
Humans have an inherent ability to learn novel concepts from only a few samples and generalize these concepts to different situations. Even though today’s machine learning models excel with an abundance of training data on standard recognition tasks, a considerable gap exists between machine-level pattern recognition and human-level concept learning.
Over 50 years ago, M. M. Bongard, a Russian computer scientist, invented a collection of one hundred human-designed visual recognition tasks, now named the Bongard problems (BPs), aiming to narrow the gap. According to Harry Foundalis, BPs enable us to get a glimpse at the foundations of cognition: a set of principles that are as fundamental for cognitive science as Newton’s laws are for physics. Solving them has to follow some fundamental principles of cognition. To date, we’ve yet to see a method capable of solving a substantial portion of the problem set.
The original BP set has been long known in both the cognitive science and AI research community as an inspirational challenge for human-level visual cognition. However, it does not conform to the state-of-the-art machine learning methods because of two limitations:
- The problem solution as a natural language description of underlying concepts limits its broad applicability to learning-based approaches.
- The small size of this problem set makes it hard to digest with data-driven visual recognition techniques.
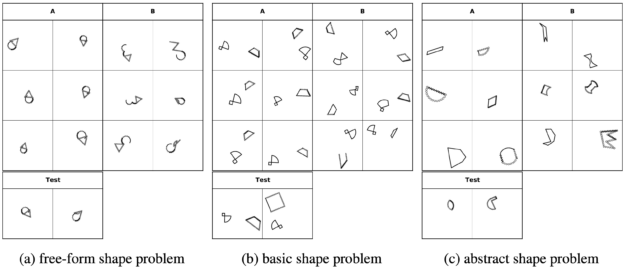
In Figure 1, the free-form shape concept is a sequence of six action strokes forming an ice cream cone-like shape. The basic shape concept is a combination of a fan-like shape and trapezoid. The abstract shape concept is convex. In each problem, set A contains six positive images that satisfy the concept, and set B contains six negative images that violate the concept.
In this post, we introduce Bongard-LOGO, a new benchmark for human-level visual concept learning and reasoning, directly inspired by the design principles behind the BPs. We address the earlier limitations of the original BPs as follows:
- We cast the task as a few-shot concept learning problem where the goal is to classify the unseen test image as positive if it satisfies the underlying concept and as negative otherwise.
- We developed a program-guided shape generation technique to automatically generate tens of thousands of problem instances in action-oriented LOGO language.
In our experiments, both the latest few-shot learning and abstract reasoning models have significantly fallen short of human-level performances on our benchmark. This large performance gap reveals the failure of today’s pattern recognition systems in capturing the core properties of human cognition.
We show that incorporating symbolic information largely improves the overall performance, suggesting the great potential of neuro-symbolic methods on Bongard-LOGO. We believe that our benchmark can inspire more potential research frontiers to move towards building computational architectures for high-level visual cognition.
Bongard-LOGO benchmark
This new benchmark consists of 12Kproblem instances, which belong to three distinct types (Figure 1) based on the concept categories: free-form, basic, or abstract.
- 3.6K free-form shape problems. Each shape is composed of randomly sampled action strokes. The latent concept corresponds to the sequence of action stokes, such as straight lines or zigzagged arcs. Figure 1(a) shows that all images in the positive set form a one-shape concept and share the same sequence of six strokes that none of the images in the negative set possess. To solve these problems, the model must implicitly induce the underlying programs from shape patterns and examine whether test images match the induced programs.
- 4K basic shape problems. The concept corresponds to recognizing the one-shape category or a composition of two shapes presented in 627 human-designed shape categories. The main purpose of these problems is to test the analogy-making perception where, for example, zigzag is an important feature in free-form shape problems but a nuisance in basic shape problems. Figure 1(b) shows that all six images in the positive set have the concept: a combination of a fan-like shape and trapezoid, while all six images in the negative set are other different combinations of two shapes.
- 44.K abstract shape problems. The concept corresponds to more abstract shape attributes and their combinations, such as symmetric, convex, necked, and so on. The purpose of these problems is to test the ability of abstract concept discovery and reasoning. Figure 1(c) shows an example of abstract shape problems, where the underlying concept is convex. Large variations in all convex and concave shapes ensure that the model does not simply memorize some finite shape templates but instead is forced to understand the gist of the convex concept.
Bongard-LOGO captures three core characteristics of human cognition. Figure 2 uses intuitive examples to explain each characteristic.
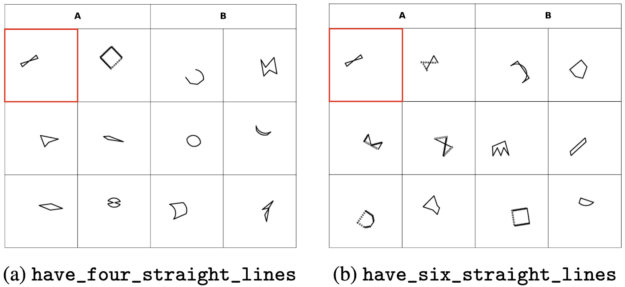
In Figure 2(a), the concept is have_four_straight_lines and for (b), the concept is have_six_straight_lines. The same shape pattern (highlighted in red) has fundamentally opposite interpretations depending on the context: Whether the line segments are seen as continuous when they intersect with each other.
Context-dependent perception
The same geometrical arrangement may have fundamentally different representations for each context in which it arises. For example, the concept in the task of Figure 2(a) is have_four_straight_lines. Straight line segments must be seen as continuous, even when they intersect with another line segment.
This does not happen in the task of Figure 2(b), where intersections must split the line segments to fulfill the underlying concept have_six_straight_lines. The context-dependent perception required by our benchmark is challenging to current pattern recognition models, which are founded on the premise of context-free perception.
Analogy-making perception
Some meaningful structures can be traded off for other meaningful ones to satisfy the concept. We may interpret a zigzag as a straight line, or a set of triangles as an arc, and so on. Figure 1(b) contains a trapezoid concept, even if some trapezoids have no straight lines.
Importantly, the stroke types (zigzagged, circles, and so on) may not be just nuisances, because we strictly distinguish different stroke types for the concepts in many free-form shape problems. A model with analogy-making perception can precisely know when a representation is crucial for the concept and when it must be traded off for another concept.
Perception with a few samples but of infinite vocabulary
Unlike standard few-shot image classification tasks, there is no finite set of standard categories in Bongard-LOGO. Many problems in our benchmark are not dealing with easily categorizable structures (triangles, circles, and so on) for which we happen to have clear descriptions.
For example, we do not know the precise names of the free-form shape in Figure 1(a), but we are still able to easily recognize the concepts. As each free-form shape is an arbitrary composition of randomly sampled action strokes, the space of all possible combinations makes the shape vocabulary size infinite.
Experimental setup
In our experiments, we used several latest deep learning approaches and tested how they behaved in Bongard-LOGO. First, we introduce the following meta-learning methods, with each being state-of-the-art in different meta-learning categories:
- SNAIL: A memory-based method.
- ProtoNet: A metric-based method.
- MetaOptNet: An optimization-based method.
- ANIL: Another optimization-based method.
Because Meta-Baseline is a new competitive baseline in many few-shot classification tasks, we considered its variants:
- Meta-Baseline-SC: We meta-trained the model from scratch.
- Meta-Baseline-MoCo: We first used an unsupervised contrastive learning method, MoCo, to pretrain the backbone model and then applied meta-training.
We also considered the following non-meta-learning baselines for comparison:
- WReN-Bongard: A variant of WReN that was originally designed to encourage reasoning in the Raven-style Progressive Matrices (RPMs).
- CNN-Baseline: A convolutional neural network (CNN) baseline, which casts the task into a conventional binary image classification problem.
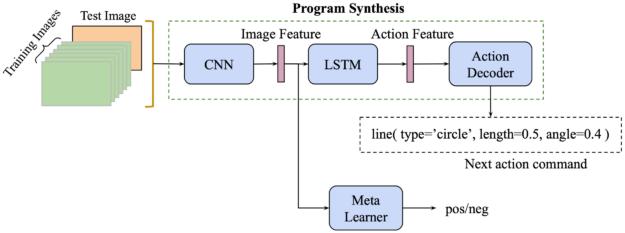
Finally, to show the impact of incorporating symbolic information into neural networks, we have proposed a new model called Meta-Baseline-PS, which stands for Meta-Baseline based on program synthesis. The basic idea is to replace the MoCo pretraining in Meta-Baseline-MoCo with the pretraining of a program synthesis task (Figure 3).
The training of Meta-Baseline-PS is composed of two stages: pretraining the program synthesis module to extract the symbolic-aware image feature and then fine-tuning it by training the meta-learner.
Quantitative results
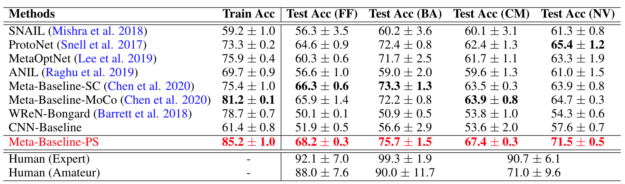
Figure 3 shows the test accuracy (%) on different dataset splits, including free-form shape test set (FF), basic shape test set (BA), combinatorial abstract shape test set (CM), and novel abstract shape test set (NV). For human evaluation, we reported the separate results across two groups of human subjects: Human (Expert) who understands and carefully follows the instructions, and Human (Amateur) who quickly skims the instructions or does not follow them at all. The chance performance is 50%.
You can see that there exists a significant gap between the Human (Expert) performance and the best model performance across all different test sets. Specifically, Human (Expert) can easily achieve nearly perfect performances (>90% test accuracy) on all the test sets, while the best performing models only achieve around or less than 70% accuracy. The low performance of these deep learning models implies their failure to capture the core human cognition properties, as we described earlier.
Furthermore, you can see that Meta-Baseline-PS largely outperforms all the baselines. It demonstrates that incorporating symbolic information into neural networks improves the overall performance, confirming the great potential of neuro-symbolic methods on tackling the Bongard-LOGO benchmark. However, by realizing that there is still a large gap between Meta-Baseline-PS and human performance, we leave the exploration of more advanced neuro-symbolic approaches to tackle the challenge of our benchmark, as the future work.
Conclusion
In this post, we introduced a new benchmark called Bongard-LOGO to demonstrate the chasm between human visual cognition and computerized pattern recognition. Bongard-LOGO is digestible by data-driven learning methods to date, which demand a new form of human-like cognition that is context-dependent, analogical, and few-shot of infinite vocabulary.
Our empirical evaluation of the state-of-the-art visual recognition methods indicates a considerable gap between machine and human performance on this benchmark. By incorporating symbolic information into neural networks, we’ve shown the great potential of neuro-symbolic methods in tackling the Bongard-LOGO challenge.
For more information, see the research paper, Bongard-LOGO: A New Benchmark for Human-Level Concept Learning and Reasoning, Bongard-LOGO website, or slides.
