
NVIDIA GPUs have enormous compute power and typically must be fed data at high speed to deploy that power. That is possible, in principle, because GPUs also have high memory bandwidth, but sometimes they need your help to saturate that bandwidth.
In this post, we examine one specific method to accomplish that: prefetching. We explain the circumstances under which prefetching can be expected to work well, and how to find out whether these circumstances apply to your workload.
Context
NVIDIA GPUs derive their power from massive parallelism. Many warps of 32 threads can be placed on a streaming multiprocessor (SM), awaiting their turn to execute. When one warp is stalled for whatever reason, the warp scheduler switches to another with zero overhead, making sure the SM always has work to do.
On the high-performance NVIDIA Ampere Architecture A100 GPU, up to 64 active warps can share an SM, each with its own resources. On top of that, A100 has 108 SMs that can all execute warp instructions simultaneously.
Most instructions must operate on data, and that data almost always originates in the device memory (DRAM) attached to the GPU. One of the main reasons why even the abundance of warps on an SM can run out of work is because they are waiting for data to arrive from memory.
If this happens, and the bandwidth to memory is not fully utilized, it may be possible to reorganize the program to improve memory access and reduce warp stalls, which in turn makes the program complete faster. This is called latency hiding.
Prefetching
A technology commonly supported in hardware on CPUs is called prefetching. The CPU sees a stream of requests from memory arriving, figures out the pattern, and starts fetching data before it is actually needed. While that data travels to the execution units of the CPU, other instructions can be executed, effectively hiding the travel costs (memory latency).
Prefetching is a useful technique but expensive in terms of silicon area on the chip. These costs would be even higher, relatively speaking, on a GPU, which has many more execution units than the CPU. Instead, the GPU uses excess warps to hide memory latency. When that is not enough, you may employ prefetching in software. It follows the same principle as hardware-supported prefetching but requires explicit instructions to fetch the data.
To determine if this technique can help your program run faster, use a GPU profiling tool such as NVIDIA Nsight Compute to check the following:
- Confirm that not all memory bandwidth is being used.
- Confirm the main reason warps are blocked is Stall Long Scoreboard, which means that the SMs are waiting for data from DRAM.
- Confirm that these stalls are concentrated in sizeable loops whose iterations do not depend on each other.
Unrolling
Consider the simplest possible optimization of such a loop, called unrolling. If the loop is short enough, you can tell the compiler to unroll it completely and the iterations are expanded explicitly. Because the iterations are independent, the compiler can issue all requests for data (“loads”) upfront, provided that it assigns distinct registers to each load.
These requests can be overlapped with each other, so that the whole set of loads experiences only a single memory latency, not the sum of all individual latencies. Even better, part of the single latency is hidden by the succession of load instructions itself. This is a near-optimal situation, but it may require a lot of registers to receive the results of the loads.
If the loop is too long, it could be unrolled partially. In that case, batches of iterations are expanded, and then you follow the same general strategy as before. Work on your part is minimal (but you may not be that lucky).
If the loop contains many other instructions whose operands need to be stored in registers, even just partial unrolling may not be an option. In that case, and after you have confirmed that the earlier conditions are satisfied, you must make some decisions based on further information.
Prefetching means bringing data closer to the SMs’ execution units. Registers are closest of all. If enough are available, which you can find out using the Nsight Compute occupancy view, you can prefetch directly into registers.
Consider the following loop, where array arr is stored in global memory (DRAM). It implicitly assumes that just a single, one-dimensional thread block is being used, which is not the case for the motivating application from which it was derived. However, it reduces code clutter and does not change the argument.
In all code examples in this post, uppercase variables are compile-time constants. BLOCKDIMX assumes the value of the predefined variable blockDim.x. For some purposes, it must be a constant known at compile time whereas for other purposes, it is useful for avoiding computations at run time.
for (i=threadIdx.x; i<imax; i+= BLOCKDIMX) {
double locvar = arr[i];
<lots of instructions using locvar, for example, transcendentals>
}
Imagine that you have eight registers to spare for prefetching. This is a tuning parameter. The following code fetches four double-precision values occupying eight 4-byte registers at the start of each fourth iteration and uses them one by one, until the batch is depleted, at which time you fetch a new batch.
To keep track of the batches, introduce a counter (ctr) that increments with each successive iteration executed by a thread. For convenience, assume that the number of iterations per thread is divisible by 4.
double v0, v1, v2, v3;
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) {
ctr_mod = ctr%4;
if (ctr_mod==0) { // only fill the buffer each 4th iteration
v0=arr[i+0* BLOCKDIMX];
v1=arr[i+1* BLOCKDIMX];
v2=arr[i+2* BLOCKDIMX];
v3=arr[i+3* BLOCKDIMX];
}
switch (ctr_mod) { // pull one value out of the prefetched batch
case 0: locvar = v0; break;
case 1: locvar = v1; break;
case 2: locvar = v2; break;
case 3: locvar = v3; break;
}
<lots of instructions using locvar, for example, transcendentals>
}
Typically, the more values can be prefetched, the more effective the method is. While the preceding example is not complex, it is a little cumbersome. If the number of prefetched values (PDIST, or prefetch distance) changes, you have to add or delete lines of code.
It is easier to store the prefetched values in shared memory, because you can use array notation and vary the prefetch distance without any effort. However, shared memory is not as close to the execution units as registers. It requires an extra instruction to move the data from there into a register when it is ready for use. For convenience, we introduce macro vsmem to simplify indexing the array in shared memory:
#define vsmem(index) v[index+PDIST*threadIdx.x]
__shared__ double v[PDIST* BLOCKDIMX];
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) {
ctr_mod = ctr%PDIST;
if (ctr_mod==0) {
for (k=0; k<PDIST; ++k) vsmem(k) = arr[i+k* BLOCKDIMX];
}
locvar = vsmem(ctr_mod);
<more instructions using locvar, for example, transcendentals>
}
Instead of prefetching in batches, you can also do a “rolling” prefetch. In that case, you fill the prefetch buffer before entering the main loop and subsequently prefetch exactly one value from memory during each loop iteration, to be used PDIST iterations later. The next example implements rolling prefetching, using array notation and shared memory.
__shared__ double v[PDIST* BLOCKDIMX];
for (k=0; k<PDIST; ++k) vsmem(k) = arr[threadIdx.x+k* BLOCKDIMX];
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) {
ctr_mod= ctr%PDIST;
locvar = vsmem(ctr_mod);
if ( i<imax-PDIST* BLOCKDIMX) vsmem(ctr_mod) = arr[i+PDIST* BLOCKDIMX];
<more instructions using locvar, for example, transcendentals>
}
Contrary to the batched method, the rolling prefetch does not suffer anymore memory latencies during the execution of the main loop for a sufficiently large prefetch distance. It also uses the same amount of shared memory or register resources, so it would appear to be preferred. However, a subtle issue may limit its effectiveness.
A synchronization within the loop—for example, syncthreads—constitutes a memory fence and forces the loading of arr to complete at that point within the same iteration, not PDIST iterations later. The fix is to use asynchronous loads into shared memory, the simplest version of which is explained in the Pipeline interface section of the CUDA programmer guide. These asynchronous loads do not need to complete at a synchronization point, but only when they are explicitly waited on.
Here’s the corresponding code:
#include <cuda_pipeline_primitives.h>
__shared__ double v[PDIST* BLOCKDIMX];
for (k=0; k<PDIST; ++k) { // fill the prefetch buffer asynchronously
__pipeline_memcpy_async(&vsmem(k), &arr[threadIdx.x+k* BLOCKDIMX], 8);
__pipeline_commit();
}
for (i=threadIdx.x, ctr=0; i<imax; i+= BLOCKDIMX, ctr++) {
__pipeline_wait_prior(PDIST-1); //wait on needed prefetch value
ctr_mod= ctr%PDIST;
locvar = vsmem(ctr_mod);
if ( i<imax-PDIST* BLOCKDIMX) { // prefetch one new value
__pipeline_memcpy_async(&vsmem(ctr_mod), &arr[i+PDIST* BLOCKDIMX], 8);
__pipeline_commit();
}
<more instructions using locvar, for example, transcendentals>
}
As each __pipeline_wait_prior instruction must be matched by a __pipeline_commit instruction, we put the latter inside the loop that prefills the prefetch buffer, before entering the main computational loop, to keep bookkeeping of matching instruction pairs simple.
Performance results
Figure 1 shows, for various prefetch distances, the performance improvement of a kernel taken from a financial application under the five algorithmic variations described earlier.
- Batched prefetch into registers (scalar batched)
- Batched prefetch into shared memory (smem batched)
- Rolling prefetch into registers (scalar rolling)
- Rolling prefetch into shared memory (smem rolling)
- Rolling prefetch into shared memory using asynchronous memory copies (smem rolling async)
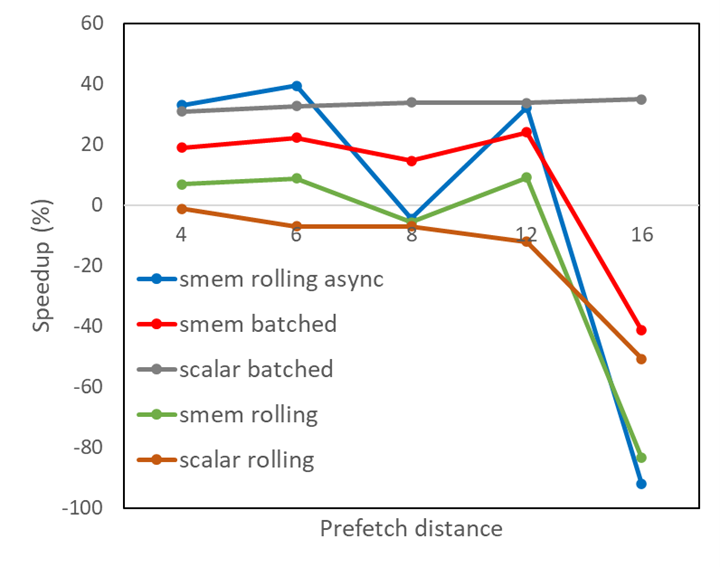
Clearly, the rolling prefetching into shared memory with asynchronous memory copies gives good benefit, but it is uneven as the prefetch buffer size grows.
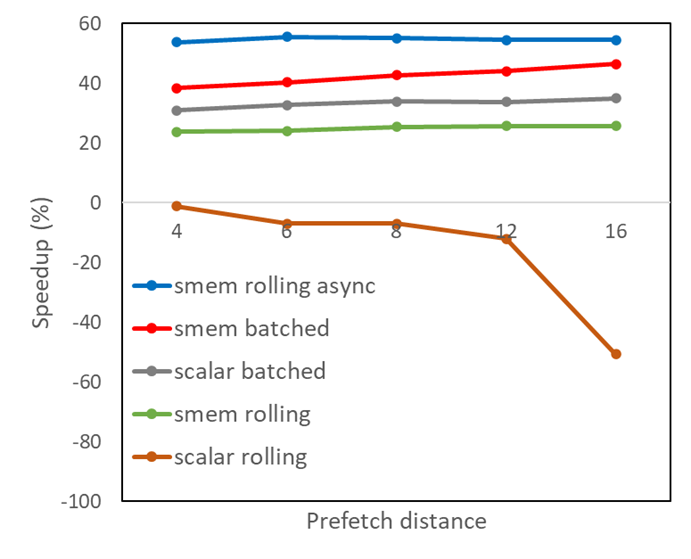
A closer inspection of the results, using Nsight Compute, shows that bank conflicts occur in shared memory, which cause a warp worth of asynchronous loads to be split into more successive memory requests than strictly necessary. The classical optimization approach of padding the array size in shared memory to avoid bad strides works in this case. The value of PADDING is chosen such that the sum of PDIST and PADDING equals a power of two plus 1. Apply it to all variations that use shared memory:
#define vsmem(index) v[index+(PDIST+PADDING)*threadIdx.x]
This leads to the improved shared memory results shown in Figure 2. A prefetch distance of just 6, combined with asynchronous memory copies in a rolling fashion, is sufficient to obtain optimal performance at almost 60% speedup over the original version of the code. We could actually have arrived at this performance improvement without resorting to padding by changing the indexing scheme of the array in shared memory, which is left as an exercise for the reader.
A variation of prefetching not yet discussed moves data from global memory to the L2 cache, which may be useful if space in shared memory is too small to hold all data eligible for prefetching. This type of prefetching is not directly accessible in CUDA and requires programming at the lower PTX level.
Summary
In this post, we showed you examples of localized changes to source code that may speed up memory accesses. These do not change the amount of data being moved from memory to the SMs, only their timing. You may be able to optimize more by rearranging memory accesses such that data is reused many times after it arrives on the SM.