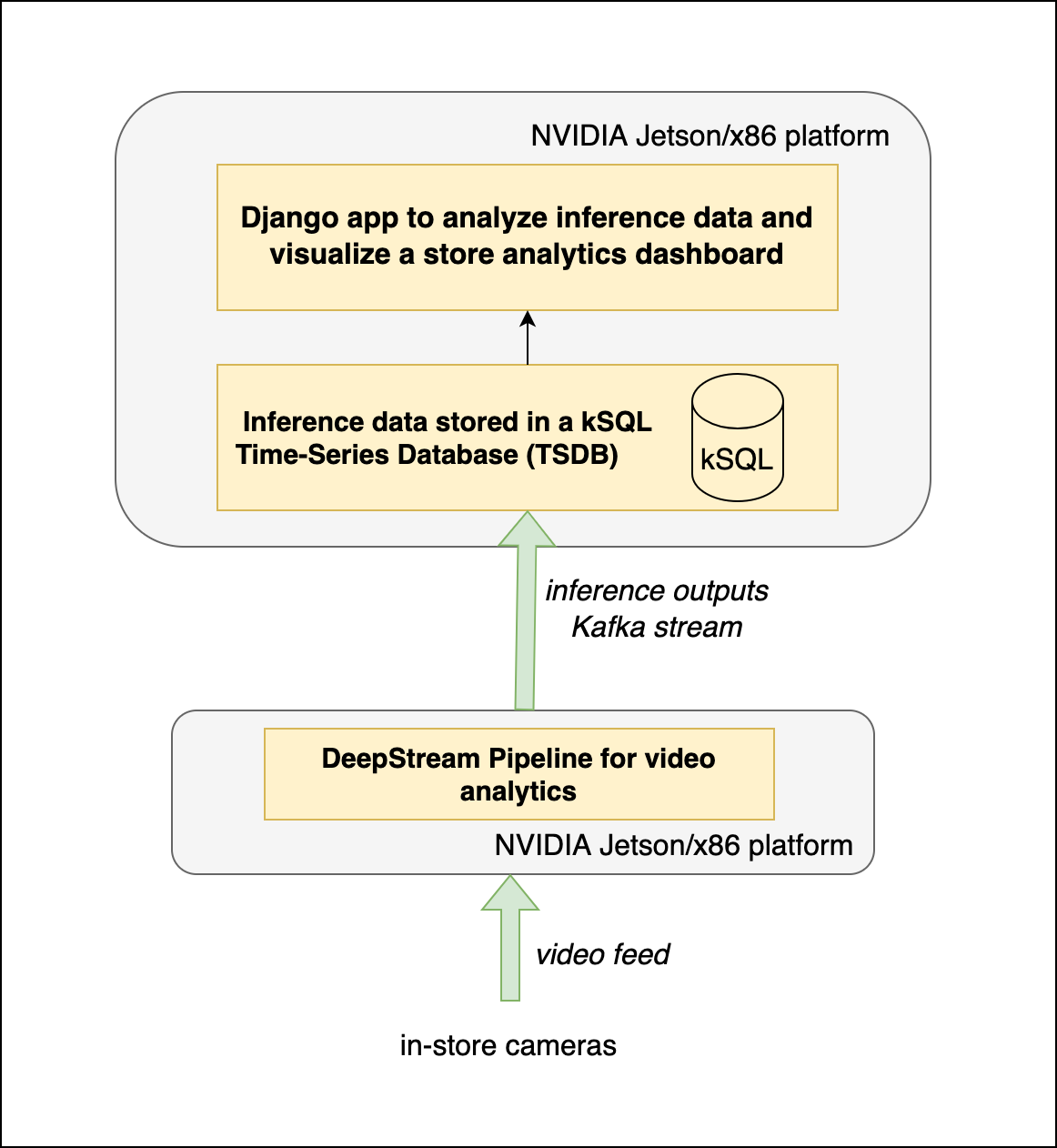
Additionally, this app is built for x86 platforms with an NVIDIA GPU. However, it can be easily deployed on NVIDIA Jetson embedded platforms, such as the NVIDIA Jetson AGX Orin.
The next section walks you through the steps involved in building the application.
Step 1: Building a custom NVIDIA DeepStream pipeline
To build the retail data analytics pipeline, start with the NVIDIA DeepStream reference applications deepstream-test4 and deepstream-test5. Code for the pipeline and a detailed description of the process is available in the deepstream-retail-analytics GitHub repo. We recommend using this post as a walkthrough to the code in the repository.
The deepstream-test4 application is a reference DeepStream pipeline that demonstrates adding custom-detected objects as NVDS_EVENT_MSG_META user metadata and attaching it to the buffer to be published. The deepstream-test5 is an end-to-end app that demonstrates how to use nvmsgconv and nvmsgbroker plugins in multistream pipelines, create NVDS_META_EVENT_MSG type of meta, and stream inference outputs using Kafka and other sink types.
This pipeline also integrates a secondary classifier in addition to the primary object detector, which can be useful for detecting shopper attributes once a person is detected in the retail video analytics application. The test4 application is used to modify the nvmsgconv plugin to include retail analytics attributes. Then, refer to the test5 application for secondary classifiers and streaming data from the pipeline using the nvmsgbroker over a Kafka topic.
Since the first step of the workflow is to identify persons and objects from the video feed, start by using the deepstream-test4 application for primary object detection. This object detection is done on the PeopleNet pretrained model that, by default, takes video input and detects people or their belongings.
For this use case, configure the model to capture only information about people. This can be accomplished easily by storing information only about the subset of frames that contain a person in the dataset.
With the primary person object detection done, use deepstream-test5 to add a secondary object classification model. This object classification shows whether or not a detected person is carrying a basket.
Step 2: Building a custom model for shopping basket detection with NVIDIA TAO Toolkit
This section shows how to use the TAO Toolkit to fine-tune an object classification model and find out whether a person detected in the PeopleNet model is carrying a shopping basket (Figure 4).

To get started, collect and annotate training data from a retail environment for performing object classification. Use the Computer Vision Annotation Tool (CVAT) to annotate persons observed with the following labels:
hasBasket: Person is carrying a basketnoBasket: Person is not carrying a basket
This annotation is stored as a KITTI formatted dataset, where each line corresponds to a frame and thus an object. To make the data compatible for object classification, use the sample ‘kitti_to_classification‘ Python file on GitHub to crop the dataset. You can then perform object classification on it.
Next, use the TAO Toolkit to fine-tune a Resnet34 image classification model to perform classification on the training data. Learn more about the fine-tuning process at deepstream-retail-analytics/tree/main/TAO on GitHub.
After the custom model is created, run inference to validate that the model works as expected.
Step 3: Integrating the Kafka message broker to create a custom frontend dashboard
With the primary object detection and secondary object classification models ready, the DeepStream application needs to relay this inference data to an analytics web server. Use the deepstream-test5 reference application as a template to stream data using Apache Kafka.
Here, a Kafka adapter that is built into DeepStream is used to publish messages to the Kafka message broker. Once the web server receives the Kafka streams from each camera inside a store, these inference output data are stored in a kSQL time-series database.
DeepStream has a default Kafka messaging shared library object that enables users to perform primary object detection and transmit the data seamlessly. This project further modifies this library to include information about the secondary classifier as well. This helps to stream data about shopping basket use inside the store.
The current DeepStream library includes NvDsPersonObject, which is used to define the persons detected in the primary detector. To ensure that the basket detection is mapped to each person uniquely, modify this class to include a hasBasket attribute in addition to the previously present attributes. Find more details at deepstream-retail-analytics/tree/main/nvmsgconv on GitHub.
After modifying the NvDsPersonObject to include basket detection, use the pipeline shown in Figure 5 to ensure the functionality for basket detection works appropriately.
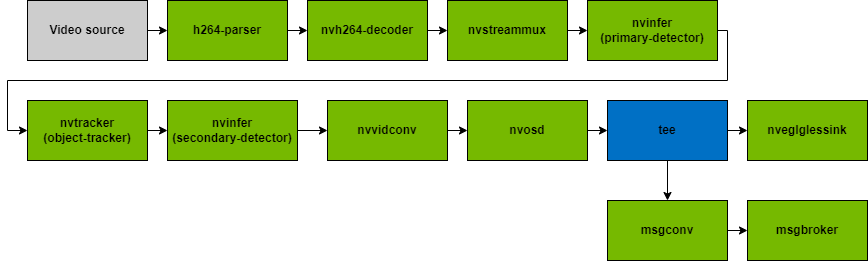
As shown in the application pipeline in Figure 5, object detection and tracking are performed with the help of pgie and sgie. These are part of the nvinfer plugin as the primary and secondary inference engines. With nvtracker, transfer the data to the nvosd plugin. This nvosd plugin is responsible for drawing boxes around the objects that were detected in the previous sections.
Next, this inference data needs to be converted into message payload based on a specific schema that can be later consumed by the Kafka message broker to store and analyze the results. Use the NvDsPersonsObject (generated previously) for the updated payload in the eventmsg_payload file.
Finally, you now have the message payload with the custom schema. Use this to pass it through the Kafka protocol adapter and publish messages that the DeepStream application sends to the Kafka message broker at the specified broker address and topic. At this point, the final message payload is ready.
Now that the DeepStream pipeline is ready, build a web application to store the streaming inference data into a kSQL database. This web app, built using the Django framework, analyzes the inference data to generate metrics regarding store performance discussed earlier. These metrics are available through a RESTful API documented at deepstream-retail-analytics/tree/main/ds-retail-iva-frontend on GitHub.
To demonstrate the API functionality, we built a frontend web dashboard to visualize the results of the analytics server. This dashboard acts as a template for a storewide analytics system.
Results
The previous steps demonstrated how to easily develop an end-to-end retail video analytics pipeline using NVIDIA DeepStream and NVIDIA TAO Toolkit. This pipeline helps retail establishments capitalize on pre-existing video feeds and find insightful information they can use to improve profits.
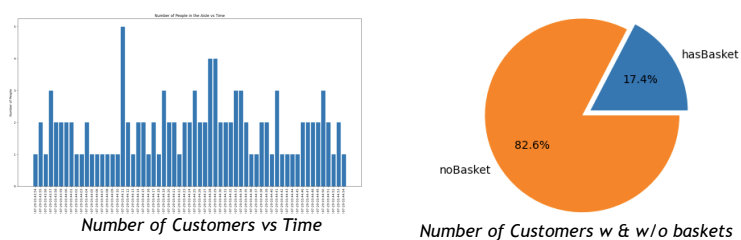
The workflow culminates in an easy-to-use web dashboard to analyze invaluable storewide data in real time. As shown in Figure 1, the dashboard presents the following information:
- Number of store visitors throughout the day
- Information about the proportion of customers shopping with and without baskets
- Visitors counts per store aisle
- Store occupancy heatmaps
- Customer journey visualization
These attributes can be easily amended to include information about specific use cases that are more relevant to each individual store. Stores can use this information to schedule staffing and improve the store layout to maximize efficiency.
For example, Figure 6 shows the overall distribution of customers in the store throughout the day, as well as the ratio of customers with and without baskets, respectively. While this sample application supports only a single camera stream, it can be easily modified to support multiple cameras. Scaling this application to multiple stores is equally easy to do.
The application uniquely detects person 11 carrying the shopping basket by setting the attribute of hasBasket, whereas the other customers who do not carry the basket are marked with noBasket. Additionally, the person 1 with a cardboard box is not identified to have a basket. Thus, the model is robust against false positives, ensuring that it was successfully trained to only pick up relevant information for this use case.
Summary
This post demonstrated an end-to-end process to develop a vision AI application to perform retail analytics using NVIDIA TAO Toolkit and NVIDIA DeepStream SDK. Retail establishments can use the flux of video data they already have and build state-of-the-art video analytics applications. These apps can be deployed in real time and require minimal configuration to get started. In addition, the high customizability of this application ensures that it can be applied to any use case a store might benefit from.
Get started using the sample deepstream-retail-analytics application on GitHub.
